[SPARK-28510][SQL] Implement Spark's own GetFunctionsOperation#25252
[SPARK-28510][SQL] Implement Spark's own GetFunctionsOperation#25252wangyum wants to merge 7 commits into
Conversation
| val functionPattern = CLIServiceUtils.patternToRegex(functionName) | ||
| if ((null == catalogName || "".equals(catalogName)) | ||
| && (null == schemaName || "".equals(schemaName))) { | ||
| catalog.listFunctions(catalog.getCurrentDatabase, functionPattern).foreach { |
There was a problem hiding this comment.
Actually, I'm confused about this code. Maybe it should be:
val functionPattern = CLIServiceUtils.patternToRegex(functionName)
matchingDbs.foreach { schema =>
catalog.listFunctions(catalog.getCurrentDatabase, functionPattern).foreach {
case (functionIdentifier, _) =>
val rowData = Array[AnyRef](
DEFAULT_HIVE_CATALOG, // FUNCTION_CAT
schema, // FUNCTION_SCHEM
functionIdentifier.funcName, // FUNCTION_NAME
"", // REMARKS
DatabaseMetaData.functionResultUnknown.asInstanceOf[AnyRef], // FUNCTION_TYPE
"") // SPECIFIC_NAME
rowSet.addRow(rowData);
}But it's the logic of Hive: https://github.com/apache/hive/blob/rel/release-3.1.1/service/src/java/org/apache/hive/service/cli/operation/GetFunctionsOperation.java#L101-L119
There was a problem hiding this comment.
I think we should cover the case of functions that don't have a schema (null) which is basically what Hive's implementation seems to do, as well as the functions associated with a given schema which is what your code snippet above seems to do. Could you combine both?
There was a problem hiding this comment.
May be we do not need to care about catalog:
https://github.com/pgjdbc/pgjdbc/blob/17c4bcfb59e846c593093752f2e30dd97bb4b338/pgjdbc/src/main/java/org/postgresql/jdbc/PgDatabaseMetaData.java#L2612-L2649
| null, // FUNCTION_SCHEM | ||
| functionIdentifier.funcName, // FUNCTION_NAME | ||
| "", // REMARKS | ||
| DatabaseMetaData.functionResultUnknown.asInstanceOf[AnyRef], // FUNCTION_TYPE |
There was a problem hiding this comment.
We do not support FUNCTION_TYPE now. Set it to Unknown:
// java.sql.DatabaseMetaData
/**
* Indicates that it is not known whether the function returns
* a result or a table.
* <P>
* A possible value for column <code>FUNCTION_TYPE</code> in the
* <code>ResultSet</code> object returned by the method
* <code>getFunctions</code>.
* @since 1.6
*/
int functionResultUnknown = 0;
/**
* Indicates that the function does not return a table.
* <P>
* A possible value for column <code>FUNCTION_TYPE</code> in the
* <code>ResultSet</code> object returned by the method
* <code>getFunctions</code>.
* @since 1.6
*/
int functionNoTable = 1;
/**
* Indicates that the function returns a table.
* <P>
* A possible value for column <code>FUNCTION_TYPE</code> in the
* <code>ResultSet</code> object returned by the method
* <code>getFunctions</code>.
* @since 1.6
*/
int functionReturnsTable = 2;|
Test build #108152 has finished for PR 25252 at commit
|
|
retest this please |
|
Test build #108157 has finished for PR 25252 at commit
|
|
cc @bogdanghit |
 bogdanghit
left a comment
bogdanghit
left a comment
There was a problem hiding this comment.
Thanks for working on this, it looks pretty good. A few comments below.
| HiveThriftServer2.listener.onStatementError( | ||
| statementId, e.getMessage, SparkUtils.exceptionString(e)) | ||
| throw e | ||
| } |
There was a problem hiding this comment.
Shouldn't we handle other exceptions too?
There was a problem hiding this comment.
Maybe it should be the same as SparkExecuteStatementOperation:
There was a problem hiding this comment.
Or the same as GetTablesOperation and GetSchemasOperation for the sake of consistency?
There was a problem hiding this comment.
+1 for same as GetTablesOperation and GetSchemasOperation.
| val functionPattern = CLIServiceUtils.patternToRegex(functionName) | ||
| if ((null == catalogName || "".equals(catalogName)) | ||
| && (null == schemaName || "".equals(schemaName))) { | ||
| catalog.listFunctions(catalog.getCurrentDatabase, functionPattern).foreach { |
There was a problem hiding this comment.
