[MLU] add mlu kernel for accuracy op#39337
Conversation
|
Thanks for your contribution! |
|
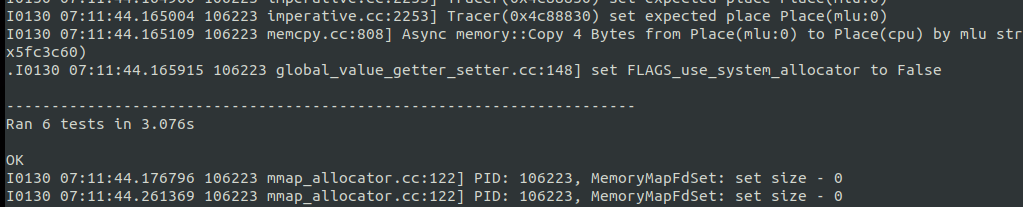
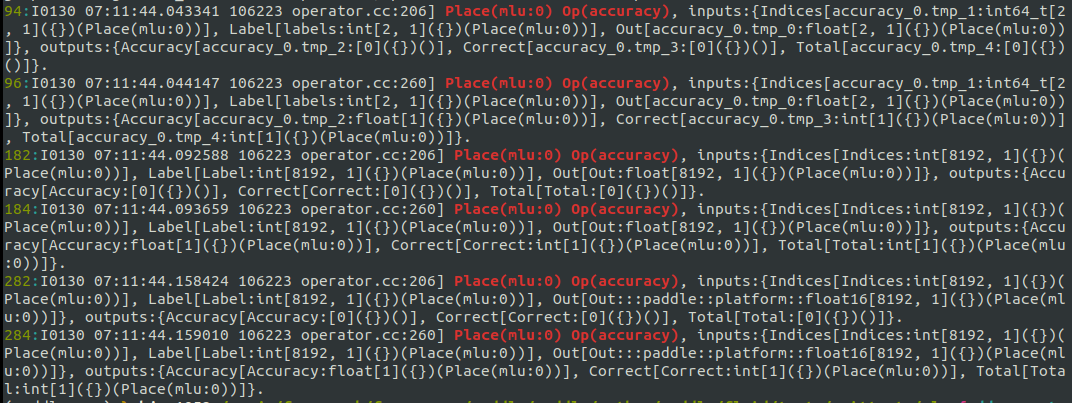
pytest运行结果: 运行place在MLU上: |
|
Sorry to inform you that 80431e9's CIs have passed for more than 7 days. To prevent PR conflicts, you need to re-run all CIs manually. |
| distributed under the License is distributed on an "AS IS" BASIS, | ||
| WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | ||
| See the License for the specific language governing permissions and | ||
| limitations under the License. */ |
| "In accuracy mlu kernel, cast indices from [%s] to " | ||
| "[%s] is not supported.", | ||
| framework::DataTypeToString(indices->type()), | ||
| framework::DataTypeToString(VT::FP32)); |
There was a problem hiding this comment.
请根据CI错误提示,修改这个error message:
2022-02-08 11:43:31 0. The error message you wrote in PADDLE_ENFORCE{**} or PADDLE_THROW does not meet our error message writing specification. Possible errors include 1. the error message is empty / 2. the error message is too short / 3. the error type is not specified. Please read the specification [ https://github.com/PaddlePaddle/Paddle/wiki/Paddle-Error-Message-Writing-Specification ], then refine the error message. If it is a mismatch, please request chenwhql (Recommend), luotao1 or lanxianghit review and approve.
