from typing import Any, List
import torch
from pytorch_lightning import LightningModule
from torchmetrics import MaxMetric
from torchmetrics.classification import Accuracy
from torchmetrics.regression import MeanSquaredError
from src.models.components.simple_dense_net import SimpleDenseNet
class MNISTLitModule(LightningModule):
"""Example of LightningModule for MNIST classification.
A LightningModule organizes your PyTorch code into 5 sections:
- Computations (init).
- Train loop (training_step)
- Validation loop (validation_step)
- Test loop (test_step)
- Optimizers (configure_optimizers)
Read the docs:
https://pytorch-lightning.readthedocs.io/en/latest/common/lightning_module.html
"""
def __init__(
self,
net: torch.nn.Module,
lr: float = 0.001,
weight_decay: float = 0.0005,
):
super().__init__()
# this line allows to access init params with 'self.hparams' attribute
# it also ensures init params will be stored in ckpt
self.save_hyperparameters(logger=False)
self.net = net
# loss function
self.criterion = torch.nn.CrossEntropyLoss()
# use separate metric instance for train, val and test step
# to ensure a proper reduction over the epoch
self.train_acc = Accuracy()
self.val_acc = Accuracy()
self.test_acc = Accuracy()
self.one_mse = MeanSquaredError()
# for logging best so far validation accuracy
self.val_acc_best = MaxMetric()
def forward(self, x: torch.Tensor):
return self.net(x)
def on_train_start(self):
# by default lightning executes validation step sanity checks before training starts,
# so we need to make sure val_acc_best doesn't store accuracy from these checks
self.val_acc_best.reset()
def step(self, batch: Any):
x, y = batch
logits = self.forward(x)
loss = self.criterion(logits, y)
preds = torch.argmax(logits, dim=1)
return loss, preds, y
def training_step(self, batch: Any, batch_idx: int):
loss, preds, targets = self.step(batch)
# log train metrics
# acc = self.train_acc(preds, targets)
acc = (preds == targets).sum() / len(preds)
self.log("train/loss", loss, on_step=False, on_epoch=True, prog_bar=False)
self.log("train/acc", acc, on_step=True, on_epoch=True, prog_bar=True)
# we can return here dict with any tensors
# and then read it in some callback or in `training_epoch_end()` below
result_dict = {"loss": loss, "preds": preds, "targets": targets}
if self.global_rank == 0 and self.global_step == 100:
print(f"\n!training_STEP rank-0 {len(result_dict)} {result_dict}")
# remember to always return loss from `training_step()` or else backpropagation will fail!
return result_dict
def training_step_end(self, outputs):
if self.global_step == 100:
print(f"\n!training_STEP_end rank-{self.global_rank} {len(outputs)} {outputs}")
def training_epoch_end(self, outputs: List[Any]):
# `outputs` is a list of dicts returned from `training_step()`
print(f"!\ntraining_EPOCH{self.current_epoch}_end rank-{self.global_rank} {len(outputs)}")
def validation_step(self, batch: Any, batch_idx: int):
loss, preds, targets = self.step(batch)
# log val metrics
acc = self.val_acc(preds, targets)
self.log("val/loss", loss, on_step=False, on_epoch=True, prog_bar=False)
self.log("val/acc", acc, on_step=False, on_epoch=True, prog_bar=True)
return {"loss": loss, "preds": preds, "targets": targets}
def validation_epoch_end(self, outputs: List[Any]):
acc = self.val_acc.compute() # get val accuracy from current epoch
self.val_acc_best.update(acc)
self.log("val/acc_best", self.val_acc_best.compute(), on_epoch=True, prog_bar=True)
def test_step(self, batch: Any, batch_idx: int):
loss, preds, targets = self.step(batch)
# log test metrics
acc = self.test_acc(preds, targets)
self.log("test/loss", loss, on_step=False, on_epoch=True)
self.log("test/acc", acc, on_step=False, on_epoch=True)
self.log("test/loss-ddp", loss, on_step=False, on_epoch=True, sync_dist=True)
self.log("test/acc-ddp", acc, on_step=False, on_epoch=True, sync_dist=True)
return {"loss": loss, "preds": preds, "targets": targets}
def test_epoch_end(self, outputs: List[Any]):
pass
def on_epoch_end(self):
# reset metrics at the end of every epoch
self.train_acc.reset()
self.test_acc.reset()
self.val_acc.reset()
def configure_optimizers(self):
"""Choose what optimizers and learning-rate schedulers to use in your optimization.
