diff --git a/docs/source/_toctree.yml b/docs/source/_toctree.yml
index 2532f3a4ef4..589761a1f6d 100644
--- a/docs/source/_toctree.yml
+++ b/docs/source/_toctree.yml
@@ -10,15 +10,15 @@
- local: installation
title: Installation
- local: load_hub
- title: Hugging Face Hub
+ title: Load a dataset from the Hub
- local: access
- title: The Dataset object
+ title: Know your dataset
- local: use_dataset
- title: Train with 🤗 Datasets
+ title: Preprocess
- local: metrics
title: Evaluate predictions
- local: upload_dataset
- title: Upload a dataset to the Hub
+ title: Share a dataset to the Hub
title: "Tutorials"
- sections:
- local: how_to
diff --git a/docs/source/access.mdx b/docs/source/access.mdx
index 0984d79ae9e..662ffa41eca 100644
--- a/docs/source/access.mdx
+++ b/docs/source/access.mdx
@@ -1,126 +1,81 @@
-# The Dataset object
+# Know your dataset
-In the previous tutorial, you learned how to successfully load a dataset. This section will familiarize you with the [`Dataset`] object. You will learn about the metadata stored inside a Dataset object, and the basics of querying a Dataset object to return rows and columns.
-
-A [`Dataset`] object is returned when you load an instance of a dataset. This object behaves like a normal Python container.
+When you load a dataset split, you'll get a [`Dataset`] object. You can do many things with a [`Dataset`] object, which is why it's important to learn how to manipulate and interact with the data stored inside.
+
+This tutorial uses the [rotten_tomatoes](https://huggingface.co/datasets/rotten_tomatoes) dataset, but feel free to load any dataset you'd like and follow along!
```py
>>> from datasets import load_dataset
->>> dataset = load_dataset('glue', 'mrpc', split='train')
-```
-
-## Metadata
-The [`Dataset`] object contains a lot of useful information about your dataset. For example, access [`DatasetInfo`] to return a short description of the dataset, the authors, and even the dataset size. This will give you a quick snapshot of the datasets most important attributes.
-
-```py
->>> dataset.info
-DatasetInfo(
- description='GLUE, the General Language Understanding Evaluation benchmark\n(https://gluebenchmark.com/) is a collection of resources for training,\nevaluating, and analyzing natural language understanding systems.\n\n',
- citation='@inproceedings{dolan2005automatically,\n title={Automatically constructing a corpus of sentential paraphrases},\n author={Dolan, William B and Brockett, Chris},\n booktitle={Proceedings of the Third International Workshop on Paraphrasing (IWP2005)},\n year={2005}\n}\n@inproceedings{wang2019glue,\n title={{GLUE}: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding},\n author={Wang, Alex and Singh, Amanpreet and Michael, Julian and Hill, Felix and Levy, Omer and Bowman, Samuel R.},\n note={In the Proceedings of ICLR.},\n year={2019}\n}\n', homepage='https://www.microsoft.com/en-us/download/details.aspx?id=52398',
- license='',
- features={'sentence1': Value(dtype='string', id=None), 'sentence2': Value(dtype='string', id=None), 'label': ClassLabel(num_classes=2, names=['not_equivalent', 'equivalent'], names_file=None, id=None), 'idx': Value(dtype='int32', id=None)}, post_processed=None, supervised_keys=None, builder_name='glue', config_name='mrpc', version=1.0.0, splits={'train': SplitInfo(name='train', num_bytes=943851, num_examples=3668, dataset_name='glue'), 'validation': SplitInfo(name='validation', num_bytes=105887, num_examples=408, dataset_name='glue'), 'test': SplitInfo(name='test', num_bytes=442418, num_examples=1725, dataset_name='glue')},
- download_checksums={'https://dl.fbaipublicfiles.com/glue/data/mrpc_dev_ids.tsv': {'num_bytes': 6222, 'checksum': '971d7767d81b997fd9060ade0ec23c4fc31cbb226a55d1bd4a1bac474eb81dc7'}, 'https://dl.fbaipublicfiles.com/senteval/senteval_data/msr_paraphrase_train.txt': {'num_bytes': 1047044, 'checksum': '60a9b09084528f0673eedee2b69cb941920f0b8cd0eeccefc464a98768457f89'}, 'https://dl.fbaipublicfiles.com/senteval/senteval_data/msr_paraphrase_test.txt': {'num_bytes': 441275, 'checksum': 'a04e271090879aaba6423d65b94950c089298587d9c084bf9cd7439bd785f784'}},
- download_size=1494541,
- post_processing_size=None,
- dataset_size=1492156,
- size_in_bytes=2986697
-)
-```
-
-You can request specific attributes of the dataset, like `description`, `citation`, and `homepage`, by calling them directly. Take a look at [`DatasetInfo`] for a complete list of attributes you can return.
-
-```py
->>> dataset.split
-NamedSplit('train')
->>> dataset.description
-'GLUE, the General Language Understanding Evaluation benchmark\n(https://gluebenchmark.com/) is a collection of resources for training,\nevaluating, and analyzing natural language understanding systems.\n\n'
->>> dataset.citation
-'@inproceedings{dolan2005automatically,\n title={Automatically constructing a corpus of sentential paraphrases},\n author={Dolan, William B and Brockett, Chris},\n booktitle={Proceedings of the Third International Workshop on Paraphrasing (IWP2005)},\n year={2005}\n}\n@inproceedings{wang2019glue,\n title={{GLUE}: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding},\n author={Wang, Alex and Singh, Amanpreet and Michael, Julian and Hill, Felix and Levy, Omer and Bowman, Samuel R.},\n note={In the Proceedings of ICLR.},\n year={2019}\n}\n\nNote that each GLUE dataset has its own citation. Please see the source to see\nthe correct citation for each contained dataset.'
->>> dataset.homepage
-'https://www.microsoft.com/en-us/download/details.aspx?id=52398'
+>>> dataset = load_dataset("rotten_tomatoes", split="train")
```
-## Features and columns
+## Indexing
-A dataset is a table of rows and typed columns. Querying a dataset returns a Python dictionary where the keys correspond to column names, and the values correspond to column values:
+A [`Dataset`] contains columns of data, and each column can be a different type of data. The *index*, or axis label, is used to access examples from the dataset. For example, indexing by the row returns a dictionary of an example from the dataset:
```py
+# Get the first row in the dataset
>>> dataset[0]
-{'idx': 0,
-'label': 1,
-'sentence1': 'Amrozi accused his brother , whom he called " the witness " , of deliberately distorting his evidence .',
-'sentence2': 'Referring to him as only " the witness " , Amrozi accused his brother of deliberately distorting his evidence .'}
+{'label': 1,
+ 'text': 'the rock is destined to be the 21st century\'s new " conan " and that he\'s going to make a splash even greater than arnold schwarzenegger , jean-claud van damme or steven segal .'}
```
-Return the number of rows and columns with the following standard attributes:
+Use the `-` operator to start from the end of the dataset:
```py
->>> dataset.shape
-(3668, 4)
->>> dataset.num_columns
-4
->>> dataset.num_rows
-3668
->>> len(dataset)
-3668
+# Get the last row in the dataset
+>>> dataset[-1]
+{'label': 0,
+ 'text': 'things really get weird , though not particularly scary : the movie is all portent and no content .'}
```
-List the columns names with [`Dataset.column_names`]:
+Indexing by the column name returns a list of all the values in the column:
```py
->>> dataset.column_names
-['idx', 'label', 'sentence1', 'sentence2']
+>>> dataset["text"]
+['the rock is destined to be the 21st century\'s new " conan " and that he\'s going to make a splash even greater than arnold schwarzenegger , jean-claud van damme or steven segal .',
+ 'the gorgeously elaborate continuation of " the lord of the rings " trilogy is so huge that a column of words cannot adequately describe co-writer/director peter jackson\'s expanded vision of j . r . r . tolkien\'s middle-earth .',
+ 'effective but too-tepid biopic',
+ ...,
+ 'things really get weird , though not particularly scary : the movie is all portent and no content .']
