{kind=link}
这是一个功能强大的Python脚本,旨在将您在有道词典中收藏的单词列表,通过AI技术,自动扩充和排版成一本专业、美观、可直接打印的A4单词书。
它不仅仅是一个简单的格式转换工具,更是一个集成了AI内容增强、高级缓存、以及科学级3D数据可视化于一体的完整解决方案。
-
🤖 AI驱动的内容扩充:
- 自动调用兼容OpenAI接口的大语言模型(LLM),为每个单词生成详细、高质量的学习资料。
- 内容包括:英美音标、多重释义(核心词义加粗)、可数性/动词变位、近义词、常见短语、固定搭配、以及针对性例句。
- AI会根据单词特性,智能添加特殊提示,并评估单词难度(1-5星)。
-
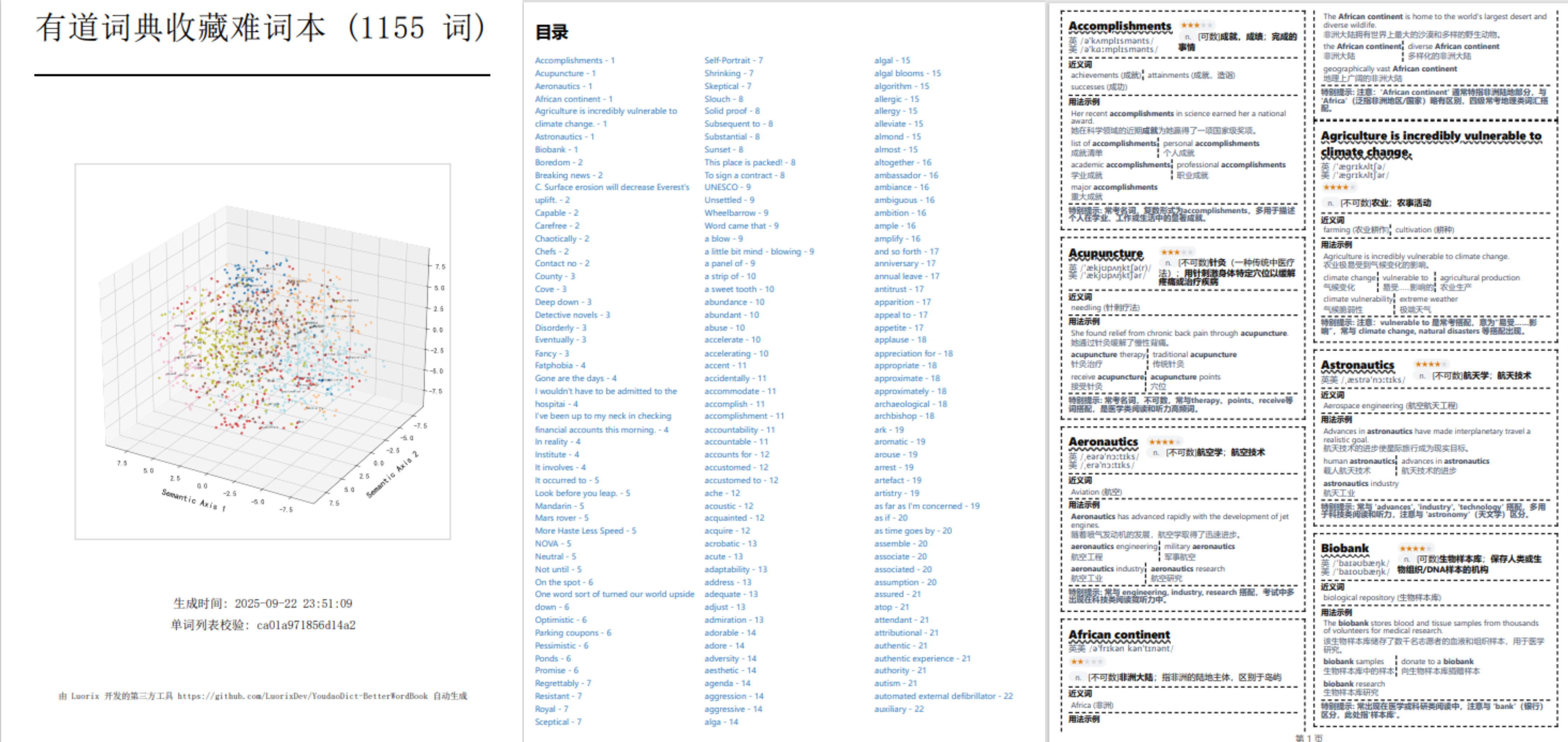
🔬 科学级3D词向量可视化:
- 在单词书的封面上,自动生成一张艺术化、信息量丰富的3D词向量“星图”。
- 自适应语义聚类: 利用
K-Means和**“肘部法则”**,智能地将单词按语义关联进行聚类,无需任何手动配置。 - 专业数据处理: 采用
t-SNE降维和MinMaxScaler数据归一化,确保数据点在3D空间中分布均匀、清晰可读。 - 精细化视觉调优: 自动裁剪图像边距、优化渲染层级(确保标签不被遮挡)、并完美支持中文字体显示。
-
⚡️ 增量式智能缓存:
- 为AI释义查询和词向量计算配备了双重缓存系统。
- 再次运行时,只会为新单词请求AI或计算词向量,极大地节省了时间和API成本。
- 支持配置缓存保存间隔,有效防止因意外中断造成的数据丢失。
-
🎨 高度可定制的HTML模板:
- 单词书的封面和内页样式,完全由独立的HTML模板文件 (
cover_template.html,word_book_template.html) 控制。 - 您可以自由修改模板的HTML和CSS,打造完全符合您个人审美的单词书样式。
- 单词书的封面和内页样式,完全由独立的HTML模板文件 (
-
🖨️ 专业打印排版:
- 生成的HTML文件为标准的A4纵向布局,优化了分页逻辑,可直接通过浏览器“打印”功能,生成高质量的PDF或纸质版。
- 自动生成包含封面、目录、以及单词详情的完整单词书结构。
-
🛠️ 健壮的工程化设计:
- 配置驱动: 所有关键参数(API密钥、模型名称、文件路径等)均通过
config.json进行管理。 - AI稳定性保障: 内置API请求重试、流式响应处理、以及防AI死循环的超长响应截断机制。
- 数据清洗工具: 附带独立的
clean_json_data.py脚本,用于预处理您的原始数据。
- 配置驱动: 所有关键参数(API密钥、模型名称、文件路径等)均通过
-
克隆仓库:
git clone https://github.com/LuorixDev/YoudaoDict-BetterWordBook.git cd YoudaoDict-BetterWordBook -
安装依赖:
pip install -r requirements.txt
注意: 如果您在中国大陆,可以考虑使用清华镜像源加速安装:
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple -
创建配置文件:
- 将
config.example.json复制一份,并重命名为config.json。 - 打开
config.json,填入您自己的配置,特别是您的API密钥 (api_key) 和模型终端节点 (api_endpoint,embedding_api_endpoint)。
- 将
-
准备数据文件:
-
将您从有道词典导出的单词本JSON文件,替换掉项目中的
example.json。 -
example.json的获取方式:
-
1.安装好
wireshark和安卓模拟器 -
2.在
安卓模拟器内部安装“有道智慧学习”并登陆 -
3.开启
wireshark开始抓包,可以在左上角筛选处只筛选HTTP请求(有道客户端获取收藏夹是一个GET请求) -
4.点击主页的
单词本按钮(即查看词典笔收藏) -
5.回到
wireshark找到如图的请求,右键追踪流,选择TCP或者HTTP均可,就可以获取到JSON啦,只需要把完整的JSON部分放到example.json中即可 -

-
确保文件名与您在
config.json中input_file字段的设置保持一致。
-
如果您的单词本中包含中文或其他非英文条目,可以运行数据清洗脚本来移除它们。脚本会自动备份原始文件。
python clean_json_data.py一切准备就绪后,运行主程序:
python main.py脚本会自动开始处理您的单词列表。完成后,您将在项目根目录下找到在config.json中指定的HTML输出文件(默认为word_book.html)。
| 键 (Key) | 说明 |
|---|---|
api_key |
[必需] 您的AI服务API密钥。 |
api_endpoint |
[必需] 用于获取单词释义的LLM聊天API终端。 |
ai_model |
用于获取单词释义的LLM模型名称。 |
input_file |
输入的原始单词数据JSON文件路径。 |
output_file |
输出的HTML单词书文件路径。 |
cover_template_file |
封面HTML模板的路径。 |
word_book_template_file |
单词内页HTML模板的路径。 |
word_details_cache_file |
AI释义的缓存文件路径。 |
embeddings_cache_file |
词向量的缓存文件路径。 |
cache_save_interval |
处理多少个新单词后,自动保存一次缓存。 |
ai_response_max_length |
AI响应的最大长度限制,用于防止死循环。 |
embedding_model |
用于生成词向量的Embedding模型名称。 |
embedding_api_endpoint |
[必需] 用于获取词向量的Embedding API终端。 |
embedding_batch_size |
批量获取词向量时,每批包含的单词数量。 |
- AI & 数据处理:
requests,numpy,scikit-learn,kneed - 3D 可视化:
matplotlib - 进度显示:
tqdm
由 Luorix 开发的第三方工具,祝您学习愉快!