I think we should cover the case of functions that don't have a schema (null) which is basically what Hive's implementation seems to do, as well as the functions associated with a given schema which is what your code snippet above seems to do. Could you combine both?
|
Test build #108326 has finished for PR 25252 at commit
|
| statementId, | ||
| parentSession.getUsername) | ||
|
|
||
| try { |
There was a problem hiding this comment.
This looks correct now: retrieve all functions available for all matching schemas.
| functionIdentifier.funcName, // FUNCTION_NAME | ||
| "", // REMARKS | ||
| DatabaseMetaData.functionResultUnknown.asInstanceOf[AnyRef], // FUNCTION_TYPE | ||
| "") |
There was a problem hiding this comment.
This is the function class name which I think we can get through a catalog.getFunction(funcIdentifier).className call.
There was a problem hiding this comment.
Done.
catalog.lookupFunctionInfo(funcIdentifier).getClassName| null, // FUNCTION_CAT | ||
| db, // FUNCTION_SCHEM | ||
| functionIdentifier.funcName, // FUNCTION_NAME | ||
| "", // REMARKS |
There was a problem hiding this comment.
I wonder if we can get the function usage somehow from catalog ...
There was a problem hiding this comment.
Done.
catalog.lookupFunctionInfo(funcIdentifier).getUsage|
Can you also polish a bit the description of the PR?
|
|
Can you add to the description and code on what GetFunctionsOperation actually does as well |
|
Thank you @bogdanghit @tgravescs I have Updated the description. |
| checkResult(metaData.getTableTypes, Seq("TABLE", "VIEW")) | ||
| } | ||
| } | ||
|
|
There was a problem hiding this comment.
Can you add some tests for the usage and the function class name? @wangyum
There was a problem hiding this comment.
I have added some tests:
ssert(rs.getString("REMARKS").startsWith(s"${functionName(i)}("))
assert(rs.getString("SPECIFIC_NAME").startsWith("org.apache.spark.sql.catalyst"))Do you think we need to assert more details?
There was a problem hiding this comment.
Would be nice to run a DESCRIBE function statement and then compare the results.
There was a problem hiding this comment.
|
Our implementation pads the REMARKS field with the function usage - Hive returns an empty string. Edit: Also, please explain each unit test in the description. @wangyum |
| // simply pass the `extended` as `arguments` and an empty string for `examples`. | ||
| this(className, db, name, usage, extended, "", "", "", ""); | ||
| } | ||
|
|
There was a problem hiding this comment.
Do we really need to move this function and change the getters in ExpressionInfo.java?
There was a problem hiding this comment.
I guess this is OK. @juliuszsompolski, what do you think about calling the replaceFunctionName directly inside the getters?
There was a problem hiding this comment.
I think it's a move in a good direction, as it will make it work better (not return nulls, return actual name instead of placeholder) for anyone using ExpressionInfos directly through SessionCatalog.lookupFunctionInfo API directly
cc @gatorsmile, what do you think?
There was a problem hiding this comment.
It's merged. Please rebase this PR. Thanks!
|
Test build #108451 has finished for PR 25252 at commit
|
| statementId, e.getMessage, SparkUtils.exceptionString(e)) | ||
| throw e | ||
| } | ||
| HiveThriftServer2.listener.onStatementFinish(statementId) |
There was a problem hiding this comment.
We also need the onStatementClosed handler like in the other ops.
|
|
||
| withJdbcStatement() { statement => | ||
| val metaData = statement.getConnection.getMetaData | ||
| val rs = metaData.getFunctions(null, "default", "upPer") |
There was a problem hiding this comment.
Thanks for writing all these tests. Was the capital P here intentional?
|
Test build #108514 has finished for PR 25252 at commit
|
|
LGTM |
|
LGTM Thanks! Merged to master. |
| matchingDbs.foreach { db => | ||
| catalog.listFunctions(db, functionPattern).foreach { | ||
| case (funcIdentifier, _) => | ||
| val info = catalog.lookupFunctionInfo(funcIdentifier) |
There was a problem hiding this comment.
@dongjoon-hyun @wangyum hmm... it looks that if it's run for a wildcard schema pattern, all Spark builtin functions from FunctionRegistry are returned for every schema... This makes it return hundreds of thousands of rows for a big catalog with hundreds of schemas.
Should it return builtin function only once, and in-schema functions only for UDFs registered in the catalog?
There was a problem hiding this comment.