2022-02-08 11:43:31 The PADDLE_ENFORCE{**} or PADDLE_THROW entries that do not meet the specification are as follows:
2022-02-08 11:43:31 PADDLE_ENFORCE_EQ(MLUSupportsCast(indices->type(), VT::INT32), true, + "In accuracy mlu kernel, cast indices from [%s] to " + "[%s] is not supported.", + framework::DataTypeToString(indices->type()), + framework::DataTypeToString(VT::FP32));
2022-02-08 11:43:31 PADDLE_ENFORCE_EQ(MLUSupportsCast(label->type(), VT::INT32), true, + "In accuracy mlu kernel, cast label from [%s] to [%s] " + "is not supported.", + framework::DataTypeToString(label->type()), + framework::DataTypeToString(VT::FP32));
| "In accuracy mlu kernel, cast label from [%s] to [%s] " | ||
| "is not supported.", | ||
| framework::DataTypeToString(label->type()), | ||
| framework::DataTypeToString(VT::FP32)); |
* 【Pten】Adjust the Empyt dev_api (#39143) * adjust the Empyt dev_api * fix merge conflict * fix sparse_utils_kernel * Fix code conflict of empty dev_api (#39430) * fix code conflict * clear cache * just try * [PluggableDevice] custom kernel supports multi cpp_dtype registering (#39385) * [PTen] Add standard kernel suffix set (#39404) * add standard_suffix_set_and_remove_reshape_with_xshape * revert reshape change * polish reduce name * [pten] update isnan registration (#39419) * update isnan registration * fix compile * [bf16] add bf16 kernel: dropout & reshape & slice (#39395) * add dropout * add reshape * add slice * refien slice unittest * refine slice unittest * add cpu bf16 kernel * [bf16] add bf16 kernel: squeeze & unsqueeze & stack (#39402) * add squeeze unsqueeze stack * add unittest * add cpu kernel * Modify the unsqueeze dimension of input data in conv1d NCL And NLC format (#38425) * optimize conv1d forward * add conv opt * Optimize memory copy * delete share data with * set num_filters=512 * add nlc optimize * Optimize num_filter=512 data on A100 and V100 * Fix the workspace_size size setting of filter * 【Pten】Refactor C++ API code-gen (#39408) * refactor C++ API code-gen * fix windows problem of C++ API * Refactored Python-C Attributes Parsing Functions (#39328) * Add _get_parameter method to Lamb optimizer (#39416) * add _get_parameter func to lamb * remove duplicate code * mkldnn layout issue fix (#39422) * mkldnn conv fix * definetion * fix compile error on jetson (#39441) * move Masked select to pten (#39193) * move masked select cpu kernel * add masked selected gpu kernel; test=develop * fix bugs; test=develop * bug fix; test=develop * bug fix; test=develop * add namespace to set mask array; test=develop * fix bug; test=develop * fix bugs; test=develop * fix ddim bug; test=develop * fix npu op bug; test=develop * fix xpu dependecy bug; test=develop * move kernel args to sig.cc; test=develop * 【PaddlePaddle Hackathon】31. Add Java frontend for Paddle Inference (#37162) * fix check error of ResetHolder (#39439) * Added python-c code generation for final state Eager Dygraph (#39233) * Removed debug info * Added automatic code generation for final state Eager Dygraph * Modified backward yaml * Added EagerUtils helper functions for final state CodeGen * Adjusted CMakeFiles to support compilation for final state auto generated codes * Added python-c code generation for final state Eager Dygraph * Fixed minor issue * Fixed yaml.load() method failure * Fixed minor issues * Refactored Python-C Attributes Parsing Functions * Fixed minor issue with Python-C AddFunctions * Fixed issues from merge * Fixed merge issues * change dtype of pooling mask to 'int32' for Paddle2ONNX (#39314) * change dtype of pooling mask to 'int32' for Paddle2ONNX * empty commit to rerun ci * fix format * share MemOptVarInfos of external variables into cinn_launch subgraph (#39209) * add a graph pass to share MemOptVarInfos of external variables into subgraph * update pass name * fix compile failed * add share_mem_opt_info_to_subgraph_pass