```
-Get detailed information about the columns with [`~datasets.Features`]:
+You can combine row and column name indexing to return a specific value at a position:
```py
->>> dataset.features
-{'idx': Value(dtype='int32', id=None),
- 'label': ClassLabel(num_classes=2, names=['not_equivalent', 'equivalent'], names_file=None, id=None),
- 'sentence1': Value(dtype='string', id=None),
- 'sentence2': Value(dtype='string', id=None),
-}
+>>> dataset[0]["text"]
+'the rock is destined to be the 21st century\'s new " conan " and that he\'s going to make a splash even greater than arnold schwarzenegger , jean-claud van damme or steven segal .'
```
-Return even more specific information about a feature like [`ClassLabel`], by calling its parameters `num_classes` and `names`:
+But it is important to remember that indexing order matters, especially when working with large audio and image datasets. Indexing by the column name returns all the values in the column first, then loads the value at that position. For large datasets, it may be slower to index by the column name first.
```py
->>> dataset.features['label'].num_classes
-2
->>> dataset.features['label'].names
-['not_equivalent', 'equivalent']
+>>> with Timer():
+... dataset[0]['text']
+Elapsed time: 0.0031 seconds
+
+>>> with Timer():
+... dataset["text"][0]
+Elapsed time: 0.0094 seconds
```
-## Rows, slices, batches, and columns
+## Slicing
-Get several rows of your dataset at a time with slice notation or a list of indices:
+Slicing returns a slice - or subset - of the dataset, which is useful for viewing several rows at once. To slice a dataset, use the `:` operator to specify a range of positions.
```py
+# Get the first three rows
>>> dataset[:3]
-{'idx': [0, 1, 2],
- 'label': [1, 0, 1],
- 'sentence1': ['Amrozi accused his brother , whom he called " the witness " , of deliberately distorting his evidence .', "Yucaipa owned Dominick 's before selling the chain to Safeway in 1998 for $ 2.5 billion .", 'They had published an advertisement on the Internet on June 10 , offering the cargo for sale , he added .'],
- 'sentence2': ['Referring to him as only " the witness " , Amrozi accused his brother of deliberately distorting his evidence .', "Yucaipa bought Dominick 's in 1995 for $ 693 million and sold it to Safeway for $ 1.8 billion in 1998 .", "On June 10 , the ship 's owners had published an advertisement on the Internet , offering the explosives for sale ."]
-}
->>> dataset[[1, 3, 5]]
-{'idx': [1, 3, 5],
- 'label': [0, 0, 1],
- 'sentence1': ["Yucaipa owned Dominick 's before selling the chain to Safeway in 1998 for $ 2.5 billion .", 'Around 0335 GMT , Tab shares were up 19 cents , or 4.4 % , at A $ 4.56 , having earlier set a record high of A $ 4.57 .', 'Revenue in the first quarter of the year dropped 15 percent from the same period a year earlier .'],
- 'sentence2': ["Yucaipa bought Dominick 's in 1995 for $ 693 million and sold it to Safeway for $ 1.8 billion in 1998 .", 'Tab shares jumped 20 cents , or 4.6 % , to set a record closing high at A $ 4.57 .', "With the scandal hanging over Stewart 's company , revenue the first quarter of the year dropped 15 percent from the same period a year earlier ."]
-}
-```
-
-Querying by the column name will return its values. For example, if you want to only return the first three examples:
-
-```py
->>> dataset['sentence1'][:3]
-['Amrozi accused his brother , whom he called " the witness " , of deliberately distorting his evidence .', "Yucaipa owned Dominick 's before selling the chain to Safeway in 1998 for $ 2.5 billion .", 'They had published an advertisement on the Internet on June 10 , offering the cargo for sale , he added .']
-```
-
-Depending on how a [`Dataset`] object is queried, the format returned will be different:
-
-- A single row like `dataset[0]` returns a Python dictionary of values.
-- A batch like `dataset[5:10]` returns a Python dictionary of lists of values.
-- A column like `dataset['sentence1']` returns a Python list of values.
\ No newline at end of file
+{'label': [1, 1, 1],
+ 'text': ['the rock is destined to be the 21st century\'s new " conan " and that he\'s going to make a splash even greater than arnold schwarzenegger , jean-claud van damme or steven segal .',
+ 'the gorgeously elaborate continuation of " the lord of the rings " trilogy is so huge that a column of words cannot adequately describe co-writer/director peter jackson\'s expanded vision of j . r . r . tolkien\'s middle-earth .',
+ 'effective but too-tepid biopic']}
+
+# Get rows between three and six
+>>> dataset[3:6]
+{'label': [1, 1, 1],
+ 'text': ['if you sometimes like to go to the movies to have fun , wasabi is a good place to start .',
+ "emerges as something rare , an issue movie that's so honest and keenly observed that it doesn't feel like one .",
+ 'the film provides some great insight into the neurotic mindset of all comics -- even those who have reached the absolute top of the game .']}
+```
\ No newline at end of file
diff --git a/docs/source/load_hub.mdx b/docs/source/load_hub.mdx
index 4f8c1c1acf6..b36662fb4da 100644
--- a/docs/source/load_hub.mdx
+++ b/docs/source/load_hub.mdx
@@ -1,103 +1,101 @@
-# Hugging Face Hub
+# Load a dataset from the Hub
-Now that you are all setup, the first step is to load a dataset. The easiest way to load a dataset is from the [Hugging Face Hub](https://huggingface.co/datasets). There are already over 6000 datasets in over 100 languages on the Hub. Choose from a wide category of datasets to use for NLP tasks like question answering, summarization, machine translation, and language modeling.
+Finding high-quality datasets that are reproducible and accessible can be difficult. One of 🤗 Datasets main goals is to provide a simple way to load a dataset of any format or type. The easiest way to get started is to discover an existing dataset on the [Hugging Face Hub](https://huggingface.co/datasets) - a community-driven collection of datasets for tasks in NLP, computer vision, and audio - and use 🤗 Datasets to download and generate the dataset.
+
+This tutorial uses the [rotten_tomatoes](https://huggingface.co/datasets/rotten_tomatoes) and [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) datasets, but feel free to load any dataset you want and follow along. Head over to the Hub now and find a dataset for your task!
## Load a dataset
-Before you take the time to download a dataset, it is often helpful to quickly get all the relevant information about a dataset. The [`load_dataset_builder`] method allows you to inspect the attributes of a dataset without downloading it.
+Before you take the time to download a dataset, it's often helpful to quickly get some general information about a dataset. A dataset's information is stored inside [`DatasetInfo`] and can include information such as the dataset description, features, and dataset size.
