Enable the convolution/relu6(bounded_relu) fusion for FP32 on Intel platform.#17130
Enable the convolution/relu6(bounded_relu) fusion for FP32 on Intel platform.#17130luotao1 merged 8 commits intoPaddlePaddle:developfrom guomingz:conv_relu6_fusion_fp32
Conversation
…he conv/relu6 fusion, we implement it fusion via cpass way. Due to the int8 enabling for this fusion will be supported in MKLDNN v0.20, so this PR is focused on the fp32 optimization. Below table shows the benchmark(FPS) which measured on skx-8180(28 cores) Batch size | with fusion | without fusion -- | -- | -- 1 | 214.7 | 53.4 50 | 1219.727 | 137.280 test=develop
test=develop
test=develop
|
it's weird that PR ran PR_CI (Paddle) for several times, even the previous one was successful, it will rerun again. |
|
hi @luotao1 , it seems that intel folks may on vacation or busy to review this PR. Is it possible to ask baidu folks review this PR? Thanks |
test=develop
|
hi @luotao1 , the review from Intel Internal is done. Please have a review if needed. |
|
hi @luotao1 the review had done. Shall we need to invite Baidu folks to review it? thank you in advance. |
 sfraczek
left a comment
sfraczek
left a comment
There was a problem hiding this comment.
Please add the pass to paddle_pass_builder.cc:
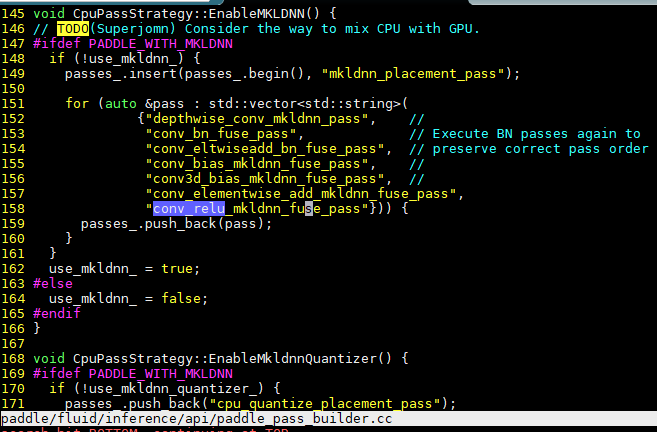
Thank you for reminder. Just register this pass for the mkldnn engine. Please have a review:) |
test=develop
Thanks for hint. I was confused the clang-format output without your hints. It's a subtle way to adjust the indentation. Let me update the code for better style. |
|
|
||
| PADDLE_ENFORCE(is_conv3d != true, "int8 does not support conv3d currently"); | ||
| PADDLE_ENFORCE(fuse_brelu != true, | ||
| "int8 does not support conv/relu6 fusion currently"); |
There was a problem hiding this comment.
Why doesn't int8 support conv/relu6 fusion? It is to be done or not doable ?
There was a problem hiding this comment.
Why doesn't int8 support conv/relu6 fusion? It is to be done or not doable ?
mkldnn v0.20 will support it.
There was a problem hiding this comment.
@guomingz
Vadim Pirogov from MKL-DNN team has confirmed that INT8 support for conv2d + relu6 post-op is already present in 0.18.
There was a problem hiding this comment.
Hi! @guomingz We just checked INT8 conv2d + relu6 fuse also works for MobileNetV2 and brings good accuracy and performance improvement. Thank you very much for this PR!
There was a problem hiding this comment.
Hi! @guomingz We just checked INT8 conv2d + relu6 fuse also works for MobileNetV2 and brings good accuracy and performance improvement. Thank you very much for this PR!
hi @lidanqing-intel @wojtuss . Thanks for your comments. Actually, we already enabled the conv/relu6 int8 part in our local repo. But during the pre-ci, we found one potential issue that blocks the pre-ci. You may access the https://jira.devtools.intel.com/projects/MFDNN/issues/MFDNN-1552 for more details. That's the reason we only create the fp32 part PR.
There was a problem hiding this comment.
@guomingz , maybe the INT8 conv+relu6 does not work with grouped convolutions? In MobileNetV2 there are no grouped convolutions and it works fine with INT8. If that is the case, you could exclude only grouped convolutions until 0.20 supports it.
There was a problem hiding this comment.
@guomingz , maybe the INT8 conv+relu6 does not work with grouped convolutions? In MobileNetV2 there are no grouped convolutions and it works fine with INT8. If that is the case, you could exclude only grouped convolutions until 0.20 supports it.
As the paddlepaddle pre-ci has group-convolution testing which would block the rest checker. So we don't enable it at the current stage.
If you or your team consider this is as the must-have feature ,we may create another PR for int8 only? How do u think? Besides that, we need to allocate the resources for it .@hshen14 will explain the details.
|
I found one more thing. You haven't added a test for the fuse for completeness. |
test=develop
hello @sfraczek . I just added the test_conv_brelu_mkldnn_fuse_pass case per your comments. Please have a review on that. Thanks. |
| AddAttr<bool>("fuse_brelu", | ||
| "(bool, default false) Only used in mkldnn kernel") | ||
| .SetDefault(false); | ||
| AddAttr<float>("fuse_brelu_threshold", |
There was a problem hiding this comment.
Why need fuse_brelu_threshold?
There was a problem hiding this comment.
Why need
fuse_brelu_threshold?
It's a parameter of bounded ReLU. 6 is the typical value but it may vary.
There was a problem hiding this comment.
@luotao1 , relu6 is a case of bounded_relu op in which 6 is the default value of the threshold parameter.
There was a problem hiding this comment.
Hi, when will this PR be merged ? :)
There was a problem hiding this comment.
@qingqing01 How do you see this PR add two attributes fuse_brelu and fuse_brelu_threshold?
|
CLA has some problem several hours ago, you can close and reopen this PR again. Then CLA will be triggered successfully. |
|
Does the attr |
it's up to the topology itself. If someday one invents another topology, which use another threshold for bounded relu, it will change accordingly. What i mean is this field is not modified by the users, it's just attribute. |
|
@luotao1 , the |
|
|
||
| conv_pd = ConvFwdPrimitiveDesc( | ||
| src_md, weights_md, bias_md, dst_md, strides, paddings, | ||
| mkldnn_engine, fuse_relu, fuse_residual_conn, false, 0.0, |
There was a problem hiding this comment.
- false means
fuse_brelu? - 0.0 means
fuse_brelu_threshold?
It's hard to understand.
There was a problem hiding this comment.
They're placeholder as int8 fusion was not enabling if you read the previous conversation. It will be removed once the int8 is enabled.
There was a problem hiding this comment.
You can write
false /*xxx */, 0.0 /*xxx*/
There was a problem hiding this comment.
You can write
false /*xxx */, 0.0 /*xxx*/
updated the code!
There was a problem hiding this comment.
Got it. But the default of fuse_brelu_threshold is 6.0, why here is 0.0?
There was a problem hiding this comment.
Got it. But the default of
fuse_brelu_thresholdis 6.0, why here is 0.0?
0.0 implys the int8 brelu fusion is not enabled as the brelu flag set to false. 6.0 may cause potential misleading on brelu fusion status.
| platform::ConvMKLDNNHandler::AppendKey( | ||
| &key, src_tz, weights_tz, strides, paddings, dilations, groups, src_dt, | ||
| input->format(), fuse_relu, fuse_residual_conn, | ||
| input->format(), fuse_relu, fuse_residual_conn, false, |
There was a problem hiding this comment.
What's the meaning of false? It's hard to understand.
| output_shift_scale, sum_scale, is_test); | ||
| conv_pd = ConvFwdPrimitiveDesc(src_md, weights_md, dst_md, strides, | ||
| paddings, mkldnn_engine, fuse_relu, | ||
| fuse_residual_conn, false, 0.0, |
| conv_transpose_pd = handler.AcquireConvolutionPrimitiveDescriptor( | ||
| src_md, weights_md, bias_md, dst_md, strides, paddings, mkldnn_engine, | ||
| fuse_relu, false, fwd_prop_kind); | ||
| fuse_relu, false, false, 0.0, fwd_prop_kind); |
| conv_transpose_pd = handler.AcquireConvolutionPrimitiveDescriptor( | ||
| src_md, weights_md, boost::none, dst_md, strides, paddings, | ||
| mkldnn_engine, fuse_relu, false, fwd_prop_kind); | ||
| mkldnn_engine, fuse_relu, false, false, 0.0, fwd_prop_kind); |
|
please add mobilenet v2 ut said in #17468 (comment) |
we've added the feature-level ut yet. How about ask the Poland team to raise the mobilenet-v2 ut in another PR? Let's this PR focus on feature itself. |
|
@luotao1 , @guomingz , could you please reply also to #17130 (comment) |
Let the parameter definition embedded into the code. That's will make the code easy to understand. test=develop
|
@guomingz @hshen14 please answer #17130 (comment) |
|
This PR is to support Conv and BoundedReLU fusion in FP32 with the required pass-based graph optimization and op-level unit test. If you encounter the issue when applying the fusion in INT8, I would suggest you could create another PR per your need and add some comments to explain the limitation. |
Relu6 is the bottleneck op for Mobilenet-v2. As the mkldnn supports the conv/relu6 fusion, we implement it fusion via cpass way. Due to the int8 enabling for this fusion will be supported in MKLDNN v0.20, so this PR is focused on the fp32 optimization.
Below table shows the benchmark(FPS) which measured on skx-8180(28 cores)
test=develop