[hybrid] remove scale op in insert_scale_loss_grad_ops#35775
[hybrid] remove scale op in insert_scale_loss_grad_ops#35775wangxicoding merged 2 commits intoPaddlePaddle:developfrom
Conversation
|
Thanks for your contribution! |
 sandyhouse
left a comment
sandyhouse
left a comment
There was a problem hiding this comment.
LGTM for code modification, but I think after this modification, the program description maybe confusing for others.
Might need a comment to notify the later maintainer that the start point of gradient backward would change according to the DataParallel and ShardingParallel degree. |
OK,add in next PR. |
| "loss_grad_op must be fill_constant op, " \ | ||
| "but this op is {}".format(op.type) | ||
| assert op.has_attr('value') | ||
| loss_scale = float(op.attr('value')) |
There was a problem hiding this comment.
Mind the potential precision loss here. fill_constant op will cast the value into fp32 and then save as string into its OpDesc. reload & reset this value might cause precision loss when the denominator is odd (3,7, 11, etc)
There was a problem hiding this comment.

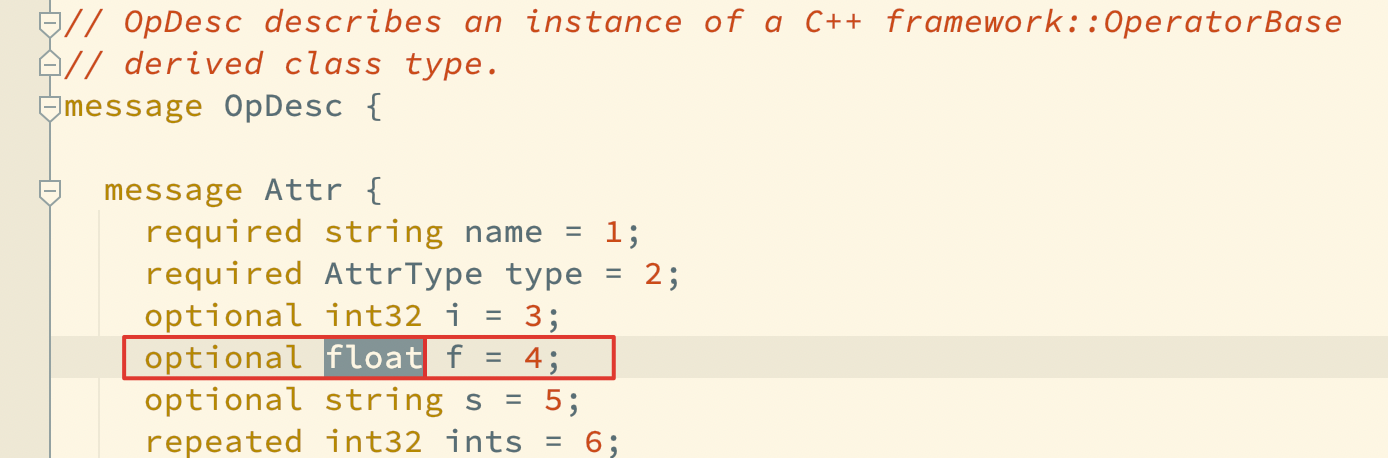
loss_grad_op(that is fill_constant) use value instead of str_value, which AttrType is float. value will be saved with float32 in protobuf. If we encount precision problem, I this this must be caused by float AttrType, and I think double AttrType is better, which framework does not provide.
There was a problem hiding this comment.

the type of op.attr('value') is already float64 in python, add float(op.attr('value')) is only for explicit.
PR types
Performance optimization
PR changes
Others
Describe
移除insert_scale_loss_grad_ops中插入的scale op,直接取出loss_grad_op也即fill_constant中的value值修改,可减少插入scale op的个数。理论可以提高一小丢丢丢性能。
测试
Ernei3.0,base模型
后续优化TODO
pipeline里面可以将loss_grad_op放到LRSchedule里,一个step只执行一次,而非每个micro-step都执行。或者更激进点,设置为persistable,在startup_program里面初始化,一次训练只执行一次。