[SPARK-21334][CORE] Add metrics reporting service to External Shuffle Server #18690
Conversation
|
Can one of the admins verify this patch? |
|
I think it is because you don't configure metrics sink here, so by default none of the metrics are reported. For example if I enabled jmx sink ( Then using jconsole to connect to shuffle service, then you will see it on jconsole:
Please elaborate more if you have specific issue regarding this. |
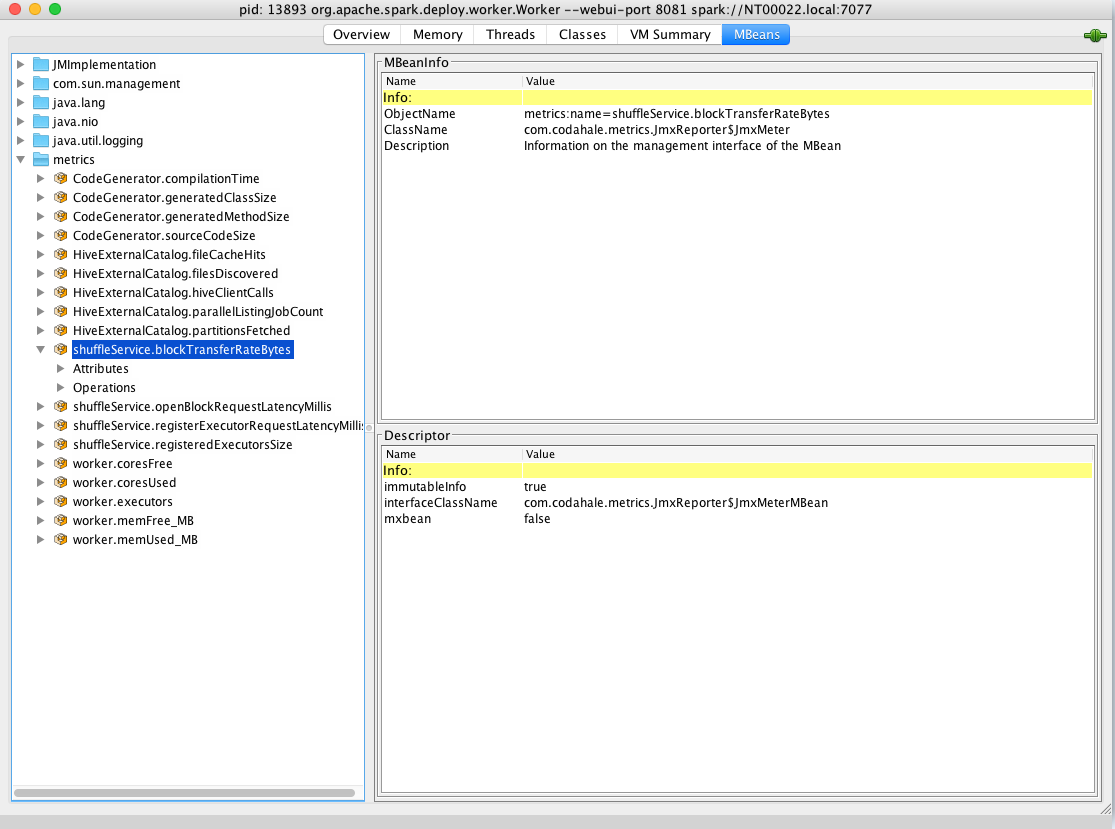
|
We were using a custom sink rather than the JmxSink for gathering metrics. The sink did NOT have a "reporter" like the ones JmxSink or CsvSink have. I guess a cleaner design is to implement a metrics reporter in the Sink and not have a reporting service as part of external shuffle service. Thanks! |
|
If your custom sink doesn't have a "reporter", then I'm not sure how does this code work in your changes? Since |
|
@jerryshao My CustomSInk has the report function defined. What I did not have was an equivalent of JmxReporter defined in my CustomSink. The reporter essentially periodically invokes the report function defined in CustomSink |
|
So I think if you want to connect your custom sink to Spark Metrics System, then you should at least follow what Spark and codahale metrics library did. Adding a feature in Spark specifically works only for your own sink seems not so reasonable, unless it is a general requirement. |
|
I understand. My previous comment was just a clarification to your question: "I'm not sure how does this code work in your changes?". I will close this PR. The JIRA is already closed. |
## What changes were proposed in this pull request? This PR proposes to close stale PRs, mostly the same instances with apache#18017 Closes apache#14085 - [SPARK-16408][SQL] SparkSQL Added file get Exception: is a directory … Closes apache#14239 - [SPARK-16593] [CORE] [WIP] Provide a pre-fetch mechanism to accelerate shuffle stage. Closes apache#14567 - [SPARK-16992][PYSPARK] Python Pep8 formatting and import reorganisation Closes apache#14579 - [SPARK-16921][PYSPARK] RDD/DataFrame persist()/cache() should return Python context managers Closes apache#14601 - [SPARK-13979][Core] Killed executor is re spawned without AWS key… Closes apache#14830 - [SPARK-16992][PYSPARK][DOCS] import sort and autopep8 on Pyspark examples Closes apache#14963 - [SPARK-16992][PYSPARK] Virtualenv for Pylint and pep8 in lint-python Closes apache#15227 - [SPARK-17655][SQL]Remove unused variables declarations and definations in a WholeStageCodeGened stage Closes apache#15240 - [SPARK-17556] [CORE] [SQL] Executor side broadcast for broadcast joins Closes apache#15405 - [SPARK-15917][CORE] Added support for number of executors in Standalone [WIP] Closes apache#16099 - [SPARK-18665][SQL] set statement state to "ERROR" after user cancel job Closes apache#16445 - [SPARK-19043][SQL]Make SparkSQLSessionManager more configurable Closes apache#16618 - [SPARK-14409][ML][WIP] Add RankingEvaluator Closes apache#16766 - [SPARK-19426][SQL] Custom coalesce for Dataset Closes apache#16832 - [SPARK-19490][SQL] ignore case sensitivity when filtering hive partition columns Closes apache#17052 - [SPARK-19690][SS] Join a streaming DataFrame with a batch DataFrame which has an