Introduce published segment cache in broker #6901
Conversation
|
Heads up, I very briefly experimented with interning data segments back in #3286 but had to back it out because real-time nodes publish with a size of 0, which makes the segment size calculations all break. I have not dug into the code here deep enough to know if it falls to the same issue. |
|
Can you also please record the impact on heap size in the broker? We already have pretty massive broker heaps and putting more pressure on them would be problematic. |
Thanks @drcrallen This issue can indeed happen, I looked at the trail of issues surrounding #3286, I am thinking of addressing #3287 before this PR to avoid incorrect segment sizes. |
…uals only and size is preserved if set * Added a trueEquals to DataSegment class
The size issue is resolved with my latest commit. Changed the |
| { | ||
|
|
||
| private static final int DEFAULT_POLL_PERIOD_IN_MS = 60000; | ||
| private static final EmittingLogger log = new EmittingLogger(MetadataSegmentView.class); |
There was a problem hiding this comment.
Can be Logger since it emits nothing.
There was a problem hiding this comment.
changed back to EmittingLogger, since it emits something now :)
| private final BytesAccumulatingResponseHandler responseHandler; | ||
| private final BrokerSegmentWatcherConfig segmentWatcherConfig; | ||
|
|
||
| private final Map<DataSegment, DateTime> publishedSegments = new ConcurrentHashMap<>(); |
There was a problem hiding this comment.
Please change its type to ConcurrentMap (#6898).
| segmentWatcherConfig.getWatchedDataSources() | ||
| ); | ||
| publishedSegments.keySet() | ||
| .removeIf(key -> !segmentWatcherConfig.getWatchedDataSources().contains(key.getDataSource())); |
There was a problem hiding this comment.
This should be getting only the segments of watched dataSources in the first place rather than filtering later.
There was a problem hiding this comment.
Good point, thanks. Changed the /segments api in MetadataResource to take datasources, so we can pass watchedDataSources to it and filtering can happen before broker gets the published segments.
There was a problem hiding this comment.
I think this is not needed now because getMetadataSegments() returns only filtered segments.
There was a problem hiding this comment.
yeah, not needed anymore, missed to remove it.
| publishedSegments.put(interned, ts); | ||
| } | ||
| // filter the segments from cache which may not be present in subsequent polling | ||
| publishedSegments.values().removeIf(v -> v != ts); |
There was a problem hiding this comment.
Would you elaborate more on what this is doing? And what happens if someone reads a segment by calling getPublishedSegments which is supposed to be removed but haven't yet?
There was a problem hiding this comment.
Added more details in the comment.
And what happens if someone reads a segment by calling getPublishedSegments which is supposed to be removed but haven't yet?
If that happens, the segment will be removed in the next poll, so publishedSegments will be eventually consistent.
| import java.util.Objects; | ||
| import java.util.Set; | ||
|
|
||
|
|
There was a problem hiding this comment.
Please remove unnecessary change.
| return authorizedSegments.iterator(); | ||
| } | ||
|
|
||
| private CloseableIterator<DataSegment> getAuthorizedPublishedSegments( |
There was a problem hiding this comment.
Is this authorization not needed anymore?
There was a problem hiding this comment.
I don't think it's needed because, MetadataResource#getDatabaseSegments does the authorization check as well.
There was a problem hiding this comment.
Sorry, this authorization check is still required, because broker->coordinator call uses escalated client, so MetadataResource is using the escalated client. Will add this back.
| while (metadataSegments.hasNext()) { | ||
| final DataSegment currentSegment = metadataSegments.next(); | ||
| final DataSegment interned; | ||
| if (currentSegment.getSize() > 0) { |
There was a problem hiding this comment.
Please add a method to DataSegmentInterner which has this check.
There was a problem hiding this comment.
added common method getInterner(segment)
There was a problem hiding this comment.
👍 for pushing this down, and also using in ServerSelector constructor
| ); | ||
| serverExpectations.get(lastServer).addExpectation(expectation); | ||
|
|
||
| EasyMock.expect(mockSegment.getSize()).andReturn(-1L).anyTimes(); |
There was a problem hiding this comment.
I guess you're simulating the segment from realtime tasks. Then, it would be more realistic if it returns 0.
| public Response getDatabaseSegments(@Context final HttpServletRequest req) | ||
| public Response getDatabaseSegments( | ||
| @Context final HttpServletRequest req, | ||
| @QueryParam("datasources") String datasources |
There was a problem hiding this comment.
This can be simply a list or set.
There was a problem hiding this comment.
Didn't find any existing API's taking in a list as query param in druid code, so went with json string. Also the URL with list will look like /druid/coordinator/v1/metadata/segments?datasources="foo"&datasources="bar"&datasources="baz" instead of /druid/coordinator/v1/metadata/segments?datasources=["foo","bar","baz"]. But I can change if there's any benefit.
| // since the presence of a segment with an earlier timestamp indicates that | ||
| // "that" segment is not returned by coordinator in latest poll, so it's | ||
| // likely deleted and therefore we remove it from publishedSegments | ||
| publishedSegments.values().removeIf(v -> v != timestamp); |
There was a problem hiding this comment.
