[HUDI-4586] Improve metadata fetching in bloom index #6432
Conversation
a9a329c to
f0de134
Compare
5162838 to
ab274c8
Compare
ab274c8 to
ed15f57
Compare
| throw new HoodieMetadataException("Unable to find column range metadata for partition:" + partitionName, me); | ||
| } | ||
| }, Math.max(partitions.size(), 1)); | ||
| return context.parallelize(partitions, Math.max(Math.min(partitions.size(), parallelism), 1)) |
There was a problem hiding this comment.
This limits the parallelism of column stats fetching from the metadata table.
| // Step 2: Use bloom filter to filter and the actual log file to get the record location | ||
| keyLookupResultRDD = sortedFileIdAndKeyPairs.mapPartitionsWithIndex( | ||
| new HoodieMetadataBloomIndexCheckFunction(hoodieTable), true); | ||
| keyLookupResultRDD = sortedFileIdAndKeyPairs.coalesce(config.getBloomIndexMetadataReadParallelism()) |
There was a problem hiding this comment.
This limits the parallelism of bloom filter fetching.
|
|
||
| private final String fileId; | ||
|
|
||
| private final String filename; |
There was a problem hiding this comment.
Here we store the filename to avoid recomputation of the same piece of information across stages.
There was a problem hiding this comment.
Do we really need to store both file-id and file-name? I think we can just store the file-name, and then convert it to file-id wherever necessary
| final Map<String, List<BloomIndexFileInfo>> partitionToFileInfo = | ||
| fileInfoList.stream().collect(groupingBy(Pair::getLeft, mapping(Pair::getRight, toList()))); | ||
| // partition -> {file ID -> BloomIndexFileInfo instance} | ||
| final Map<String, Map<String, BloomIndexFileInfo>> partitionToFileInfo = fileInfoList.stream() |
There was a problem hiding this comment.
Switching from List to Map for each value so that the filename can be retrieved with file ID in O(1) time.
| // that contains it. | ||
| HoodieData<Pair<String, HoodieKey>> fileComparisonPairs = | ||
| // Each entry: ((File ID, Filename), HoodieKey instance) | ||
| HoodieData<Pair<Pair<String, String>, HoodieKey>> fileComparisonPairs = |
There was a problem hiding this comment.
Along the DAG, passing down the file names so they don't need to be recomputed.
There was a problem hiding this comment.
Same applies here: i don't think we need to propagate both file-id and file-name since the latter contains the former (it increases both complexity and amount of data we need to shuffle)
There was a problem hiding this comment.
@yihua i don't think we're focusing on the right problem here: RDD parallelism should not be directly translating into concurrency of reads of the MT, since it'd be cached (we'd be reading it at most N times, where N is the number of executors not the number of concurrent tasks).
If that's not what we're observing in tests then we need to chase down why caching doesn't actually work.
| public BloomIndexFileInfo(String fileId, String minRecordKey, String maxRecordKey) { | ||
| public BloomIndexFileInfo(String fileId, String filename, String minRecordKey, String maxRecordKey) { | ||
| this.fileId = fileId; | ||
| this.filename = filename; |
| List<Pair<String, BloomIndexFileInfo>> fileInfoList = getBloomIndexFileInfoForPartitions(context, hoodieTable, affectedPartitionPathList); | ||
| final Map<String, List<BloomIndexFileInfo>> partitionToFileInfo = | ||
| fileInfoList.stream().collect(groupingBy(Pair::getLeft, mapping(Pair::getRight, toList()))); | ||
| // partition -> {file ID -> BloomIndexFileInfo instance} |
There was a problem hiding this comment.
nit: "File Id" denomination might be confusing, more accurate would be "file-group id"
|
|
||
| private final String fileId; | ||
|
|
||
| private final String filename; |
There was a problem hiding this comment.
Do we really need to store both file-id and file-name? I think we can just store the file-name, and then convert it to file-id wherever necessary
| // that contains it. | ||
| HoodieData<Pair<String, HoodieKey>> fileComparisonPairs = | ||
| // Each entry: ((File ID, Filename), HoodieKey instance) | ||
| HoodieData<Pair<Pair<String, String>, HoodieKey>> fileComparisonPairs = |
There was a problem hiding this comment.
Same applies here: i don't think we need to propagate both file-id and file-name since the latter contains the former (it increases both complexity and amount of data we need to shuffle)
| */ | ||
| public class HoodieMetadataBloomIndexCheckFunction implements | ||
| Function2<Integer, Iterator<Tuple2<String, HoodieKey>>, Iterator<List<HoodieKeyLookupResult>>> { | ||
| Function2<Integer, Iterator<Tuple2<Tuple2<String, String>, HoodieKey>>, Iterator<List<HoodieKeyLookupResult>>> { |
There was a problem hiding this comment.