test * share_mem_opt_info_to_subgraph_pass_test pass * modify some codes for better style and more robust * update cmake * [NPU] add reduce_min (#39019) [NPU] add reduce_min * [MLU] add mlu kernel for accuracy op (#39337) * [MLU] add mlu kernel for accuracy op * fix license format * fix error message * [Dy2St]Handle `a, b = paddle.shape(x)` in Static Analysis (#39245) * refine Assign * add UT * 【Pten】Auto-Generate InterMeta register (#39436) * fix code conflict * generate inter_meta register * clear cache * just try * add sign c++ api * polish some code * Support different dtypes of inputs for elementwise ops (#38859) * improve backward performance * support different dtypes for elementwise ops * Add profiler node tree implementation (#39316) * add event node implementation * modify profiler.stop interface * fix according to review * fix file mode * modify class method name in event_node.cc * modify LLONG_MAX to ULLONG_MAX * fix ci error * fix ci error * add print pten kernel tool (#39371) * test=document_fix;add print pten kernel tool * test=document_fix * test=document_fix * test=document_fix * test=document_fix * add print_pten_kernels tool * add print_pten_kernels tool * fix windows complie * notest,test=rocm_ci * add merge tool * add comments * [new-exec] set type of op-kernel op by place (#39458) * Add log for executor (#39459) * add align for WorkQueue * add spinlock * merge develop * merge * Add EventsWaiter * Revert "Add EventsWaiter" This reverts commit e206173. * add log for Executor Co-authored-by: liutiexing <[email protected]> * [Paddle Inference] support ernie quant model with interleaved (#39424) * support ernie quant model with interleaved * support ernie quant model with interleaved * support ernie quant model with interleaved * support ernie quant model with interleaved * support ernie quant model with interleaved * support ernie quant model with interleaved * support ernie quant model with interleaved * 统一 ps 开发 - python (#39431) * delete gloo connect retry * the_one_ps dirs reconstruct * . * . * create the_one_ps dirs * create the_one_ps dirs * create the_one_ps dirs * create the_one_ps dirs * create the_one_ps dirs * create the_one_ps dirs * the one ps dirs modify * the one ps dirs modify * the one ps dirs modify * the one ps dirs modify * refactor ps optimize * refactor ps optimize * refactor ps optimize * . * . * . * . * . * . * refactor theoneps * the_one_ps * add ps pass unittest * add ps pass unittest * ps unitest frame * ps unittest frame * ps unittest frame * ps unittest frame * ps unittest frame * ps unittest frame * ps unittest frame * ps unittest frame * ps unittest frame * ps unittest frame * ps unittest frame * ps unittest frame * ps unittest frame * ps unittest frame * ps unittest frame * ps unittest frame * ps unittest frame * add cpu_async_ps_mode test * add cpu_async_ps_mode test * add cpu_async_ps_mode test * ps unittest ready * ps unittest ready * solve dist_pass init conflict * solve import CommContext error * unittest ok * implement AllocateFrom * solve setup.py.in conflict * solve conflict * solve conflict * solve conflict * . * . * cpu-async-ps minimize test ok & gpu minimize test ok Co-authored-by: zkh2016 <[email protected]> * [PTen] Move grad GetExpectedPtenKernelArgs into pten (#39418) * move grad get expected pten kernel args * fix reduce sum error * fix element_sub_grad failed * revert kernel judge change * fix compilation warning on mac (#39438) * get build time (#39368) * fix prelu trt convert (#39389) * Optimize bilinear interpolation foward (#39243) * bilinear_fw init * optimize code * pre-compute linear_interp input index * Optimize performance of softmax_bwd when axis!=-1 (#38609) * Optimize performance of softmax_bwd when axis!