Refernce for Rust ml framework
There is a performance improvement of 5% to 10%.
5.1818~5.9137ms => 4.7552~5.0662ms
5.4166~6.1707ms => 5.1834~5.4955ms
m=4096*4 n=4096 k=4096 dtype=bfloat16
hardware: 4090d
Recap: The performance of cubecl is not very stable. In the best case, its performance exceeds candle.
| language | method | cost |
|---|---|---|
| rust | cudarc+cublas | 3.5092ms |
| cpp | cublas | 3.5075ms |
| language | method | cost |
|---|---|---|
| rust | candle | 3.5458ms |
| rust | cubecl | 5.1818~5.9137ms |
| python | compile | 3.5344ms |
| python | raw | 3.5300ms |
| language | method | cost |
|---|---|---|
| rust | candle | 5.7466ms |
| rust | cubecl | 5.4166~6.1707ms |
| python | compile | 3.9381ms |
| python | raw | 3.9343ms |
use matrix shape opt for cache line
A*B + C
A.shape: 235*256 x 4*256
B.shape: 4*256 x 5*256
C.shape: 1 x 5 * 256
| framework | 4090d |
|---|---|
| torch | 1.78ms |
| torch+compile | 1.37ms |
| burn-tch | 2.10ms |
| burn-cubecl | 2.30ms |
reuse device for rust ml; use non-compile mode for pytorch
| framework | 4090d |
|---|---|
| torch | 1.22ms |
| torch+compile | 1.01ms |
| candle | 11.9ms |
| burn-tch | 3.52ms |
| burn-cubecl | 1.56ms |
cubecl don't use the new hardware gemm instruction
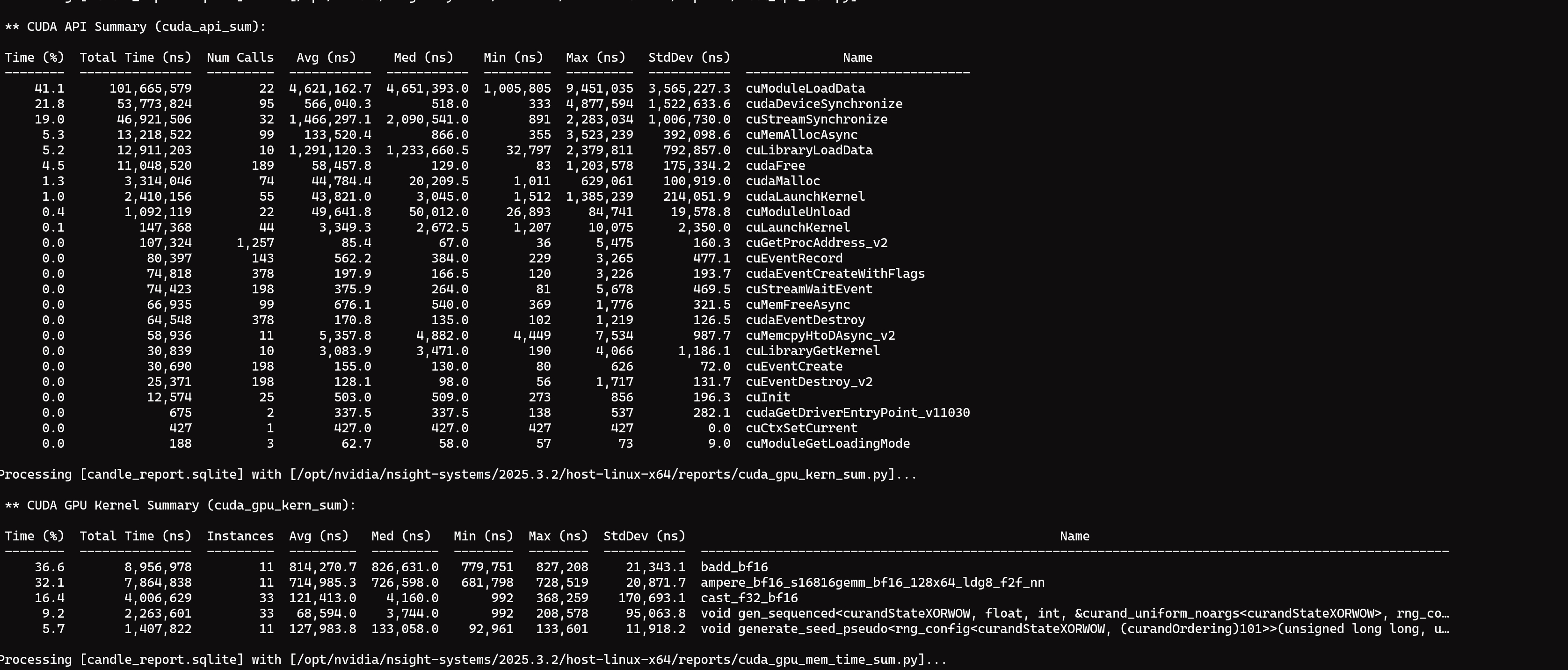
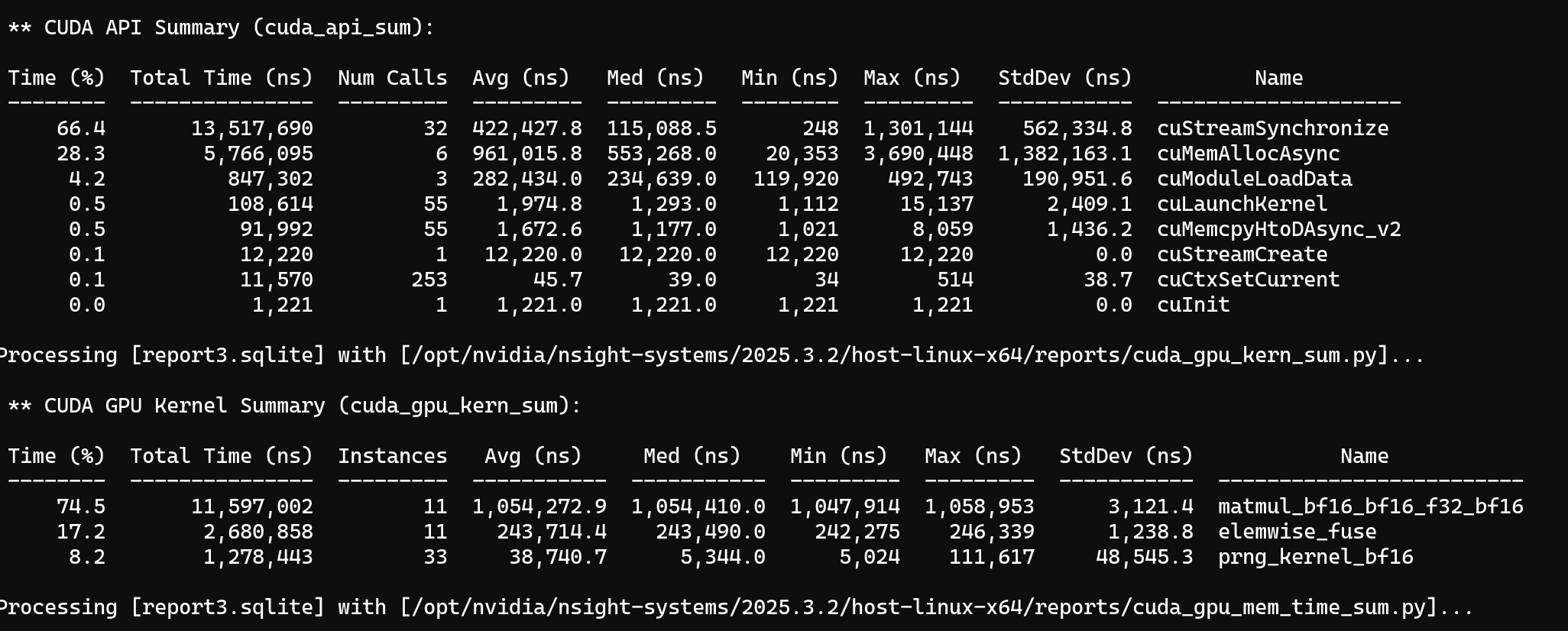
add explicit cuda synchronize in bench loop, candle and burn-cubecl differences between the results before and after is not significant, but the time consumption of PyTorch has suddenly increased to 2.68ms
| framework | 4090d |
|---|---|
| torch+compile | 0.90ms |
| candle | 16.4ms |
| burn-cubecl | 1.46ms |
use bf16 floating point number
| framework | 4090d |
|---|---|
| torch+compile | 0.048ms |
| candle | 16.3ms |
| burn-cubecl | 1.51ms |
use f32 floating point number
| framework | 4090d |
|---|---|
| torch+compile | 0.048ms |
| candle | 18.9ms |
| burn-cubecl | 2.95ms |