In general, it's better to keep the nested hierarchies as flat as possible (makes it easier to comprehend, reduces amount of objects needed as well): in that case we could use just the Tuple3 in lieu of 2 Tuple2s
| Map<Pair<String, String>, BloomFilter> fileToBloomFilterMap = | ||
| hoodieTable.getMetadataTable().getBloomFilters(partitionNameFileNameList); | ||
| hoodieTable.getMetadataTable().getBloomFilters(partitionPathFileNameList); | ||
| LOG.error(String.format("Took %d ms to look up %s bloom filters", |
There was a problem hiding this comment.
This should rather be debug/info
| throw new HoodieIndexException("Failed to find the base file for partition: " + partitionPath | ||
| + ", fileId: " + fileId); | ||
| if (batchFileToKeysMap.size() == batchSize) { | ||
| resultList.addAll(lookupKeysInBloomFilters(batchFileToKeysMap)); |
There was a problem hiding this comment.
Let's just break in this conditional to avoid duplication
|
Following up on my previous comment: taking a deeper look i see following issues in our code at the moment
|
|
Part of this PR went into #7642 so closing this one |
Change Logs
When enabling column stats and bloom filter reading from metadata table for Bloom index (
hoodie.bloom.index.use.metadata=true), frequent S3 timeouts like below happen and cause the write job to retry a lot or fail:Relevant Spark stages are (1) fetching column stats from the metadata table (Stage 86 below) (2) fetching bloom filters from metadata table and do record key lookup (Stage 141 below)
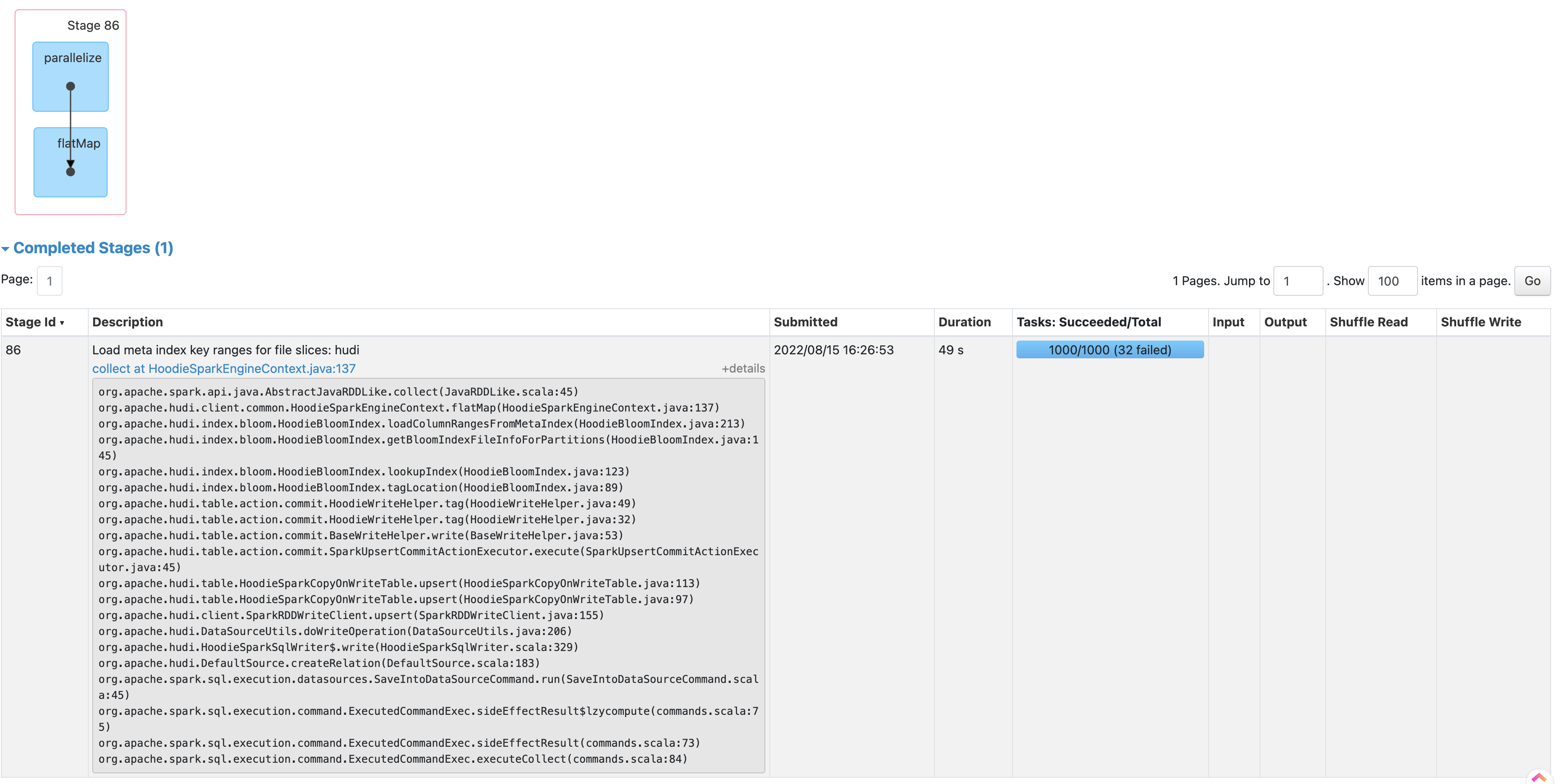
The root cause is that, the parallelism to fetch column stats and bloom filters is too high, causing too much concurrency reading metadata table from each executor, where HFiles and log files are scanned.