Thanks for adding a comment. How about replacing all segments like in CoordinatorRuleManager rather than checking and removing individual segment?
There was a problem hiding this comment.
If I did the replacing, then I'd be allocating memory for a map containing all published segments, (possibly) filling the young gen on every poll period, I thought it would be more memory efficient by removing the segments from existing map.
| ) | ||
| { | ||
| this.segment = new AtomicReference<>(segment); | ||
| this.segment = new AtomicReference<>(DataSegmentInterner.intern(segment)); |
There was a problem hiding this comment.
I'm not sure segment still needs to be an AtomicReference.. Let's figure it out in #6952.
| public MetadataSegmentView( | ||
| final @Coordinator DruidLeaderClient druidLeaderClient, | ||
| ObjectMapper jsonMapper, | ||
| BytesAccumulatingResponseHandler responseHandler, |
There was a problem hiding this comment.
Please add final to these two variables.
| import java.util.concurrent.TimeUnit; | ||
|
|
||
| @ManageLifecycle | ||
| public class MetadataSegmentView |
There was a problem hiding this comment.
It would be great if you can add a simple description about what this class does and how it's being used.
There was a problem hiding this comment.
okay, added description.
* change the coordinator api * removeall segments at once from MetadataSegmentView in order to serve a more consistent view of published segments * Change the poll behaviour to avoid multiple poll execution at same time
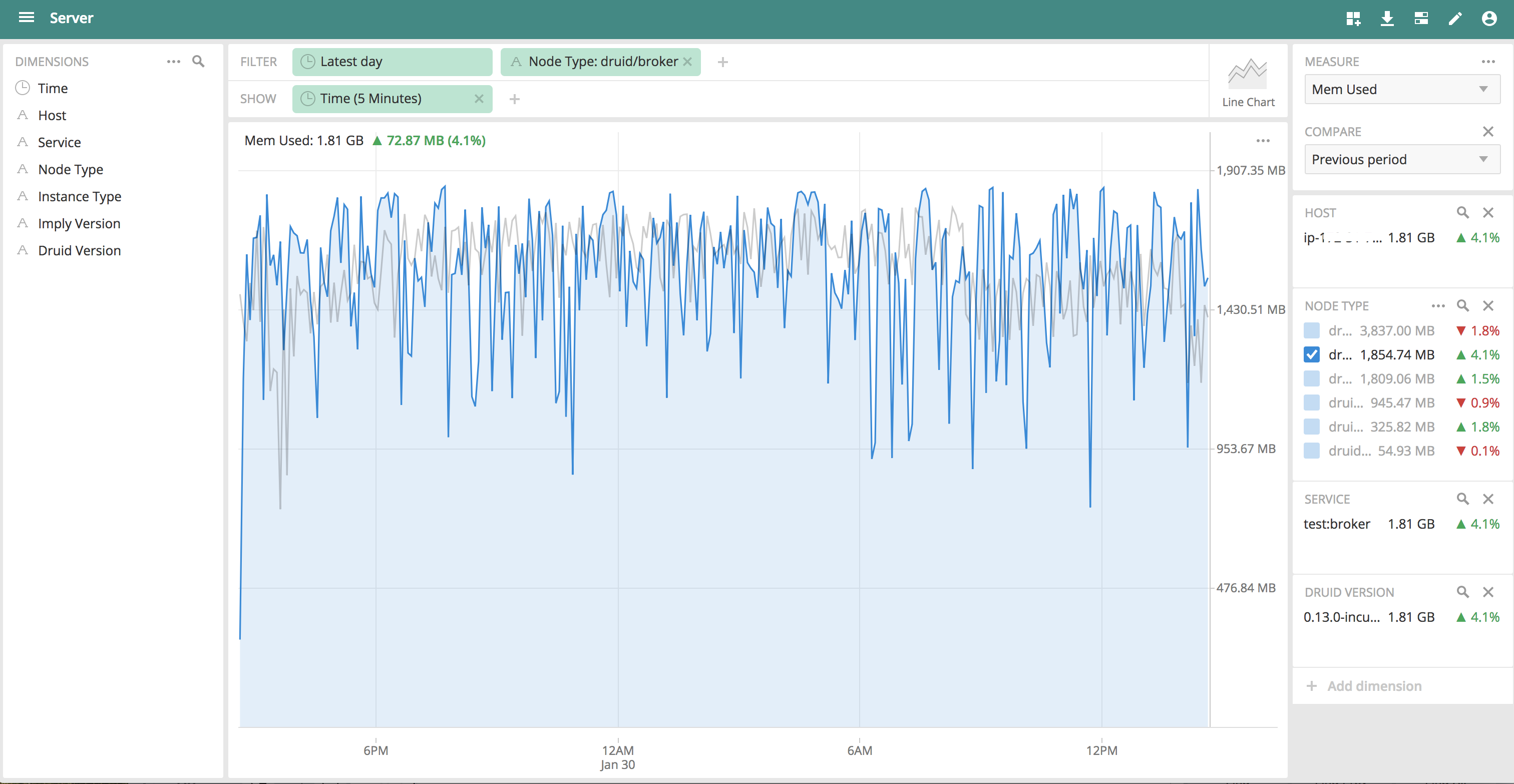
This is used memory comparison on our test broker over a day with about 67K segments, grey line is without this patch and blue line is with this patch. There is slightly higher memory usage with current published segments cache on broker. |
| @Override | ||
| public Void call() | ||
| { | ||
| poll(); |
There was a problem hiding this comment.