Normally you'd need one. But in the case of GANs or similar you might have multiple.
See examples here:
https://pytorch-lightning.readthedocs.io/en/latest/common/lightning_module.html#configure-optimizers
"""
return torch.optim.Adam(
params=self.parameters(), lr=self.hparams.lr, weight_decay=self.hparams.weight_decay
)
Brief
When using 4 GPUs with DDP strategy with
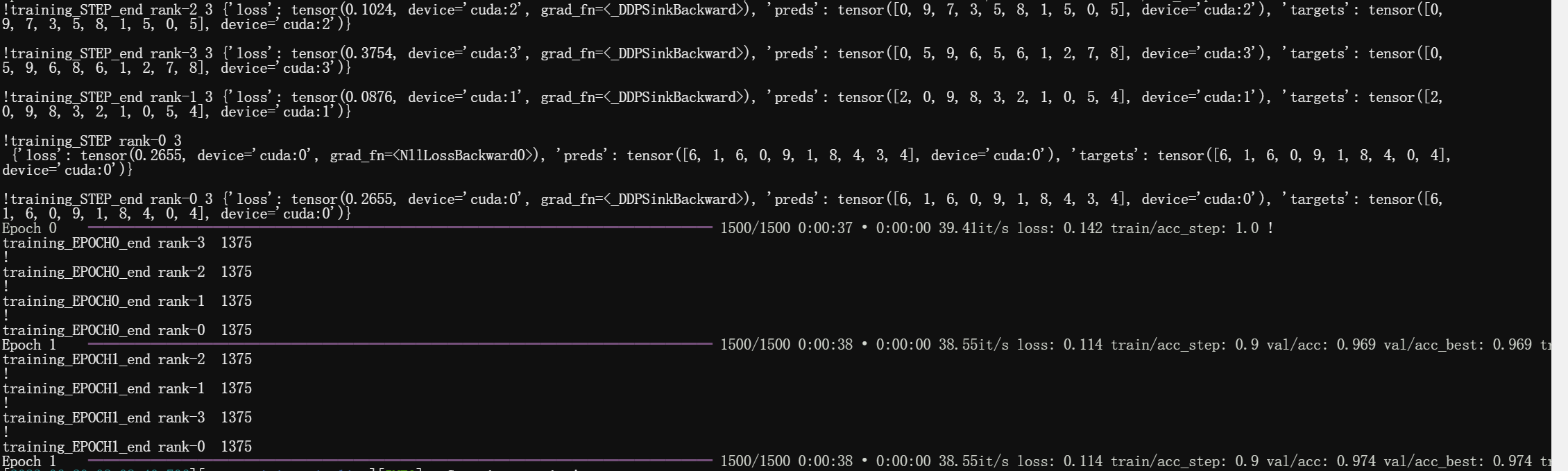
batch_size=10in themnist_datamodule, the batch number shown behind the progress bar is1500, which doesn't coincide with either the55000 (all datapoints)/ 4 (world_size) / 10 (batch_size)=1375or55000 (all datapoints) / 10 (batch_size)=5500.Env: 4 GPUs on 1 Node
pytorch-lightning 1.6.4
torch 1.10.0
torchelastic 0.2.0
torchmetrics 0.9.1
torchtext 0.11.0
torchvision 0.11.0
To reproduce
And add some print statements in
mnist_module(The full modified version is below) and trypython train.py trainer=ddp datamodule.batch_size=10 trainer.max_epochs=2