=-1 * fix * fix * fix * fix * [PTen] Remove pten core's dependency on fluid xxx_info.h (#39401) * ermove xxx_info include * fix namespace error * resolve conflict * skip xpu context in registry * fix macro error * resolve conflict * resolve conflict * revert xpu convert * remove trans to fluid place * remove useless headers * [Pten] move operators/math/math_function_* to pten/kernels/func (#39300) * move operators/math/math_function_* to pten/kernels/func * namespace from `paddle::operators::math` to `pten::funcs` * [MLU] add pool2d and pool2d_grad mlu kernel (#39453) * [MLU]support c_gen_cncl_id_op run on MLU device (#39336) Co-authored-by: zhangna <[email protected]> * [bf16] add bf16 kernel: transpose & unbind (#39457) * add transpose unbind * add unittest * refine transpose unittest * uniform_random op for mlu (#39450) * [MLU] add pool2d pytest (#39454) * Added shape (U)INT8/BF16/FP32 oneDNN kernel (#36033) * added shape oneDNN kernel * removed unnecessary import from test * added skipping tests for GPU * refactoring * refactored shape kernel * added tests in new framework * removed one line * minor change * added newline at EOF * added formatting * added attributes as extra * move memcpy.h into cc file (#39469) * Add TensorRT inspector into Paddle-TRT (#38362) * Fix add profiler node tree implementation cmake error (#39474) * add event node implementation * modify profiler.stop interface * fix according to review * fix file mode * modify class method name in event_node.cc * modify LLONG_MAX to ULLONG_MAX * fix ci error * fix ci error * fix dependency error * unify naming style (#39481) * [Pten] Generate Wrapped InferMeta by Yaml (#39482) * generate wrapped_infer_meta * add test for wrapped_infer_meta * Update test_meta_fn_utils.cc * change the dir of generated file Co-authored-by: Chen Weihang <[email protected]> Co-authored-by: Chen Weihang <[email protected]> * Adjusted python-level trace_op to accomodate final state Eager Dygraph (#39319) * Removed debug info * Added automatic code generation for final state Eager Dygraph * Modified backward yaml * Added EagerUtils helper functions for final state CodeGen * Adjusted CMakeFiles to support compilation for final state auto generated codes * Added python-c code generation for final state Eager Dygraph * Fixed minor issue * Fixed yaml.load() method failure * Fixed minor issues * Refactored Python-C Attributes Parsing Functions * Fixed minor issue with Python-C AddFunctions * Adjusted python-level trace_op to accomodate final state Eager Dygraph * Added Logs for final state Eager Dygraph * Fixed merge issues * Fixed minor issue * Fixed get_tensor method for EagerTensor (#39414) * Enabled Eager OpTest #1 * Enabled Eager OpTest #1 * Fixed get_tensor method for EagerTensor * [Approver Update] update check approver of qili93, test=document_fix (#39483) * [MLU] add mlu kernel for c_broadcast op (#39470) * update xpu test build script and fix get_test_cover_info, *test=kunlun (#39235) * fix gather_nd, *test=kunlun (#39283) * [pten] add split kernel (#39060) * add split kernel * add split kernel signature * fix split bug * modify MakePtenScalarArrayFromVarList * modify MakePtenScalarArrayFromVarList * fix split windows register error * add test case for split kernel * replace raw split kernel with pten kernel * fix makeScalar/ScalarArray bug * remove debug log * remove int64_t type in buildPtcontext * update by code review * fix split dev test failed * change DenseTensorMeta to MetaTensor * change split api code from auto gen to manual * split cuda kernel support bfloat16 type * fix conflict * rm raw split kernel * merge develop branch * change to pten::errors * new may of test cases, *test=kunlun (#39444) * new may of test cases, *test=kunlun * new may of test cases, *test=kunlun * new may of test cases, *test=kunlun * [PTen] Add HasAttr for ArgumentMappingContext (#39464) * add has_attr for arg map context * skip useless attr now * skip attr if not exists * fix typo * [ROCm] fix missing dcu kernel in operator.cmake, test=develop (#39480) Co-authored-by: zyfncg <[email protected]> Co-authored-by: Aganlengzi <[email protected]> Co-authored-by: Chen Weihang <[email protected]> Co-authored-by: Leo Chen <[email protected]> Co-authored-by: zhangbo9674 <[email protected]> Co-authored-by: crystal <[email protected]> Co-authored-by: Zhanlue Yang <[email protected]> Co-authored-by: sneaxiy <[email protected]> Co-authored-by: wenbin <[email protected]> Co-authored-by: Wilber <[email protected]> Co-authored-by: hong <[email protected]> Co-authored-by: chenyanlann <[email protected]> Co-authored-by: Wei Shengyu <[email protected]> Co-authored-by: TeFeng Chen <[email protected]> Co-authored-by: furnace <[email protected]> Co-authored-by: fwenguang <[email protected]> Co-authored-by: 0x45f <[email protected]> Co-authored-by: Zhang Ting <[email protected]> Co-authored-by: chenjian <[email protected]> Co-authored-by: Shang Zhizhou <[email protected]> Co-authored-by: liutiexing <[email protected]> Co-authored-by: liutiexing <[email protected]> Co-authored-by: Wangzheee <[email protected]> Co-authored-by: ziyoujiyi <[email protected]> Co-authored-by: zkh2016 <[email protected]> Co-authored-by: zhangchunle <[email protected]> Co-authored-by: JingZhuangzhuang <[email protected]> Co-authored-by: Lijunhui <[email protected]> Co-authored-by: Zhang Zheng <[email protected]> Co-authored-by: Feiyu Chan <[email protected]> Co-authored-by: zn <[email protected]> Co-authored-by: zhangna <[email protected]> Co-authored-by: joeqiao12 <[email protected]> Co-authored-by: jakpiase <[email protected]> Co-authored-by: Leo Chen <[email protected]> Co-authored-by: Chen Weihang <[email protected]> Co-authored-by: Qi Li <[email protected]> Co-authored-by: maxhuiy <[email protected]> Co-authored-by: TTerror <[email protected]> Co-authored-by: chentianyu03 <[email protected]> Co-authored-by: helen88 <[email protected]>
* 【Pten】Adjust the Empyt dev_api (PaddlePaddle#39143) * adjust the Empyt dev_api * fix merge conflict * fix sparse_utils_kernel * Fix code conflict of empty dev_api (PaddlePaddle#39430) * fix code conflict * clear cache * just try * [PluggableDevice] custom kernel supports multi cpp_dtype registering (PaddlePaddle#39385) * [PTen] Add standard kernel suffix set (PaddlePaddle#39404) * add standard_suffix_set_and_remove_reshape_with_xshape * revert reshape change * polish reduce name * [pten] update isnan registration (PaddlePaddle#39419) * update isnan registration * fix compile * [bf16] add bf16 kernel: dropout & reshape & slice (PaddlePaddle#39395) * add dropout * add reshape * add slice * refien slice unittest * refine slice unittest * add cpu bf16 kernel * [bf16] add bf16 kernel: squeeze & unsqueeze & stack (PaddlePaddle#39402) * add squeeze unsqueeze stack * add unittest * add cpu kernel * Modify the unsqueeze dimension of input data in conv1d NCL And NLC format (PaddlePaddle#38425) * optimize conv1d forward * add conv opt * Optimize memory copy * delete share data with * set num_filters=512 * add nlc optimize * Optimize num_filter=512 data on A100 and V100 * Fix the workspace_size size setting of filter * 【Pten】Refactor C++ API code-gen (PaddlePaddle#39408) * refactor C++ API code-gen * fix windows problem of C++ API * Refactored Python-C Attributes Parsing Functions (PaddlePaddle#39328) * Add _get_parameter method to Lamb optimizer (PaddlePaddle#39416) * add _get_parameter func to lamb * remove duplicate code * mkldnn layout issue fix (PaddlePaddle#39422) * mkldnn conv fix * definetion * fix compile error on jetson (PaddlePaddle#39441) * move Masked select to pten (PaddlePaddle#39193) * move masked select cpu kernel * add masked selected gpu kernel; test=develop * fix bugs; test=develop * bug fix; test=develop * bug fix; test=develop * add namespace to set mask array; test=develop * fix