@juliuszsompolski and @wangyum . Since this is Apache Spark 3.0 feature, the suggestion sounds like a breaking API change. Is it safe?
|
Hi @dongjoon-hyun @wangyum. I checked this out with DbVisualizer and it is indeed loading the available function set for every schema in the database. I'm attaching two screenshots: After scrolling down: If the there are many schemas, it can take a while for a GetFunctions operation to return and it also creates a poor experience because of the exhaustive and repetitive list of functions returned. This results in hundreds of thousands of rows that slow down the UI. That being said, it doesn't look like a breaking change to me, more like a bug and fixing it would significantly improve UX. WDYT? |
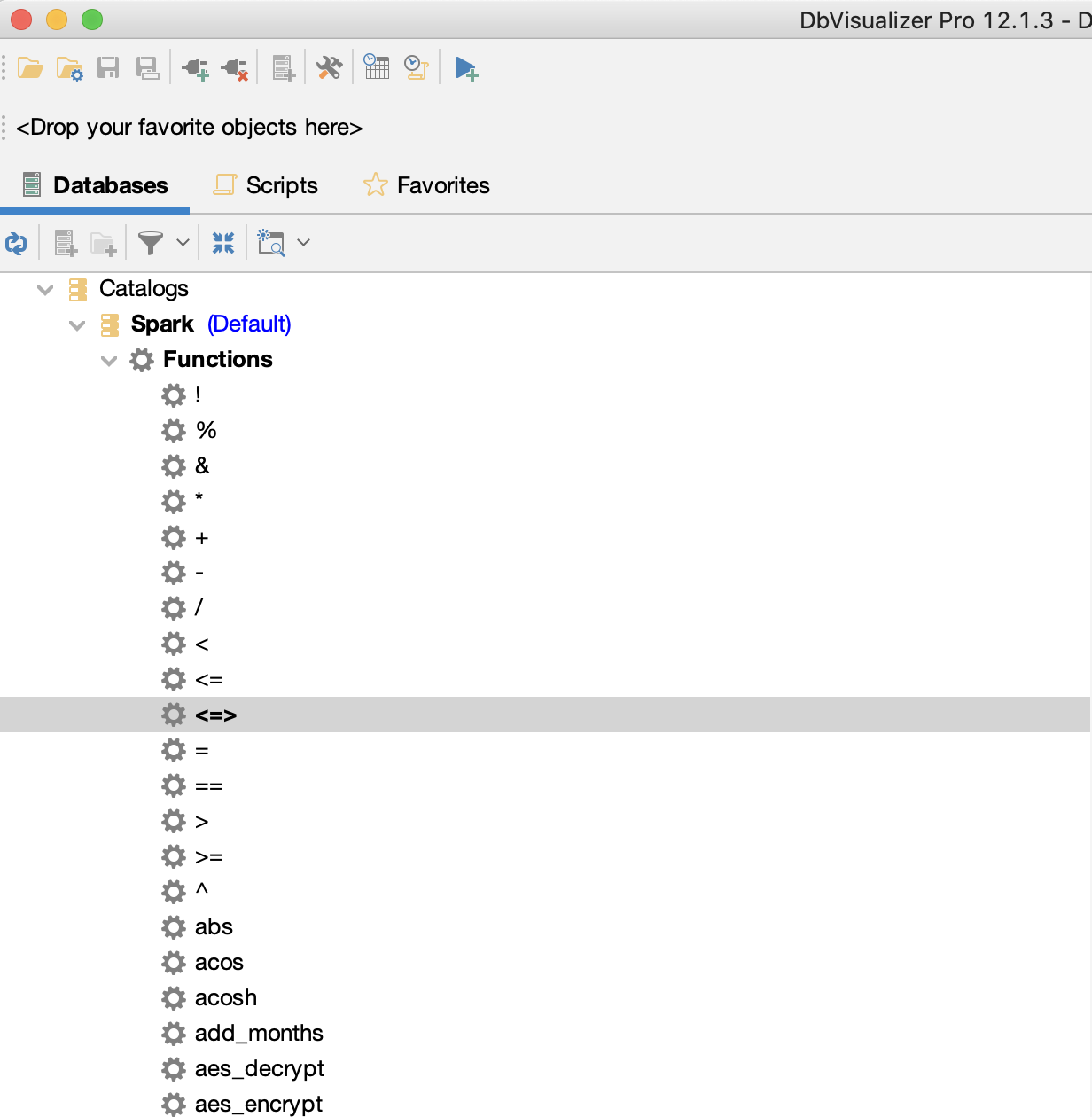
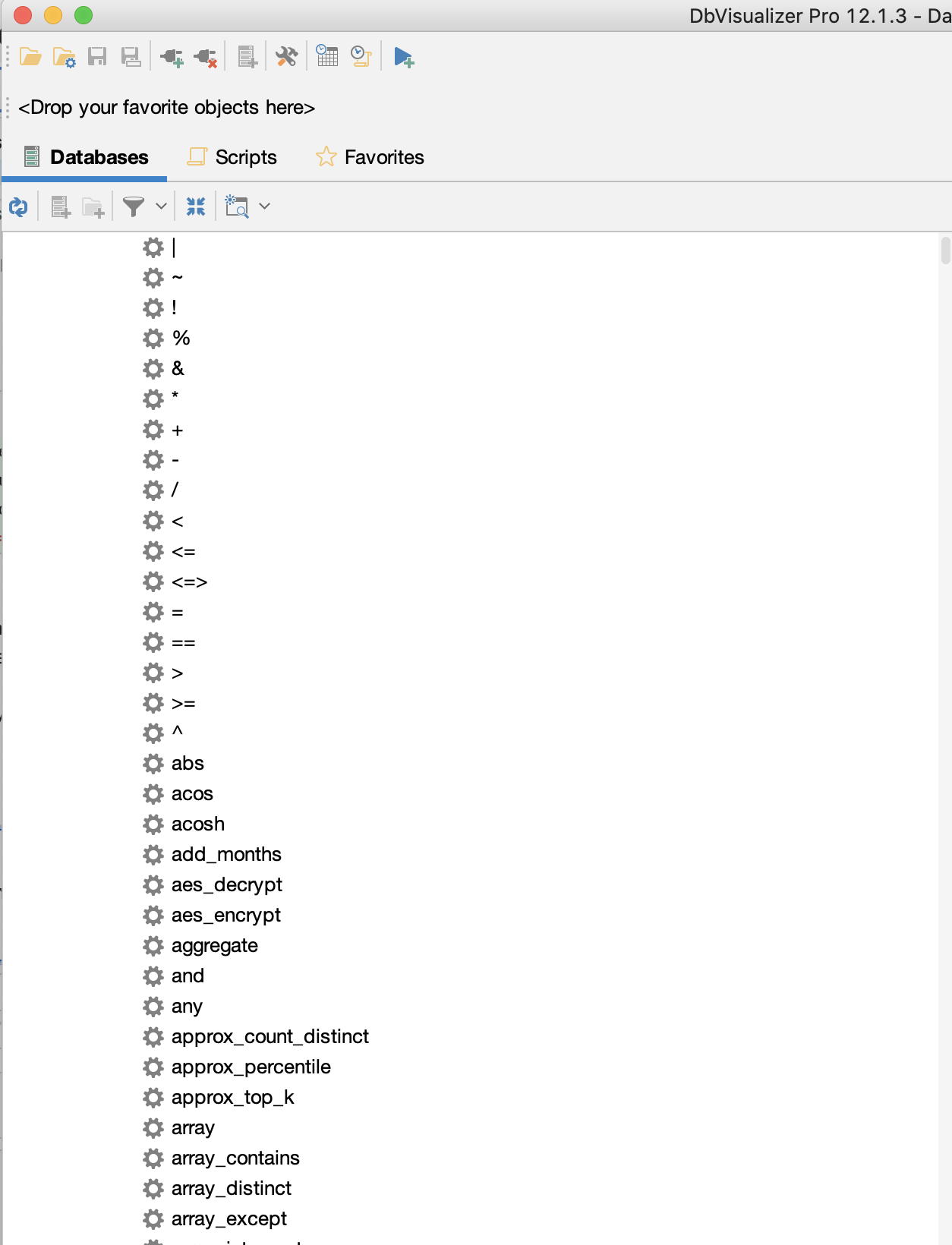
|
It sounds like you have a different meaning of a breaking change. When a function suddenly returns different values, it is considered a breaking change to me.
BTW, I agree with your requirements. You might introduce a new internal configuration to add the behavior you want. The default should be the legacy behavior at least for one release, e.g., Apache Spark 3.3, and we need to add it to the SQL migration guide. WDYT, @bogdanghit ? |
|
It sounds good to me to have it under a legacy flag. |
What changes were proposed in this pull request?
This PR implements Spark's own GetFunctionsOperation which mitigates the differences between Spark SQL and Hive UDFs. But our implementation is different from Hive's implementation:
REMARKSfield with the function usage - Hive returns an empty string.FUNCTION_TYPE, but Hive does.How was this patch tested?
unit tests