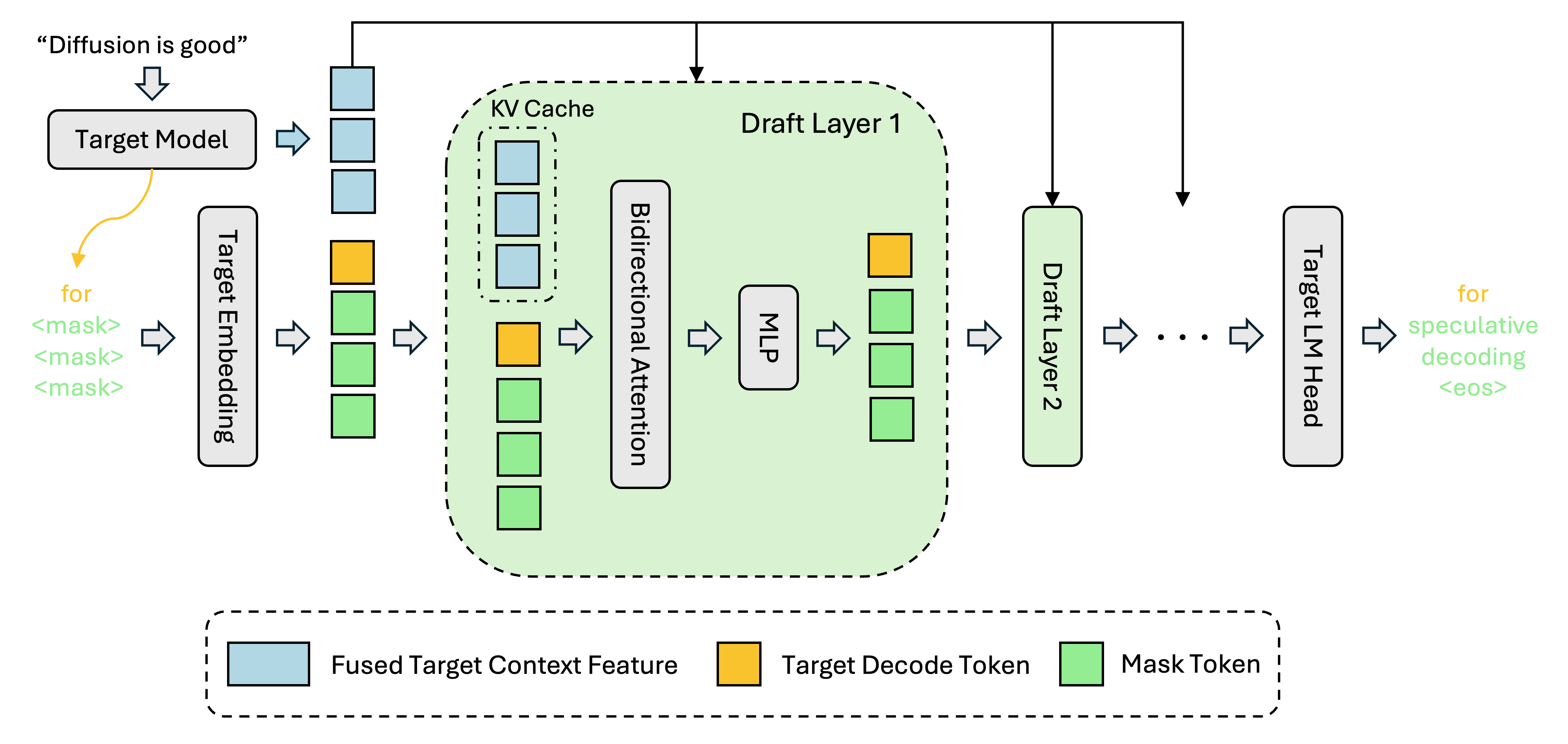
DFlash is a lightweight block diffusion model designed for speculative decoding. It enables efficient and high-quality parallel drafting.
DFlash_demo.mp4
| Model | DFlash Draft |
|---|---|
| Kimi-K2.5 (Preview) | z-lab/Kimi-K2.5-DFlash |
| Qwen3.5-4B | z-lab/Qwen3.5-4B-DFlash |
| Qwen3.5-9B | z-lab/Qwen3.5-9B-DFlash |
| Qwen3.5-27B | z-lab/Qwen3.5-27B-DFlash |
| Qwen3.5-35B-A3B | z-lab/Qwen3.5-35B-A3B-DFlash |
| Qwen3-Coder-Next | z-lab/Qwen3-Coder-Next-DFlash |
| Qwen3-Coder-30B-A3B | z-lab/Qwen3-Coder-30B-A3B-DFlash |
| gpt-oss-20b | z-lab/gpt-oss-20b-DFlash |
| gpt-oss-120b | z-lab/gpt-oss-120b-DFlash |
| Qwen3-4B | z-lab/Qwen3-4B-DFlash-b16 |
| Qwen3-8B | z-lab/Qwen3-8B-DFlash-b16 |
| Llama-3.1-8B-Instruct | z-lab/LLaMA3.1-8B-Instruct-DFlash-UltraChat |
| Qwen3.5-122B-A10B | Coming soon |
| Qwen3.5-397B-A17B | Coming soon |
| GLM-5.1 | Coming soon |
Feel free to open a GitHub issue to request support for additional models. We will also open-source the training recipe soon, so you can train your own DFlash draft model to accelerate any LLM.