To address this problem, this PR adjusts the Bloom Index DAG to limit the parallelism to fetch column stats and bloom filters from the metadata table. Specifically,
hoodie.bloom.index.metadata.read.parallelism(default10) to control the parallelism for reading the index from metadata table. This affects the fetching of both column stats and bloom filters.HoodieBloomIndex::loadColumnRangesFromMetaIndex()SparkHoodieBloomIndexHelper::findMatchingFilesForRecordKeys()HoodieMetadataBloomIndexCheckFunctionto support batch processing of bloom filter fetchinghoodie.bloom.index.metadata.bloom.filter.read.batch.size(default128) to determine the batch size for reading bloom filters from metadata table. Smaller value puts less pressure on the executor memory.BloomIndexFileInfo. To support efficient lookup of file name based on the file ID, the data structure of a few intermediate results are changed.Impact
Risk level: high
The changes are tested and benchmarked through upserts to Hudi tables on S3, using both 1GB and 100GB batches.
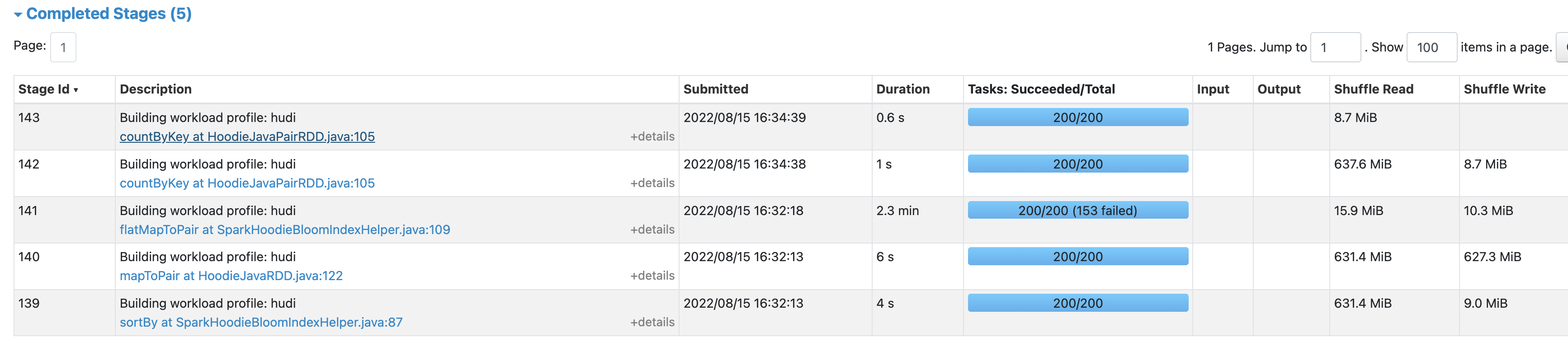
Below shows the Spark stages of fetching column stats and bloom filters after the fix. Timeouts are no longer present. The index fetching is much faster (column stats: 1min+ -> 7s, 2min+ -> 1min).


Based on the benchmarking, when enabling metadata table reading for column stats and bloom filters in Bloom index, the overall upsert latency is reduced by 1-3 min (10%+) after the fix.
Contributor's checklist