aggregation may not work Closes apache#17267 - [SPARK-19926][PYSPARK] Make pyspark exception more user-friendly Closes apache#17371 - [SPARK-19903][PYSPARK][SS] window operator miss the `watermark` metadata of time column Closes apache#17401 - [SPARK-18364][YARN] Expose metrics for YarnShuffleService Closes apache#17519 - [SPARK-15352][Doc] follow-up: add configuration docs for topology-aware block replication Closes apache#17530 - [SPARK-5158] Access kerberized HDFS from Spark standalone Closes apache#17854 - [SPARK-20564][Deploy] Reduce massive executor failures when executor count is large (>2000) Closes apache#17979 - [SPARK-19320][MESOS][WIP]allow specifying a hard limit on number of gpus required in each spark executor when running on mesos Closes apache#18127 - [SPARK-6628][SQL][Branch-2.1] Fix ClassCastException when executing sql statement 'insert into' on hbase table Closes apache#18236 - [SPARK-21015] Check field name is not null and empty in GenericRowWit… Closes apache#18269 - [SPARK-21056][SQL] Use at most one spark job to list files in InMemoryFileIndex Closes apache#18328 - [SPARK-21121][SQL] Support changing storage level via the spark.sql.inMemoryColumnarStorage.level variable Closes apache#18354 - [SPARK-18016][SQL][CATALYST][BRANCH-2.1] Code Generation: Constant Pool Limit - Class Splitting Closes apache#18383 - [SPARK-21167][SS] Set kafka clientId while fetch messages Closes apache#18414 - [SPARK-21169] [core] Make sure to update application status to RUNNING if executors are accepted and RUNNING after recovery Closes apache#18432 - resolve com.esotericsoftware.kryo.KryoException Closes apache#18490 - [SPARK-21269][Core][WIP] Fix FetchFailedException when enable maxReqSizeShuffleToMem and KryoSerializer Closes apache#18585 - SPARK-21359 Closes apache#18609 - Spark SQL merge small files to big files Update InsertIntoHiveTable.scala Added: Closes apache#18308 - [SPARK-21099][Spark Core] INFO Log Message Using Incorrect Executor I… Closes apache#18599 - [SPARK-21372] spark writes one log file even I set the number of spark_rotate_log to 0 Closes apache#18619 - [SPARK-21397][BUILD]Maven shade plugin adding dependency-reduced-pom.xml to … Closes apache#18667 - Fix the simpleString used in error messages Closes apache#18782 - Branch 2.1 Added: Closes apache#17694 - [SPARK-12717][PYSPARK] Resolving race condition with pyspark broadcasts when using multiple threads Added: Closes apache#16456 - [SPARK-18994] clean up the local directories for application in future by annother thread Closes apache#18683 - [SPARK-21474][CORE] Make number of parallel fetches from a reducer configurable Closes apache#18690 - [SPARK-21334][CORE] Add metrics reporting service to External Shuffle Server Added: Closes apache#18827 - Merge pull request 1 from apache/master ## How was this patch tested? N/A Author: hyukjinkwon <[email protected]> Closes apache#18780 from HyukjinKwon/close-prs.
What changes were proposed in this pull request?
Add a metrics reporting service, that periodically reports the metrics defined in ExternalShuffleServiceSource. Currently, although the metrics are defined, they are never reported.
How was this patch tested?
Manual tests to ensure that metrics are reported on ExternalShuffleService start.