I think it's important to let users know if poll() fails. Please revert logging back. Probably it's worth to catch all exceptions like
try {
poll();
}
catch (Exception e) {
// emit exception
}There was a problem hiding this comment.
And since it catches all exceptions, PollTask can be Runnable.
There was a problem hiding this comment.
ok, catching all exceptions in the Runnable
| public Void call() | ||
| { | ||
| poll(); | ||
| scheduledExec.schedule(new PollTask(), DEFAULT_POLL_PERIOD_IN_MS, TimeUnit.MILLISECONDS); |
There was a problem hiding this comment.
This means the next poll would happen after DEFAULT_POLL_PERIOD_IN_MS which I don't think you intended here. You should probably check how long poll() took and compute the wait time for the next poll. It should be 0 if it already passed the next poll time.
There was a problem hiding this comment.
Added computing the delay after every poll() call
| public class MetadataSegmentView | ||
| { | ||
|
|
||
| private static final int DEFAULT_POLL_PERIOD_IN_MS = 60000; |
There was a problem hiding this comment.
Are you going to make this configurable? If so, please add a configuration. Otherwise, please rename to POLL_PERIOD_IN_MS.
There was a problem hiding this comment.
Yes, I'd want to make it configurable, may be in a follow-up PR. For now, i renamed the variable.
| private final BytesAccumulatingResponseHandler responseHandler; | ||
| private final BrokerSegmentWatcherConfig segmentWatcherConfig; | ||
|
|
||
| private final ConcurrentMap<DataSegment, DateTime> publishedSegments = new ConcurrentHashMap<>(); |
There was a problem hiding this comment.
I think the size of this map would be usually very large. It would be better to initialize with a larger initial size like 1000.
There was a problem hiding this comment.
yeah, right, will set initialCapacity
| segmentWatcherConfig.getWatchedDataSources() | ||
| ); | ||
| publishedSegments.keySet() | ||
| .removeIf(key -> !segmentWatcherConfig.getWatchedDataSources().contains(key.getDataSource())); |
There was a problem hiding this comment.
I think this is not needed now because getMetadataSegments() returns only filtered segments.
| if (watchedDataSources != null && !watchedDataSources.isEmpty()) { | ||
| final StringBuilder sb = new StringBuilder(); | ||
| for (String ds : watchedDataSources) { | ||
| sb.append("datasources=" + ds + "&"); |
There was a problem hiding this comment.
sb.append("datasources=").append(ds).append("&")
There was a problem hiding this comment.
You also need to delete the last &.
There was a problem hiding this comment.
yeah, doing that later by setting the sb length to sb.length()-1
There was a problem hiding this comment.
| for (String ds : watchedDataSources) { | ||
| sb.append("datasources=" + ds + "&"); | ||
| } | ||
| sb.setLength(Math.max(sb.length() - 1, 0)); |
There was a problem hiding this comment.
I think sb.length() is always larger than 0?
| import com.google.common.collect.Interners; | ||
| import org.apache.druid.timeline.DataSegment; | ||
|
|
||
| public class DataSegmentInterner |
There was a problem hiding this comment.
Would you please add a javadoc about what this is doing and why we need two interners?
There was a problem hiding this comment.
Interners with weak references shouldn't be used: #7395
|
|
||
| public static DataSegment intern(DataSegment segment) | ||
| { | ||
| return segment.getSize() > 0 ? HISTORICAL_INTERNER.intern(segment) : REALTIME_INTERNER.intern(segment); |
There was a problem hiding this comment.
It's worth to comment why size can be an indicator of a realtime or historical segment.
| private void poll() | ||
| { | ||
| log.info("polling published segments from coordinator"); | ||
| //get authorized published segments from coordinator |
There was a problem hiding this comment.
I guess this comment is not correct? The authorization happens in SystemSchema.
There was a problem hiding this comment.
ah yeah, since i copied over this code from SystemSchema . Will remove.
| // since the presence of a segment with an earlier timestamp indicates that | ||
| // "that" segment is not returned by coordinator in latest poll, so it's | ||
| // likely deleted and therefore we remove it from publishedSegments | ||
| publishedSegments.entrySet().removeIf(e -> e.getValue() != timestamp); |
There was a problem hiding this comment.
Would you please also add a comment about publishedSegments will be eventually consistent with the segments in the coordinator?
| if (pollTimeMs > POLL_PERIOD_IN_MS) { | ||
| delayMS = 0; | ||
| } else { | ||
| delayMS = pollTimeMs; |
There was a problem hiding this comment.
pollTimeMs is how long poll took, so probably delayMs = