[HUDI-2101][RFC-28]support z-order for hudi #3330
Conversation
|
now the RFC-27 is not implement, once RFC-27 is merged, i will update code to adapt it. hilbert implement will come soon |
93897c1 to
b474498
Compare
|
@leesf could you pls help me to review this pr |
There was a problem hiding this comment.
Do we need another write type for z-order? For my first think, z-order is a layout optimize for the table which is much similar to order-by. As currently we already have the clustering to optimize the layout by order-by, can we implement the z-order by under the clustering ? So that we can support two kind of data clustering:
Clustering table order by col1;
Clustering table zorder by col2;
There was a problem hiding this comment.
we support two operation type
- cluster support
- zorder optimize by overwrite table。
There was a problem hiding this comment.
It make sense to me now. But one thing I want to understand is that what is the difference between the two operation types you list, if cluster support can not cover the case of zorder optimize by overwrite table>
There was a problem hiding this comment.
@pengzhiwei2018 you mean sql? good suggest, now we only support api . i will add sql support for anther pr. thanks for your suggest
There was a problem hiding this comment.
No, I mean if 1. cluster support can cover the function of 2. zorder optimize by overwrite table, we can only implement the zorder by under the clustering. No need to introduce a write type for z-order. As you know, hudi currently has too many write types, which add the cost of use for our users.
There was a problem hiding this comment.
@pengzhiwei2018 Due to the implementation of Hudi itself, optimze by overwritetable is more convenient to use, since cluster operation need to set many properties。
Another consideration: as we know delta lake support z-order, just like delta lake api, we want keep the same implement
There was a problem hiding this comment.
I'm +1 to keep this as a clustering strategy. If needed, we can make top level API different. But underneath, WriteClient API and ActionExecutor will benefit from using same code (I do see lot of copy paste code there right now). Any changes we do in one ActionExecutor will have to be copied to other which is going to be a challenge.
|
@allwefantasy. could you pls help me to review the z-order partial codes. thanks |
...hudi-spark/src/main/scala/org/apache/hudi/clustering/SparkZSortAndSizeExecutionStrategy.java
Outdated
Show resolved
Hide resolved
hudi-client/hudi-spark-client/src/main/java/org/apache/spark/sql/hudi/UnsafeAccess.java
Outdated
Show resolved
Hide resolved
...lient/hudi-client-common/src/main/java/org/apache/hudi/client/AbstractHoodieWriteClient.java
Outdated
Show resolved
Hide resolved
...lient/hudi-client-common/src/main/java/org/apache/hudi/client/AbstractHoodieWriteClient.java
Outdated
Show resolved
Hide resolved
hudi-client/hudi-client-common/src/main/java/org/apache/hudi/table/HoodieTable.java
Outdated
Show resolved
Hide resolved
...in/java/org/apache/hudi/table/action/cluster/SparkExecuteClusteringCommitActionExecutor.java
Outdated
Show resolved
Hide resolved
hudi-client/hudi-spark-client/src/main/java/org/apache/spark/sql/hudi/ZOrderingUtil.java
Outdated
Show resolved
Hide resolved
hudi-client/hudi-spark-client/src/main/scala/org/apache/spark/sql/OptimizeTableByCurve.scala
Outdated
Show resolved
Hide resolved
hudi-client/hudi-spark-client/src/main/scala/org/apache/spark/sql/Zoptimize.scala
Outdated
Show resolved
Hide resolved
hudi-client/hudi-spark-client/src/main/scala/org/apache/spark/sql/Zoptimize.scala
Outdated
Show resolved
Hide resolved
|
@leesf thanks for your review. i will try to resolve all comments |
|
@leesf address all commts. make the code more genral to adapt both z-order and hilbert optimize. |
533d02e to
cbc214a
Compare
|
@leesf @garyli1019 @nsivabalan @pengzhiwei2018 . pls help me review this pr again, thanks.
|
78a02f4 to
6912152
Compare
|
(WIP) Pending items (for my own tracking)
|
 vinothchandar
left a comment
vinothchandar
left a comment
There was a problem hiding this comment.