Use a separate virtual environment for each to avoid conflict.
| Backend | Install command |
|---|---|
| Transformers | uv pip install -e . |
| SGLang | uv pip install -e ".[sglang]" |
| vLLM | See below |
vLLM: DFlash support requires the nightly build:
uv pip install -e ".[vllm]"
uv pip install -U vllm --torch-backend=auto --extra-index-url https://wheels.vllm.ai/nightlyvllm serve Qwen/Qwen3.5-27B \
--speculative-config '{"method": "dflash", "model": "z-lab/Qwen3.5-27B-DFlash", "num_speculative_tokens": 15}' \
--attention-backend flash_attn \
--max-num-batched-tokens 32768export SGLANG_ALLOW_OVERWRITE_LONGER_CONTEXT_LEN=1
# Optional: enable schedule overlapping (experimental, may not be stable)
# export SGLANG_ENABLE_SPEC_V2=1
# export SGLANG_ENABLE_DFLASH_SPEC_V2=1
# export SGLANG_ENABLE_OVERLAP_PLAN_STREAM=1
python -m sglang.launch_server \
--model-path Qwen/Qwen3.5-35B-A3B \
--speculative-algorithm DFLASH \
--speculative-draft-model-path z-lab/Qwen3.5-35B-A3B-DFlash \
--speculative-num-draft-tokens 16 \
--tp-size 1 \
--attention-backend trtllm_mha \
--speculative-draft-attention-backend fa4 \
--mem-fraction-static 0.75 \
--mamba-scheduler-strategy extra_buffer \
--trust-remote-codeOnly Qwen3 and LLaMA-3.1 models support the Transformers backend.
from transformers import AutoModel, AutoModelForCausalLM, AutoTokenizer
draft = AutoModel.from_pretrained("z-lab/Qwen3-8B-DFlash-b16", trust_remote_code=True, dtype="auto", device_map="cuda:0").eval()
target = AutoModelForCausalLM.from_pretrained("Qwen/Qwen3-8B", dtype="auto", device_map="cuda:0").eval()
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen3-8B")
messages = [{"role": "user", "content": "How many positive whole-number divisors does 196 have?"}]
input_ids = tokenizer.apply_chat_template(messages, return_tensors="pt", add_generation_prompt=True, enable_thinking=False).to(draft.device)
output = draft.spec_generate(input_ids=input_ids, max_new_tokens=2048, temperature=0.0, target=target, stop_token_ids=[tokenizer.eos_token_id])
print(tokenizer.decode(output[0], skip_special_tokens=False))All benchmarks share the same datasets (gsm8k, math500, humaneval, mbpp, mt-bench). Datasets are automatically downloaded and cached as JSONL in cache/ on first run.
vLLM:
python -m dflash.benchmark --backend vllm \
--base-url http://127.0.0.1:8000 --model Qwen/Qwen3.5-27B \
--dataset gsm8k --num-prompts 128 --concurrency 1 --enable-thinkingSGLang:
python -m dflash.benchmark --backend sglang \
--base-url http://127.0.0.1:30000 --model Qwen/Qwen3.5-35B-A3B \
--dataset gsm8k --num-prompts 128 --concurrency 1 --enable-thinkingTransformers (Qwen3 and LLaMA only):
torchrun --nproc_per_node=8 -m dflash.benchmark --backend transformers \
--model Qwen/Qwen3-8B --draft-model z-lab/Qwen3-8B-DFlash-b16 \
--dataset gsm8k --max-samples 128Huge thanks to @dcw02, @gongy, and the team at @modal-labs for their fast, high-quality support in bringing DFlash to SGLang. And huge thanks as well to @benchislett at NVIDIA for his work in bringing DFlash to vLLM and helping make it available to the broader serving community.
If you find DFlash useful, please cite our work. To share feedback on DFlash or request new model support, please fill out this form: DFlash Feedback.
@article{chen2026dflash,
title = {{DFlash: Block Diffusion for Flash Speculative Decoding}},
author = {Chen, Jian and Liang, Yesheng and Liu, Zhijian},
journal = {arXiv preprint arXiv:2602.06036},
year = {2026}
}