bug; test=develop * fix bugs; test=develop * fix ddim bug; test=develop * fix npu op bug; test=develop * fix xpu dependecy bug; test=develop * move kernel args to sig.cc; test=develop * 【PaddlePaddle Hackathon】31. Add Java frontend for Paddle Inference (PaddlePaddle#37162) * fix check error of ResetHolder (PaddlePaddle#39439) * Added python-c code generation for final state Eager Dygraph (PaddlePaddle#39233) * Removed debug info * Added automatic code generation for final state Eager Dygraph * Modified backward yaml * Added EagerUtils helper functions for final state CodeGen * Adjusted CMakeFiles to support compilation for final state auto generated codes * Added python-c code generation for final state Eager Dygraph * Fixed minor issue * Fixed yaml.load() method failure * Fixed minor issues * Refactored Python-C Attributes Parsing Functions * Fixed minor issue with Python-C AddFunctions * Fixed issues from merge * Fixed merge issues * change dtype of pooling mask to 'int32' for Paddle2ONNX (PaddlePaddle#39314) * change dtype of pooling mask to 'int32' for Paddle2ONNX * empty commit to rerun ci * fix format * share MemOptVarInfos of external variables into cinn_launch subgraph (PaddlePaddle#39209) * add a graph pass to share MemOptVarInfos of external variables into subgraph * update pass name * fix compile failed * add share_mem_opt_info_to_subgraph_pass test * share_mem_opt_info_to_subgraph_pass_test pass * modify some codes for better style and more robust * update cmake * [NPU] add reduce_min (PaddlePaddle#39019) [NPU] add reduce_min * [MLU] add mlu kernel for accuracy op (PaddlePaddle#39337) * [MLU] add mlu kernel for accuracy op * fix license format * fix error message * [Dy2St]Handle `a, b = paddle.shape(x)` in Static Analysis (PaddlePaddle#39245) * refine Assign * add UT * 【Pten】Auto-Generate InterMeta register (PaddlePaddle#39436) * fix code conflict * generate inter_meta register * clear cache * just try * add sign c++ api * polish some code * Support different dtypes of inputs for elementwise ops (PaddlePaddle#38859) * improve backward performance * support different dtypes for elementwise ops * Add profiler node tree implementation (PaddlePaddle#39316) * add event node implementation * modify profiler.stop interface * fix according to review * fix file mode * modify class method name in event_node.cc * modify LLONG_MAX to ULLONG_MAX * fix ci error * fix ci error * add print pten kernel tool (PaddlePaddle#39371) * test=document_fix;add print pten kernel tool * test=document_fix * test=document_fix * test=document_fix * test=document_fix * add print_pten_kernels tool * add print_pten_kernels tool * fix windows complie * notest,test=rocm_ci * add merge tool * add comments * [new-exec] set type of op-kernel op by place (PaddlePaddle#39458) * Add log for executor (PaddlePaddle#39459) * add align for WorkQueue * add spinlock * merge develop * merge * Add EventsWaiter * Revert "Add EventsWaiter" This reverts commit e206173. * add log for Executor Co-authored-by: liutiexing <[email protected]> * [Paddle Inference] support ernie quant model with interleaved (PaddlePaddle#39424) * support ernie quant model with interleaved * support ernie quant model with interleaved * support ernie quant model with interleaved * support ernie quant model with interleaved * support ernie quant model with interleaved * support ernie quant model with interleaved * support ernie quant model with interleaved * 统一 ps 开发 - python (PaddlePaddle#39431) * delete gloo connect retry * the_one_ps dirs reconstruct * . * . * create the_one_ps dirs * create the_one_ps dirs * create the_one_ps dirs * create the_one_ps dirs * create the_one_ps dirs * create the_one_ps dirs * the one ps dirs modify * the one ps dirs modify * the one ps dirs modify * the one ps dirs modify * refactor ps optimize * refactor ps optimize * refactor ps optimize * . * . * . * . * . * . * refactor theoneps * the_one_ps * add ps pass unittest * add ps pass unittest * ps unitest frame * ps unittest frame * ps unittest frame * ps unittest frame * ps unittest frame * ps unittest frame * ps unittest frame * ps unittest frame * ps unittest frame * ps unittest frame * ps unittest frame * ps unittest frame * ps unittest frame * ps unittest frame * ps unittest frame * ps unittest frame * ps unittest frame * add cpu_async_ps_mode test * add cpu_async_ps_mode test * add cpu_async_ps_mode test * ps unittest ready * ps unittest ready * solve dist_pass init conflict * solve import CommContext error * unittest ok * implement AllocateFrom * solve setup.py.in conflict * solve conflict * solve conflict * solve conflict * . * . * cpu-async-ps minimize test ok & gpu minimize test ok Co-authored-by: zkh2016 <[email protected]> * [PTen] Move grad GetExpectedPtenKernelArgs into pten (PaddlePaddle#39418) * move grad get expected pten kernel args * fix reduce sum error * fix element_sub_grad failed * revert kernel judge change * fix compilation warning on mac (PaddlePaddle#39438) * get build time (PaddlePaddle#39368) * fix prelu trt convert (PaddlePaddle#39389) * Optimize bilinear interpolation foward (PaddlePaddle#39243) * bilinear_fw init * optimize code * pre-compute linear_interp input index * Optimize performance of softmax_bwd when axis!=-1 (PaddlePaddle#38609) * Optimize performance of softmax_bwd when axis!=-1 * fix * fix * fix * fix * [PTen] Remove pten core's dependency on fluid xxx_info.h (PaddlePaddle#39401) * ermove xxx_info include * fix namespace error * resolve conflict * skip xpu context in registry * fix macro error * resolve conflict * resolve conflict * revert xpu convert * remove trans to fluid place * remove useless headers * [Pten] move operators/math/math_function_* to pten/kernels/func (PaddlePaddle#39300) * move operators/math/math_function_* to pten/kernels/func * namespace from `paddle::operators::math` to `pten::funcs` * [MLU] add pool2d and pool2d_grad mlu kernel (PaddlePaddle#39453) * [MLU]support c_gen_cncl_id_op run on MLU device (PaddlePaddle#39336) Co-authored-by: zhangna <[email protected]> * [bf16] add bf16 kernel: transpose & unbind (PaddlePaddle#39457) * add transpose unbind * add unittest * refine transpose unittest * uniform_random op for mlu (PaddlePaddle#39450) * [MLU] add pool2d pytest (PaddlePaddle#39454) * Added shape (U)INT8/BF16/FP32 oneDNN kernel (PaddlePaddle#36033) * added shape oneDNN kernel * removed unnecessary import from test * added skipping tests for GPU * refactoring * refactored shape kernel * added tests in new framework * removed one line * minor change * added newline at EOF * added formatting * added attributes as extra * move memcpy.h into cc file (PaddlePaddle#39469) * Add TensorRT inspector into Paddle-TRT (PaddlePaddle#38362) * Fix add profiler node tree implementation cmake error (PaddlePaddle#39474) * add event node implementation * modify profiler.stop interface * fix according to review * fix file mode * modify class method name in event_node.cc * modify LLONG_MAX to ULLONG_MAX * fix ci error * fix ci error * fix dependency error * unify naming style (PaddlePaddle#39481) * [Pten] Generate Wrapped InferMeta by Yaml (PaddlePaddle#39482) * generate wrapped_infer_meta * add test for wrapped_infer_meta * Update test_meta_fn_utils.cc * change the dir of generated file Co-authored-by: Chen Weihang <[email protected]> Co-authored-by: Chen Weihang <[email protected]> * Adjusted python-level trace_op to accomodate final state Eager Dygraph (PaddlePaddle#39319) * Removed debug info * Added automatic code generation for final state Eager Dygraph * Modified backward yaml * Added EagerUtils helper functions for final state CodeGen * Adjusted CMakeFiles to support compilation for final state auto generated codes * Added python-c code generation