@xiarixiaoyao I pushed some small changes to config names and such. The only issue to resolve is to move the data skipping config.
- Add it to the Spark
DataSourceReadOptionsand remove from HoodieWriteConfig? Then we can rework the code in HoodieFileIndex to be protected by this config, also defensively protect the existing code paths. - For updating statistics during writing, we can just check whether layout optimization is enabled? (no need to check data skipping enabled there, since its a query side config).
- Also can we make sure this works for Spark SQL as well (not just datasource)
What do you think?
There was a problem hiding this comment.
need to probably guard these changes with a config as well.
|
Side note: At-least from IDE builds, I get the following error when running tests. did you fae this? have you tried running this on a cluster using a spark bundle?
|
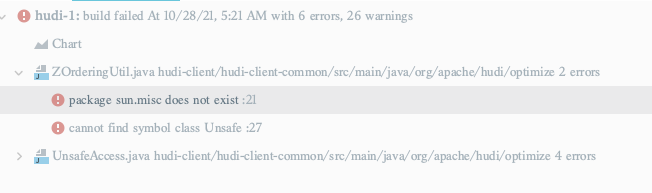
|
@vinothchandar thanks for your suggestion. ans: i use java 8 to run those code , of course i test those code in cluster. but i find if we uses java 11 to run those code in IDE, IDE will throw "package sun.misc. does not exist", since Packages com.sun.* and sun.* hold internal stuff, and should not be used by thirdparty applications (like yours probably) in general case. now i removed all unsafe function, it should be ok for java 11. update the code. i think we may no need to move data skipping config to DataSourceReadOptions. we can introduce a config in DataSourceReadOptions. WDYT? |
|
@hudi-bot run azure |
yes. we can introduce a new one there. But wondering if we need the data skipping flag in Let me know when/if you have tested the latest code on your cluster and verified performance gains are still same (after removing the unsafe code etc). Thanks for working through this with me |
|
@vinothchandar I hope we can merge this feature before the 0.10 release, and I will try my best to resolve all the comments。 |
|
@vinothchandar i test the performance about z-order cluster by using unsafe sort and java sort,
test result show: No performance degradation. |
|
@hudi-bot run azure |
|
Sounds good. I ll tkae a final pass and land this, this week. |
vinothchandar
left a comment
There was a problem hiding this comment.
Only a few minor things. LGTM overall., will push out few tweaks and land
|
@xiarixiaoyao do you plan to add hilbert curves in the 0.10.0 release? (3rd week of nov) right now, this config is sort of unused? |
|
@hudi-bot run azure |
|
@vinothchandar yes, hilbert curve is ready, i think time is enough to add hilbert curve. |
|
sg. will land once CI passes. right now, its queued up here. https://dev.azure.com/apache-hudi-ci-org/apache-hudi-ci/_build/results?buildId=3067&view=results |
|
@xushiyan
|
|
@xiarixiaoyao let's write a blog around z-ordering? If you are up for it, I can help you with an initial draft and you can add more to it? what do you think ? |
|
@vinothchandar Of course, let's finish this together |
Tips
What is the purpose of the pull request
pr for RFC - 28 : Support Z-order curve. Z-order is a technique that allows you to map multidimensional data to a single dimension. We can use this feature to improve query performance.
query performance test:
we use databricks test case
https://databricks.com/blog/2018/07/31/processing-petabytes-of-data-in-seconds-with-databricks-delta.html?spm=a2c4g.11186623.2.11.2a8f1693QNwUSH&_ga=2.29295480.552083878.1584501563-968665100.1584501563
https://help.aliyun.com/document_detail/168137.html?spm=a2c4g.11186623.6.563.10d758ccclYtVb
prepare data:
10 billion data, 5w files (parquet files)
test env:
spark-3.1.0
hadoop-3.1.0
hudi-0.8.0
test step:
test result
<style> </style>Brief change log
(for example:)
Verify this pull request
UT added.
Committer checklist
Has a corresponding JIRA in PR title & commit
Commit message is descriptive of the change
CI is green
Necessary doc changes done or have another open PR
For large changes, please consider breaking it into sub-tasks under an umbrella JIRA.