VGG16 convergence comparison on GPU between fluid and tensorflow #6813
Description
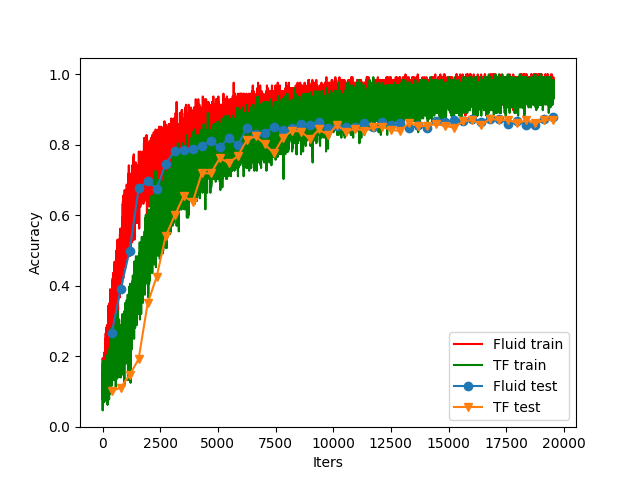
- Data set: cifar10
- Epochs: 50
- Batch size: 128
- Optimizer: Adam
- Learning rate = 1e-3
- Conclusion: Fluid converges a bit faster and they get very close accuracy after adequate training