for final state Eager Dygraph * Fixed minor issue * Fixed yaml.load() method failure * Fixed minor issues * Refactored Python-C Attributes Parsing Functions * Fixed minor issue with Python-C AddFunctions * Adjusted python-level trace_op to accomodate final state Eager Dygraph * Added Logs for final state Eager Dygraph * Fixed merge issues * Fixed minor issue * Fixed get_tensor method for EagerTensor (PaddlePaddle#39414) * Enabled Eager OpTest PaddlePaddle#1 * Enabled Eager OpTest PaddlePaddle#1 * Fixed get_tensor method for EagerTensor * [Approver Update] update check approver of qili93, test=document_fix (PaddlePaddle#39483) * [MLU] add mlu kernel for c_broadcast op (PaddlePaddle#39470) * update xpu test build script and fix get_test_cover_info, *test=kunlun (PaddlePaddle#39235) * fix gather_nd, *test=kunlun (PaddlePaddle#39283) * [pten] add split kernel (PaddlePaddle#39060) * add split kernel * add split kernel signature * fix split bug * modify MakePtenScalarArrayFromVarList * modify MakePtenScalarArrayFromVarList * fix split windows register error * add test case for split kernel * replace raw split kernel with pten kernel * fix makeScalar/ScalarArray bug * remove debug log * remove int64_t type in buildPtcontext * update by code review * fix split dev test failed * change DenseTensorMeta to MetaTensor * change split api code from auto gen to manual * split cuda kernel support bfloat16 type * fix conflict * rm raw split kernel * merge develop branch * change to pten::errors * new may of test cases, *test=kunlun (PaddlePaddle#39444) * new may of test cases, *test=kunlun * new may of test cases, *test=kunlun * new may of test cases, *test=kunlun * [PTen] Add HasAttr for ArgumentMappingContext (PaddlePaddle#39464) * add has_attr for arg map context * skip useless attr now * skip attr if not exists * fix typo * [ROCm] fix missing dcu kernel in operator.cmake, test=develop (PaddlePaddle#39480) Co-authored-by: zyfncg <[email protected]> Co-authored-by: Aganlengzi <[email protected]> Co-authored-by: Chen Weihang <[email protected]> Co-authored-by: Leo Chen <[email protected]> Co-authored-by: zhangbo9674 <[email protected]> Co-authored-by: crystal <[email protected]> Co-authored-by: Zhanlue Yang <[email protected]> Co-authored-by: sneaxiy <[email protected]> Co-authored-by: wenbin <[email protected]> Co-authored-by: Wilber <[email protected]> Co-authored-by: hong <[email protected]> Co-authored-by: chenyanlann <[email protected]> Co-authored-by: Wei Shengyu <[email protected]> Co-authored-by: TeFeng Chen <[email protected]> Co-authored-by: furnace <[email protected]> Co-authored-by: fwenguang <[email protected]> Co-authored-by: 0x45f <[email protected]> Co-authored-by: Zhang Ting <[email protected]> Co-authored-by: chenjian <[email protected]> Co-authored-by: Shang Zhizhou <[email protected]> Co-authored-by: liutiexing <[email protected]> Co-authored-by: liutiexing <[email protected]> Co-authored-by: Wangzheee <[email protected]> Co-authored-by: ziyoujiyi <[email protected]> Co-authored-by: zkh2016 <[email protected]> Co-authored-by: zhangchunle <[email protected]> Co-authored-by: JingZhuangzhuang <[email protected]> Co-authored-by: Lijunhui <[email protected]> Co-authored-by: Zhang Zheng <[email protected]> Co-authored-by: Feiyu Chan <[email protected]> Co-authored-by: zn <[email protected]> Co-authored-by: zhangna <[email protected]> Co-authored-by: joeqiao12 <[email protected]> Co-authored-by: jakpiase <[email protected]> Co-authored-by: Leo Chen <[email protected]> Co-authored-by: Chen Weihang <[email protected]> Co-authored-by: Qi Li <[email protected]> Co-authored-by: maxhuiy <[email protected]> Co-authored-by: TTerror <[email protected]> Co-authored-by: chentianyu03 <[email protected]> Co-authored-by: helen88 <[email protected]>
PR types
New features
PR changes
OPs
Describe
add mlu kernel for accuracy op