[NPU] flatten params and grads, fuse grad_clip and optimizer op#33461
Merged
zhiqiu merged 10 commits intoPaddlePaddle:developfrom Jun 21, 2021
Merged
[NPU] flatten params and grads, fuse grad_clip and optimizer op#33461zhiqiu merged 10 commits intoPaddlePaddle:developfrom
zhiqiu merged 10 commits intoPaddlePaddle:developfrom
Conversation
|
Thanks for your contribution! |
Contributor
|
paddle/optimzier/optimizer.py是不是也需要同步修改? |
python/paddle/fluid/optimizer.py
Outdated
| """ | ||
| Args: | ||
| flatten_param_grads (bool, optional): Whether to flatten all the parameters and grads. | ||
| If true, the parameters and gradients will be coalesce to continue mempry, |
Contributor
There was a problem hiding this comment.
continue mempry -> contiguous memory
phlrain
approved these changes
Jun 21, 2021
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
3 participants
Add this suggestion to a batch that can be applied as a single commit.This suggestion is invalid because no changes were made to the code.Suggestions cannot be applied while the pull request is closed.Suggestions cannot be applied while viewing a subset of changes.Only one suggestion per line can be applied in a batch.Add this suggestion to a batch that can be applied as a single commit.Applying suggestions on deleted lines is not supported.You must change the existing code in this line in order to create a valid suggestion.Outdated suggestions cannot be applied.This suggestion has been applied or marked resolved.Suggestions cannot be applied from pending reviews.Suggestions cannot be applied on multi-line comments.Suggestions cannot be applied while the pull request is queued to merge.Suggestion cannot be applied right now. Please check back later.
PR types
Performance optimization
PR changes
OPs
Describe
[NPU] flatten params and grads, fuse grad_clip and optimizer op
For example,
ernie-3.0model has 300+ parameters, and thus 300+ gradients of parameters.Each training step, the program has to perform grad_clip the gradient and update the parameter. So, there are 300+ grad_clip operators and 300+ optimizer operators.
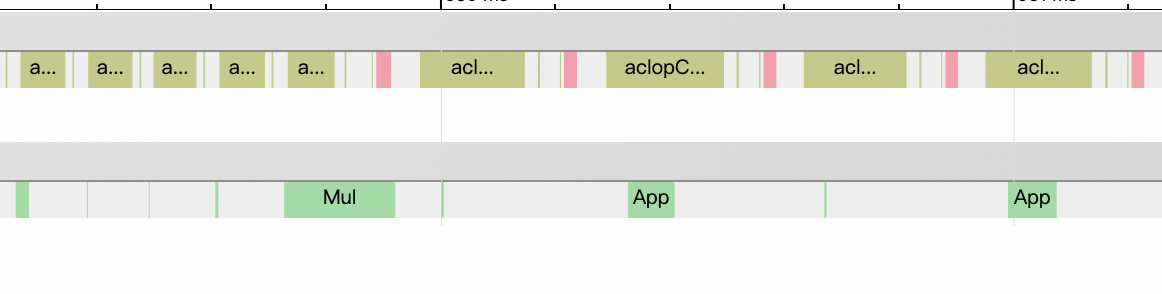
This PR tries to flatten all the parameters into one continuous memory space and also flatten the gradients. After that, some of the gradient clip and optimizer can be done by 1 time on the flattened parameter/gradient.

Currently,
Adam + ClipByGlobalNormis supported.Performance
ernie-3.0, bs=20480, training speed: 20684->23583 tokens/s, +13.8%