+
+Use the [`load_dataset_builder`] function to load a dataset builder and inspect a dataset's attributes without committing to downloading it:
```py
>>> from datasets import load_dataset_builder
->>> dataset_builder = load_dataset_builder('imdb')
->>> print(dataset_builder.cache_dir)
-/Users/thomwolf/.cache/huggingface/datasets/imdb/plain_text/1.0.0/fdc76b18d5506f14b0646729b8d371880ef1bc48a26d00835a7f3da44004b676
->>> print(dataset_builder.info.features)
-{'text': Value(dtype='string', id=None), 'label': ClassLabel(num_classes=2, names=['neg', 'pos'], names_file=None, id=None)}
->>> print(dataset_builder.info.splits)
-{'train': SplitInfo(name='train', num_bytes=33432835, num_examples=25000, dataset_name='imdb'), 'test': SplitInfo(name='test', num_bytes=32650697, num_examples=25000, dataset_name='imdb'), 'unsupervised': SplitInfo(name='unsupervised', num_bytes=67106814, num_examples=50000, dataset_name='imdb')}
-```
+>>> ds_builder = load_dataset_builder("rotten_tomatoes")
-
+# Inspect dataset description
+>>> ds_builder.info.description
+Movie Review Dataset. This is a dataset of containing 5,331 positive and 5,331 negative processed sentences from Rotten Tomatoes movie reviews. This data was first used in Bo Pang and Lillian Lee, ``Seeing stars: Exploiting class relationships for sentiment categorization with respect to rating scales.'', Proceedings of the ACL, 2005.
-Take a look at [`DatasetInfo`] for a full list of attributes you can use with `dataset_builder`.
-
-
+# Inspect dataset features
+>>> ds_builder.info.features
+{'label': ClassLabel(num_classes=2, names=['neg', 'pos'], id=None),
+ 'text': Value(dtype='string', id=None)}
+```
-Once you are happy with the dataset you want, load it in a single line with [`load_dataset`]:
+If you're happy with the dataset, then load it with [`load_dataset`]:
```py
>>> from datasets import load_dataset
->>> dataset = load_dataset('glue', 'mrpc', split='train')
-```
-## Select a configuration
+>>> dataset = load_dataset("rotten_tomatoes", split="train")
+```
-Some datasets, like the [General Language Understanding Evaluation (GLUE)](https://huggingface.co/datasets/glue) benchmark, are actually made up of several datasets. These sub-datasets are called **configurations**, and you must explicitly select one when you load the dataset. If you don't provide a configuration name, 🤗 Datasets will raise a `ValueError` and remind you to select a configuration.
+## Splits
-Use the [`get_dataset_config_names`] function to retrieve a list of all the possible configurations available to your dataset:
+A split is a specific subset of a dataset like `train` and `test`. List a dataset's split names with the [`get_dataset_split_names`] function:
```py
-from datasets import get_dataset_config_names
+>>> from datasets import get_dataset_split_names
-configs = get_dataset_config_names("glue")
-print(configs)
-# ['cola', 'sst2', 'mrpc', 'qqp', 'stsb', 'mnli', 'mnli_mismatched', 'mnli_matched', 'qnli', 'rte', 'wnli', 'ax']
+>>> get_dataset_split_names("rotten_tomatoes")
+['train', 'validation', 'test']
```
-❌ Incorrect way to load a configuration:
+Then you can load a specific split with the `split` parameter. Loading a dataset `split` returns a [`Dataset`] object:
```py
>>> from datasets import load_dataset
->>> dataset = load_dataset('glue')
-ValueError: Config name is missing.
-Please pick one among the available configs: ['cola', 'sst2', 'mrpc', 'qqp', 'stsb', 'mnli', 'mnli_mismatched', 'mnli_matched', 'qnli', 'rte', 'wnli', 'ax']
-Example of usage:
- *load_dataset('glue', 'cola')*
+
+>>> dataset = load_dataset("rotten_tomatoes", split="train")
+>>> dataset
+Dataset({
+ features: ['text', 'label'],
+ num_rows: 8530
+})
```
-✅ Correct way to load a configuration:
+If you don't specify a `split`, 🤗 Datasets returns a [`DatasetDict`] object instead:
```py
->>> dataset = load_dataset('glue', 'sst2')
-Downloading and preparing dataset glue/sst2 (download: 7.09 MiB, generated: 4.81 MiB, total: 11.90 MiB) to /Users/thomwolf/.cache/huggingface/datasets/glue/sst2/1.0.0...
-Downloading: 100%|██████████████████████████████████████████████████████████████| 7.44M/7.44M [00:01<00:00, 7.03MB/s]
-Dataset glue downloaded and prepared to /Users/thomwolf/.cache/huggingface/datasets/glue/sst2/1.0.0. Subsequent calls will reuse this data.
->>> print(dataset)
-{'train': Dataset(schema: {'sentence': 'string', 'label': 'int64', 'idx': 'int32'}, num_rows: 67349),
- 'validation': Dataset(schema: {'sentence': 'string', 'label': 'int64', 'idx': 'int32'}, num_rows: 872),
- 'test': Dataset(schema: {'sentence': 'string', 'label': 'int64', 'idx': 'int32'}, num_rows: 1821)
-}
+>>> from datasets import load_dataset
+
+>>> dataset = load_dataset("rotten_tomatoes")
+DatasetDict({
+ train: Dataset({
+ features: ['text', 'label'],
+ num_rows: 8530
+ })
+ validation: Dataset({
+ features: ['text', 'label'],
+ num_rows: 1066
+ })
+ test: Dataset({
+ features: ['text', 'label'],
+ num_rows: 1066
+ })
+})
```
-## Select a split
+## Configurations
+
+Some datasets contain several sub-datasets. For example, the [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) dataset has several sub-datasets, each one containing audio data in a different language. These sub-datasets are known as *configurations*, and you must explicitly select one when loading the dataset. If you don't provide a configuration name, 🤗 Datasets will raise a `ValueError` and remind you to choose a configuration.
-A split is a specific subset of the dataset like `train` and `test`. Make sure you select a split when you load a dataset. If you don't supply a `split` argument, 🤗 Datasets will only return a dictionary containing the subsets of the dataset.
+Use the [`get_dataset_config_names`] function to retrieve a list of all the possible configurations available to your dataset:
```py
->>> from datasets import load_dataset
->>> datasets = load_dataset('glue', 'mrpc')
->>> print(datasets)
-{train: Dataset({
- features: ['idx', 'label', 'sentence1', 'sentence2'],
- num_rows: 3668
-})
-validation: Dataset({
- features: ['idx', 'label', 'sentence1', 'sentence2'],
- num_rows: 408
-})
-test: Dataset({
- features: ['idx', 'label', 'sentence1', 'sentence2'],
- num_rows: 1725
-})
-}
+>>> from datasets import get_dataset_config_names
+
+>>> configs = get_dataset_config_names("PolyAI/minds14")
+>>> print(configs)
+['cs-CZ', 'de-DE', 'en-AU', 'en-GB', 'en-US', 'es-ES', 'fr-FR', 'it-IT', 'ko-KR', 'nl-NL', 'pl-PL', 'pt-PT', 'ru-RU', 'zh-CN', 'all']
```
-You can list the split names for a dataset, or a specific configuration, with the [`get_dataset_split_names`] method:
+Then load the configuration you want:
```py
->>> from datasets import get_dataset_split_names
->>> get_dataset_split_names('sent_comp')
-['validation', 'train']
->>> get_dataset_split_names('glue', 'cola')
-['test', 'train', 'validation']
+>>> from datasets import load_dataset
+
+>>> mindsFR = load_dataset("PolyAI/minds14", "fr-FR", split="train")
```
diff --git a/docs/source/metrics.mdx b/docs/source/metrics.mdx
index 91ab4b9e053..684378db2b1 100644
--- a/docs/source/metrics.mdx
+++ b/docs/source/metrics.mdx
@@ -1,5 +1,11 @@
# Evaluate predictions
+
+
+Metrics will soon be deprecated in 🤗 Datasets. To learn more about how to use metrics, take a look at our newest library 🤗 [Evaluate](https://huggingface.co/docs/evaluate/index)! In addition to metrics, we've also added more tools for evaluating models and datasets.
+
+
+
🤗 Datasets provides various common and NLP-specific [metrics](https://huggingface.co/metrics) for you to measure your models performance. In this section of the tutorials, you will load a metric and use it to evaluate your models predictions.
You can see what metrics are available with [`list_metrics`]:
diff --git a/docs/source/tutorial.md b/docs/source/tutorial.md
index 803f4978fa5..559575df8dd 100644
--- a/docs/source/tutorial.md
+++ b/docs/source/tutorial.md
@@ -1,16 +1,15 @@
# Overview
-Welcome to the 🤗 Datasets tutorial!
+Welcome to the 🤗 Datasets tutorials! These beginner-friendly tutorials will guide you through the fundamentals of working with 🤗 Datasets. You'll load and prepare a dataset for training with your machine learning framework of choice. Along the way, you'll learn how to load different dataset configurations and splits, interact with and see what's inside your dataset, preprocess, and share a dataset to the [Hub](https://huggingface.co/datasets).
-The goal of the tutorials are to help new users build up a basic understanding of 🤗 Datasets. You will learn to:
+The tutorials assume some basic knowledge of Python and a machine learning framework like PyTorch or TensorFlow. If you're already familiar with these, feel free to check out the [quickstart](./quickstart) to see what you can do with 🤗 Datasets.
-* Setup a virtual environment and install 🤗 Datasets.
-* Load a dataset.
-* Explore what's inside a Dataset object.
-* Use a dataset with PyTorch and TensorFlow.
-* Evaluate your model predictions with a metric.
-* Easily upload a dataset to the Hugging Face Hub.
+
-After completing the tutorials, we hope you will have the necessary skills to start using our library in your own projects!
+The tutorials only cover the basic skills you need to use 🤗 Datasets. There are many other useful functionalities and applications that aren't discussed here. If you're interested in learning more, take a look at [Chapter 5](https://huggingface.co/course/chapter5/1?fw=pt) of the Hugging Face course.
-We understand that people who want to use 🤗 Datasets come from a wide and diverse range of disciplines. The tutorials are designed to be as accessible as possible to people without a developer background. If you already have some experience, take a look at our [Quick Start](/docs/datasets/master/en/quickstart) to see an end-to-end code example in context.
\ No newline at end of file
+
+
+If you have any questions about 🤗 Datasets, feel free to join and ask the community on our [forum](https://discuss.huggingface.co/c/datasets/10).
+
+Let's get started! 🏁
diff --git a/docs/source/upload_dataset.mdx b/docs/source/upload_dataset.mdx
index 719f048831b..140666dce8e 100644
--- a/docs/source/upload_dataset.mdx
+++ b/docs/source/upload_dataset.mdx
@@ -1,143 +1,132 @@
-# Upload a dataset to the Hub
+# Share a dataset to the Hub
-In the last section of the tutorials, you will learn how to upload a dataset to the Hugging Face Hub. 🤗 Datasets aims to provide the largest collection of datasets that anyone can use to train their models. We welcome all dataset contributions from the NLP community, and we have made it very simple for you to add a dataset. Even if you don't have a lot of developer experience, you can still contribute!
+The [Hub](https://huggingface.co/datasets) is home to an extensive collection of community-curated and popular research datasets. We encourage you to share your dataset to the Hub to help grow the ML community and accelerate progress for everyone. All contributions are welcome; adding a dataset is just a drag and drop away!
-Start by creating a Hugging Face Hub account at [hf.co](https://huggingface.co/join) if you don't have one yet.
+Start by [creating a Hugging Face Hub account](https://huggingface.co/join) if you don't have one yet.
-## Create a repository
+## Upload with the Hub UI
-A repository hosts all your dataset files, including the revision history, making it possible to store more than one dataset version.
+The Hub's web-based interface allows users without any developer experience to upload a dataset.
+
+### Create a repository
+
+A repository hosts all your dataset files, including the revision history, making storing more than one dataset version possible.
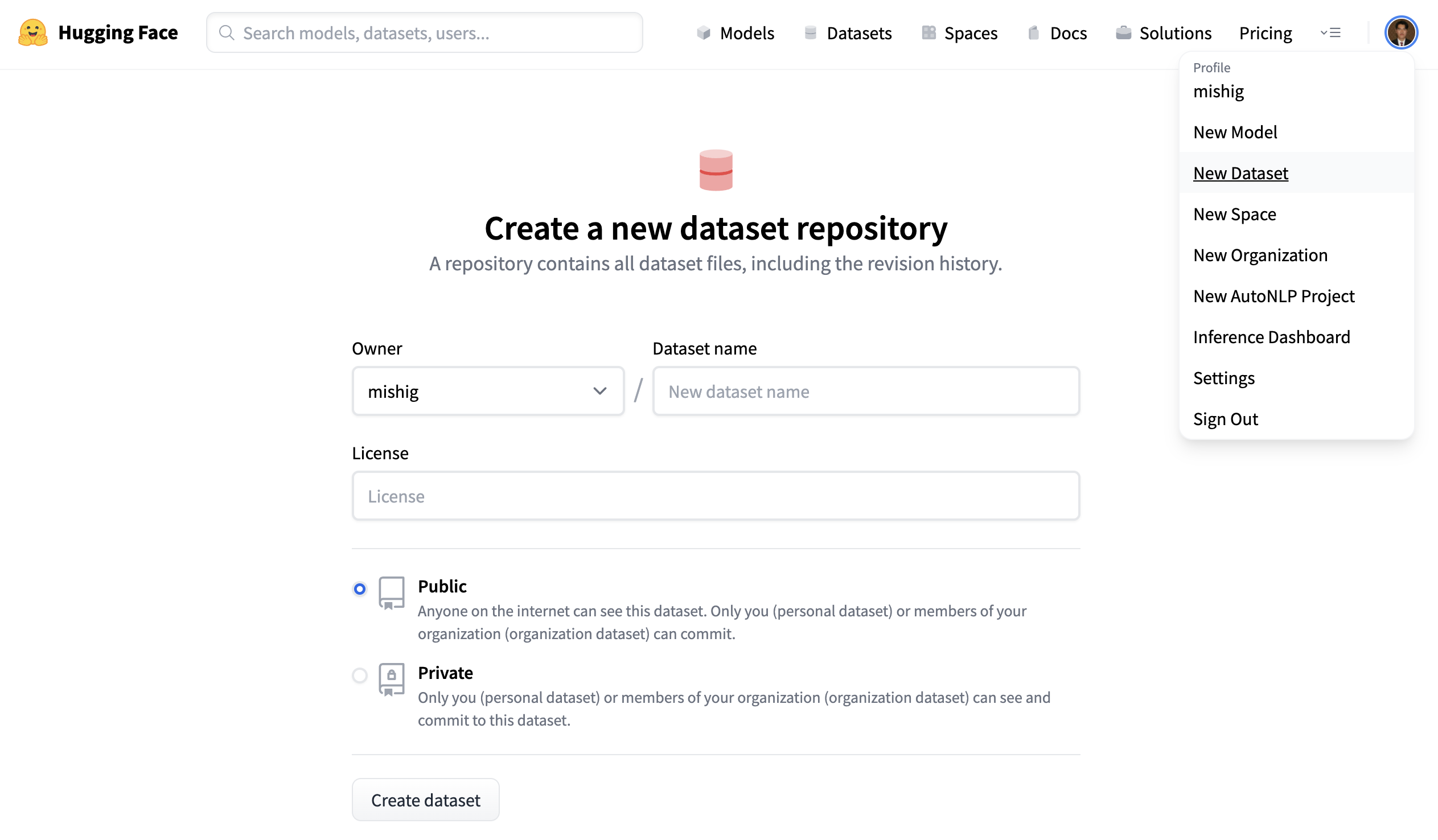
1. Click on your profile and select **New Dataset** to create a new dataset repository.
-2. Give your dataset a name, and select whether this is a public or private dataset. A public dataset is visible to anyone, whereas a private dataset can only be viewed by you or members of your organization.
+2. Pick a name for your dataset, and choose whether it is a public or private dataset. A public dataset is visible to anyone, whereas a private dataset can only be viewed by you or members of your organization.
-## Upload your files
+### Upload dataset
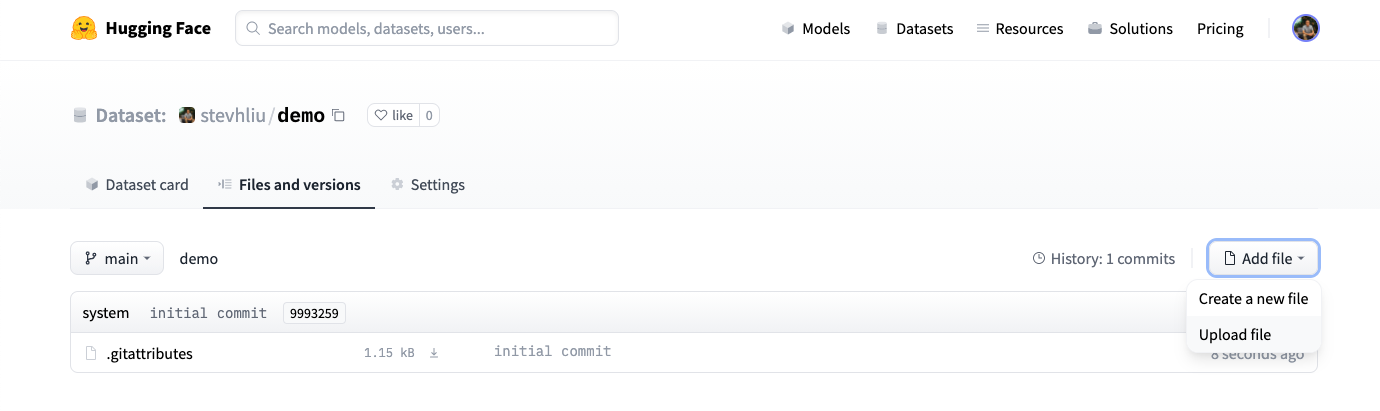
-1. Once you have created a repository, navigate to the **Files and versions** tab to add a file. Select **Add file** to upload your dataset files. We currently support the following data formats: CSV, JSON, JSON lines, text, and Parquet.
+1. Once you've created a repository, navigate to the **Files and versions** tab to add a file. Select **Add file** to upload your dataset files. We currently support the following data formats: CSV, JSON, JSON lines, text, and Parquet.
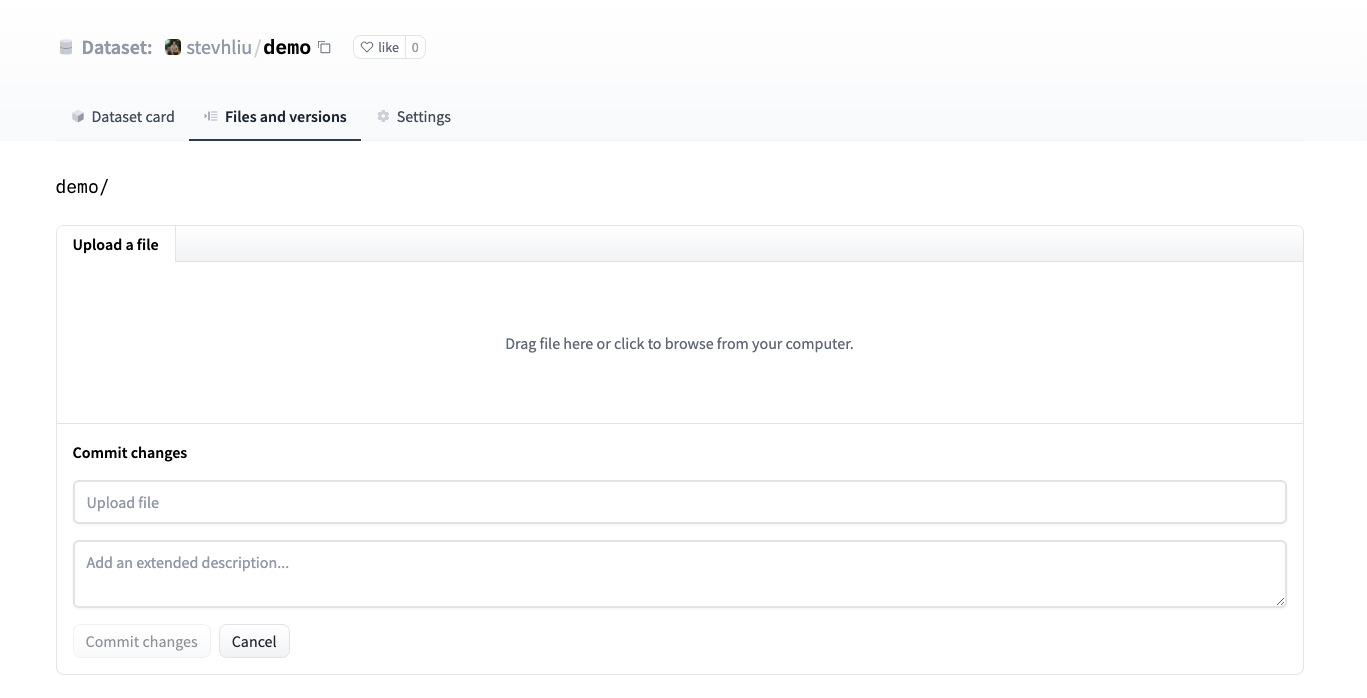
-2. Drag and drop your dataset files here, and add a brief descriptive commit message.
+2. Drag and drop your dataset files and add a brief descriptive commit message.
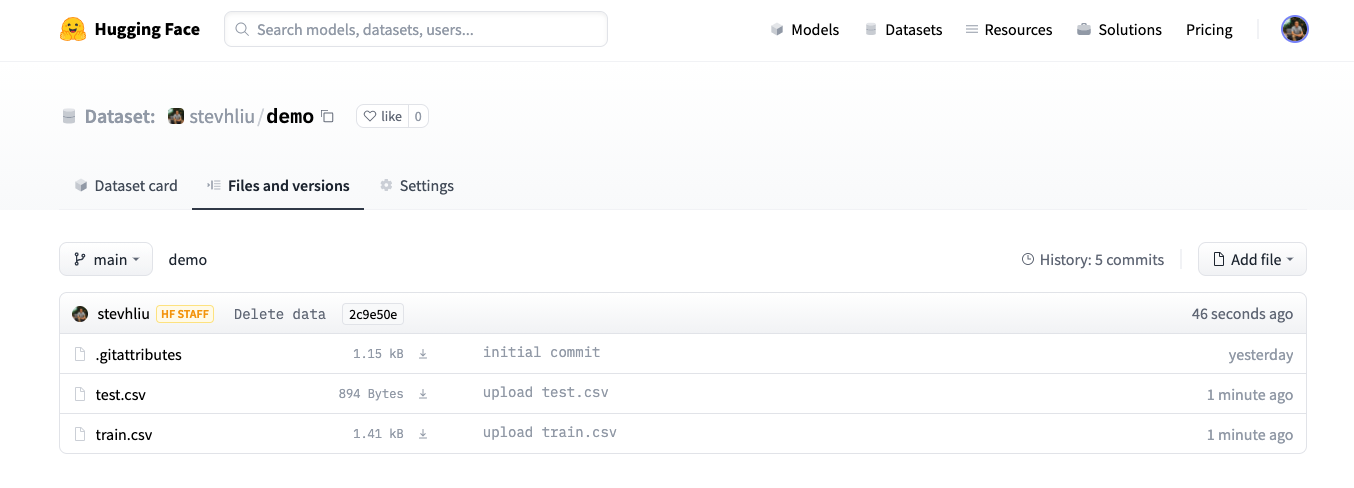
-3. Once you have uploaded your dataset files, they are now stored in your dataset repository.
+3. After uploading your dataset files, they are stored in your dataset repository.
-## Create a Dataset card
+### Create a Dataset card
-The last step is to create a Dataset card. The Dataset card is essential for helping users find your dataset and understand how to use it responsibly.
+Adding a Dataset card is super valuable for helping users find your dataset and understand how to use it responsibly.
-1. Click on the **Create Dataset Card** to create a Dataset card.
+1. Click on **Create Dataset Card** to create a Dataset card. This button creates a `README.md` file in your repository.
-2. Get a quick start with our Dataset card [template](https://raw.githubusercontent.com/huggingface/datasets/master/templates/README.md) to help you fill out all the relevant fields.
+2. Feel free to copy this Dataset card [template](https://raw.githubusercontent.com/huggingface/datasets/master/templates/README.md) to help you fill out all the relevant fields.
-3. The Dataset card uses structured tags to help users discover your dataset on the Hub. Use the [online Datasets Tagging application](https://huggingface.co/spaces/huggingface/datasets-tagging) to help you generate the appropriate tags.
+3. The Dataset card uses structured tags to help users discover your dataset on the Hub. Use the [Dataset Tagger](https://huggingface.co/spaces/huggingface/datasets-tagging) to help you generate the appropriate tags.
-4. Copy the generated tags and paste them at the top of your Dataset card, then commit your changes.
+4. Copy the generated tags, paste them at the top of your Dataset card, and then commit your changes.
-For a detailed example of what a good Dataset card should look like, refer to the [CNN DailyMail Dataset card](https://huggingface.co/datasets/cnn_dailymail).
+For a detailed example of what a good Dataset card should look like, take a look at the [CNN DailyMail Dataset card](https://huggingface.co/datasets/cnn_dailymail).
-## Load dataset
+### Load dataset
-Your dataset can now be loaded by anyone in a single line of code!
+Once your dataset is stored on the Hub, anyone can load it with the [`load_dataset`] function:
```py
>>> from datasets import load_dataset
+
>>> dataset = load_dataset("stevhliu/demo")
->>> dataset
-DatasetDict({
- train: Dataset({
- features: ['id', 'package_name', 'review', 'date', 'star', 'version_id'],
- num_rows: 5
- })
- test: Dataset({
- features: ['id', 'package_name', 'review', 'date', 'star', 'version_id'],
- num_rows: 5
- })
-})
```
-## Upload from Python
+## Upload with Python
-To upload a [`DatasetDict`] on the Hugging Face Hub in Python, you can login and use the [`DatasetDict.push_to_hub`] method:
+Users who prefer to upload a dataset programmatically can use the [huggingface_hub](https://huggingface.co/docs/huggingface_hub/index) library. This library allows users to interact with the Hub from Python.
-1. Login from the command line:
+1. Begin by installing the library:
+```bash
+pip install huggingface_hub
```
+
+2. To upload a dataset on the Hub in Python, you need to log in to your Hugging Face account:
+
+```bash
huggingface-cli login
```
-2. Upload the dataset:
+3. Use the [`push_to_hub()`](https://huggingface.co/docs/datasets/master/en/package_reference/main_classes#datasets.DatasetDict.push_to_hub) function to help you add, commit, and push a file to your repository:
```py
>>> from datasets import load_dataset
+
>>> dataset = load_dataset("stevhliu/demo")
->>> # dataset = dataset.map(...) # do all your processing here
+# dataset = dataset.map(...) # do all your processing here
>>> dataset.push_to_hub("stevhliu/processed_demo")
```
-With the `private` parameter you can choose whether your dataset is public or private:
+To set your dataset as private, set the `private` parameter to `True`. This parameter will only work if you are creating a repository for the first time.
```py
>>> dataset.push_to_hub("stevhliu/private_processed_demo", private=True)
```
-## Privacy
+### Privacy
-If your uploaded dataset is private, only you can access it:
+A private dataset is only accessible by you. Similarly, if you share a dataset within your organization, then members of the organization can also access the dataset.
-1. Login from the command line:
-
-```
-huggingface-cli login
-```
-
-2. Load the dataset with your authentication token:
+Load a private dataset by providing your authentication token to the `use_auth_token` parameter:
```py
>>> from datasets import load_dataset
->>> dataset = load_dataset("stevhliu/demo", use_auth_token=True)
-```
-
-Similarly, share a private dataset within your organization by uploading a dataset as **Private** to your organization. Then members of the organization can load the dataset like:
-
-1. Login from the command line:
-```
-huggingface-cli login
-```
-
-2. Load the dataset with your authentication token:
+# Load a private individual dataset
+>>> dataset = load_dataset("stevhliu/demo", use_auth_token=True)
-```py
->>> from datasets import load_dataset
+# Load a private organization dataset
>>> dataset = load_dataset("organization/dataset_name", use_auth_token=True)
```
## What's next?
-Congratulations, you have completed all of the 🤗 Datasets tutorials!
+Congratulations, you've completed the tutorials! 🥳
+
+From here, you can go on to:
-Throughout these tutorials, you learned the basic steps of using 🤗 Datasets. You loaded a dataset from the Hub and learned how to access the information stored inside the dataset. Next, you tokenized the dataset into sequences of integers and formatted it so you can use it with PyTorch or TensorFlow. Then you loaded a metric to evaluate your model's predictions. Finally, you uploaded a dataset to the Hub without writing a single line of code. This is all you need to get started with 🤗 Datasets!
+- Learn more about how to use 🤗 Datasets other functions to [process your dataset](/process).
+- [Stream large datasets](/stream) and avoid waiting for the entire dataset to download.
+- [Write a dataset loading script](/dataset_script) and share your dataset with the community.
-Now that you have a solid grasp of what 🤗 Datasets can do, you can begin formulating your own questions about how you can use it with your dataset. Please take a look at our [How-to guides](./how_to) for more practical help on solving common use-cases, or read our [Conceptual guides](./about_arrow) to deepen your understanding about 🤗 Datasets.
\ No newline at end of file
+If you have any questions about 🤗 Datasets, feel free to join and ask the community on our [forum](https://discuss.huggingface.co/c/datasets/10).
\ No newline at end of file
diff --git a/docs/source/use_dataset.mdx b/docs/source/use_dataset.mdx
index 49b89abe075..3922fea59c1 100644
--- a/docs/source/use_dataset.mdx
+++ b/docs/source/use_dataset.mdx
@@ -1,137 +1,189 @@
-# Train with 🤗 Datasets
+# Preprocess
-So far, you loaded a dataset from the Hugging Face Hub and learned how to access the information stored inside the dataset. Now you will tokenize and use your dataset with a framework such as PyTorch or TensorFlow. By default, all the dataset columns are returned as Python objects. But you can bridge the gap between a Python object and your machine learning framework by setting the format of a dataset. Formatting casts the columns into compatible PyTorch or TensorFlow types.
+In addition to loading datasets, 🤗 Datasets other main goal is to offer a diverse set of preprocessing functions to get a dataset into an appropriate format for training with your machine learning framework.
-
+There are many possible ways to preprocess a dataset, and it all depends on your specific dataset. Sometimes you may need to rename a column, and other times you might need to unflatten nested fields. 🤗 Datasets provides a way to do most of these things. But in nearly all preprocessing cases, depending on your dataset modality, you'll need to:
-Often times you may want to modify the structure and content of your dataset before you use it to train a model. For example, you may want to remove a column or cast it as a different type. 🤗 Datasets provides the necessary tools to do this, but since each dataset is so different, the processing approach will vary individually. For more detailed information about preprocessing data, take a look at our [guide](https://huggingface.co/transformers/preprocessing#) from the 🤗 Transformers library. Then come back and read our [How-to Process](./process) guide to see all the different methods for processing your dataset.
+- Tokenize a text dataset.
+- Resample an audio dataset.
+- Apply transforms to an image dataset.
-
+The last preprocessing step is usually setting your dataset format to be compatible with your machine learning framework's expected input format.
+
+In this tutorial, you'll also need to install the 🤗 Transformers library:
+
+```bash
+pip install transformers
+```
+
+Grab a dataset of your choice and follow along!
+
+## Tokenize text
-## Tokenize
+Models cannot process raw text, so you'll need to convert the text into numbers. Tokenization provides a way to do this by dividing text into individual words called *tokens*. Tokens are finally converted to numbers.
-Tokenization divides text into individual words called tokens. Tokens are converted into numbers, which is what the model receives as its input.
+
+
+Check out the [Tokenizers](https://huggingface.co/course/chapter2/4?fw=pt) section in Chapter 2 of the Hugging Face course to learn more about tokenization and different tokenization algorithms.
+
+
-The first step is to install the 🤗 Transformers library:
+**1**. Start by loading the [rotten_tomatoes](https://huggingface.co/datasets/rotten_tomatoes) dataset and the tokenizer corresponding to a pretrained [BERT](https://huggingface.co/bert-base-uncased) model. Using the same tokenizer as the pretrained model is important because you want to make sure the text is split in the same way.
+
+```py
+>>> from transformers import AutoTokenizer
+>>> from datasets import load_dataset
+>>> tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
+>>> dataset = load_dataset("rotten_tomatoes", split="train")
```
-pip install transformers
+
+**2**. Call your tokenizer on the first row of `text` in the dataset:
+
+```py
+>>> tokenizer(dataset[0]["text"])
+{'input_ids': [101, 1103, 2067, 1110, 17348, 1106, 1129, 1103, 6880, 1432, 112, 188, 1207, 107, 14255, 1389, 107, 1105, 1115, 1119, 112, 188, 1280, 1106, 1294, 170, 24194, 1256, 3407, 1190, 170, 11791, 5253, 188, 1732, 7200, 10947, 12606, 2895, 117, 179, 7766, 118, 172, 15554, 1181, 3498, 6961, 3263, 1137, 188, 1566, 7912, 14516, 6997, 119, 102],
+ 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
+ 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
```
-Next, import a tokenizer. It is important to use the tokenizer that is associated with the model you are using, so the text is split in the same way. In this example, load the [BERT tokenizer](https://huggingface.co/transformers/model_doc/bert#berttokenizerfast) because you are using the [BERT](https://huggingface.co/bert-base-cased) model:
+The tokenizer returns a dictionary with three items:
+
+- `input_ids`: the numbers representing the tokens in the text.
+- `token_type_ids`: indicates which sequence a token belongs to if there is more than one sequence.
+- `attention_mask`: indicates whether a token should be masked or not.
+
+These values are actually the model inputs.
+
+**3**. The fastest way to tokenize your entire dataset is to use the [`~Dataset.map`] function. This function speeds up tokenization by applying the tokenizer to batches of examples instead of individual examples. Set the `batched` parameter to `True`:
```py
->>> from transformers import BertTokenizerFast
->>> tokenizer = BertTokenizerFast.from_pretrained('bert-base-cased')
+>>> def tokenization(example):
+... return tokenizer(example["text"])
+
+>>> dataset = dataset.map(tokenization, batched=True)
```
-Now you can tokenize `sentence1` field of the dataset:
+**4**. Set the format of your dataset to be compatible with your machine learning framework:
+
+
+
+Use the [`~Dataset.set_format`] function to set the dataset format to be compatible with PyTorch:
```py
->>> encoded_dataset = dataset.map(lambda examples: tokenizer(examples['sentence1']), batched=True)
->>> encoded_dataset.column_names
-['sentence1', 'sentence2', 'label', 'idx', 'input_ids', 'token_type_ids', 'attention_mask']
->>> encoded_dataset[0]
-{'sentence1': 'Amrozi accused his brother , whom he called " the witness " , of deliberately distorting his evidence .',
-'sentence2': 'Referring to him as only " the witness " , Amrozi accused his brother of deliberately distorting his evidence .',
-'label': 1,
-'idx': 0,
-'input_ids': [ 101, 7277, 2180, 5303, 4806, 1117, 1711, 117, 2292, 1119, 1270, 107, 1103, 7737, 107, 117, 1104, 9938, 4267, 12223, 21811, 1117, 2554, 119, 102],
-'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
-'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
-}
+>>> dataset.set_format(type="torch", columns=["input_ids", "token_type_ids", "attention_mask", "labels"])
+>>> dataset.format['type']
+'torch'
+```
+
+
+Use the [`~Dataset.to_tf_dataset`] function to set the dataset format to be compatible with TensorFlow. You'll also need to import a [data collator](https://huggingface.co/docs/transformers/main_classes/data_collator#transformers.DataCollatorWithPadding) from 🤗 Transformers to combine the varying sequence lengths into a single batch of equal lengths:
+
+```py
+>>> from transformers import DataCollatorWithPadding
+
+>>> data_collator = DataCollatorWithPadding(tokenizer=tokenizer, return_tensors="tf")
+>>> tf_dataset = dataset.to_tf_dataset(
+... columns=["input_ids", "token_type_ids", "attention_mask"],
+... label_cols=["labels"],
+... batch_size=2,
+... collate_fn=data_collator,
+... shuffle=True
+... )
```
+
+
+
+**5**. The dataset is now ready for training with your machine learning framework!
+
+## Resample audio signals
-The tokenization process creates three new columns: `input_ids`, `token_type_ids`, and `attention_mask`. These are the inputs to the model.
+Audio inputs like text datasets need to be divided into discrete data points. This is known as *sampling*; the sampling rate tells you how much of the speech signal is captured per second. It is important to make sure the sampling rate of your dataset matches the sampling rate of the data used to pretrain the model you're using. If the sampling rates are different, the pretrained model may perform poorly on your dataset because it doesn't recognize the differences in the sampling rate.
+
+**1**. Start by loading the [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) dataset, the [`Audio`] feature, and the feature extractor corresponding to a pretrained [Wav2Vec2](https://huggingface.co/facebook/wav2vec2-base-960h) model:
+
+```py
+>>> from transformers import AutoFeatureExtractor
+>>> from datasets import load_dataset, Audio
-## Use in PyTorch or TensorFlow
+>>> feature_extractor = AutoFeatureExtractor.from_pretrained("facebook/wav2vec2-base-960h")
+>>> dataset = load_dataset("PolyAI/minds14", "en-US", split="train")
+```
-Next, format the dataset into compatible PyTorch or TensorFlow types.
+**2**. Index into the first row of the dataset. When you call the `audio` column of the dataset, it is automatically decoded and resampled:
-### PyTorch
+```py
+>>> dataset[0]["audio"]
+{'array': array([ 0. , 0.00024414, -0.00024414, ..., -0.00024414,
+ 0. , 0. ], dtype=float32),
+ 'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~JOINT_ACCOUNT/602ba55abb1e6d0fbce92065.wav',
+ 'sampling_rate': 8000}
+```
-If you are using PyTorch, set the format with [`Dataset.set_format`], which accepts two main arguments:
+**3**. Reading a dataset card is incredibly useful and can give you a lot of information about the dataset. A quick look at the MInDS-14 dataset card tells you the sampling rate is 8kHz. Likewise, you can get many details about a model from its model card. The Wav2Vec2 model card says it was sampled on 16kHz speech audio. This means you'll need to upsample the MInDS-14 dataset to match the sampling rate of the model.
-1. `type` defines the type of column to cast to. For example, `torch` returns PyTorch tensors.
+Use the [`~Dataset.cast_column`] function and set the `sampling_rate` parameter in the [`Audio`] feature to upsample the audio signal. When you call the `audio` column now, it is decoded and resampled to 16kHz:
-2. `columns` specify which columns should be formatted.
+```py
+>>> dataset = dataset.cast_column("audio", Audio(sampling_rate=16_000))
+>>> dataset[0]["audio"]
+{'array': array([ 2.3443763e-05, 2.1729663e-04, 2.2145823e-04, ...,
+ 3.8356509e-05, -7.3497440e-06, -2.1754686e-05], dtype=float32),
+ 'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~JOINT_ACCOUNT/602ba55abb1e6d0fbce92065.wav',
+ 'sampling_rate': 16000}
+```
-After you set the format, wrap the dataset with `torch.utils.data.DataLoader`. Your dataset is now ready for use in a training loop!
+**4**. Use the [`~Dataset.map`] function to resample the entire dataset to 16kHz. This function speeds up resampling by applying the feature extractor to batches of examples instead of individual examples. Set the `batched` parameter to `True`:
```py
->>> import torch
->>> from datasets import load_dataset
->>> from transformers import AutoTokenizer
->>> dataset = load_dataset('glue', 'mrpc', split='train')
->>> tokenizer = AutoTokenizer.from_pretrained('bert-base-cased')
->>> dataset = dataset.map(lambda e: tokenizer(e['sentence1'], truncation=True, padding='max_length'), batched=True)
->>> dataset.set_format(type='torch', columns=['input_ids', 'token_type_ids', 'attention_mask', 'label'])
->>> dataloader = torch.utils.data.DataLoader(dataset, batch_size=32)
->>> next(iter(dataloader))
-{'attention_mask': tensor([[1, 1, 1, ..., 0, 0, 0],
- ...,
- [1, 1, 1, ..., 0, 0, 0]]),
-'input_ids': tensor([[ 101, 7277, 2180, ..., 0, 0, 0],
- ...,
- [ 101, 1109, 4173, ..., 0, 0, 0]]),
-'label': tensor([1, 0, 1, 0, 1, 1, 0, 1]),
-'token_type_ids': tensor([[0, 0, 0, ..., 0, 0, 0],
- ...,
- [0, 0, 0, ..., 0, 0, 0]])}
+>>> def preprocess_function(examples):
+... audio_arrays = [x["array"] for x in examples["audio"]]
+... inputs = feature_extractor(
+... audio_arrays, sampling_rate=feature_extractor.sampling_rate, max_length=16000, truncation=True
+... )
+... return inputs
+
+>>> dataset = dataset.map(preprocess_function, batched=True)
```
-### TensorFlow
+**5**. The dataset is now ready for training with your machine learning framework!
-If you are using TensorFlow, you can use [`Dataset.to_tf_dataset`] to wrap the dataset with a **tf.data.Dataset**, which is natively understood by Keras.
-This means a **tf.data.Dataset** object can be iterated over to yield batches of data, and can be passed directly to methods like **model.fit()**.
+## Apply data augmentations
-[`Dataset.to_tf_dataset`] accepts several arguments:
+The most common preprocessing you'll do with image datasets is *data augmentation*, a process that introduces random variations to an image without changing the meaning of the data. This can mean changing the color properties of an image or randomly cropping an image. You are free to use any data augmentation library you like, and 🤗 Datasets will help you apply your data augmentations to your dataset.
-1. `columns` specify which columns should be formatted (includes the inputs and labels).
+**1**. Start by loading the [Beans](https://huggingface.co/datasets/beans) dataset, the `Image` feature, and the feature extractor corresponding to a pretrained [ViT](https://huggingface.co/google/vit-base-patch16-224-in21k) model:
-2. `shuffle` determines whether the dataset should be shuffled.
+```py
+>>> from transformers import AutoFeatureExtractor
+>>> from datasets import load_dataset, Image
-3. `batch_size` specifies the batch size.
+>>> feature_extractor = AutoFeatureExtractor.from_pretrained("google/vit-base-patch16-224-in21k")
+>>> dataset = load_dataset("beans", split="train")
+```
-4. `collate_fn` specifies a data collator that will batch each processed example and apply padding. If you are using a `DataCollator`, make sure you set `return_tensors="tf"` when you initialize it to return `tf.Tensor` outputs.
+**2**. Index into the first row of the dataset. When you call the `image` column of the dataset, the underlying PIL object is automatically decoded into an image.
```py
->>> import tensorflow as tf
->>> from datasets import load_dataset
->>> from transformers import AutoTokenizer
->>> dataset = load_dataset('glue', 'mrpc', split='train')
->>> tokenizer = AutoTokenizer.from_pretrained('bert-base-cased')
->>> dataset = dataset.map(lambda e: tokenizer(e['sentence1'], truncation=True, padding='max_length'), batched=True)
->>> data_collator = DataCollatorWithPadding(tokenizer=tokenizer, return_tensors="tf")
->>> train_dataset = dataset["train"].to_tf_dataset(
-... columns=['input_ids', 'token_type_ids', 'attention_mask', 'label'],
-... shuffle=True,
-... batch_size=16,
-... collate_fn=data_collator,
-... )
->>> model.fit(train_dataset) # The output tf.data.Dataset is ready for training immediately
->>> next(iter(train_dataset)) # You can also iterate over the dataset manually to get batches
-{'attention_mask': ,
- 'input_ids': ,
- 'labels': ,
- 'token_type_ids':
-}
+>>> dataset[0]["image"]
```
-
+**3**. Now, you can apply some transforms to the image. Feel free to take a look at the [various transforms available](https://pytorch.org/vision/stable/auto_examples/plot_transforms.html#sphx-glr-auto-examples-plot-transforms-py) in torchvision and choose one you'd like to experiment with. This example applies a transform that randomly rotates the image:
-[`Dataset.to_tf_dataset`] is the easiest way to create a TensorFlow compatible dataset. If you don't want a `tf.data.Dataset` and would rather the dataset emit `tf.Tensor` objects, take a look at the [format](./process#format) section instead!
+```py
+>>> from torchvision.transforms import RandomRotation
-
+>>> rotate = RandomRotation(degrees=(0, 90))
+>>> def transforms(examples):
+... examples["pixel_values"] = [rotate(image.convert("RGB")) for image in examples["image"]]
+... return examples
+```
+
+**4**. Use the [`~Dataset.set_transform`] function to apply the transform on-the-fly. When you index into the image `pixel_values`, the transform is applied, and your image gets rotated.
+
+```py
+>>> dataset.set_transform(transforms)
+>>> dataset[0]["pixel_values"]
+```
-Your dataset is now ready for use in a training loop!
+**5**. The dataset is now ready for training with your machine learning framework!
\ No newline at end of file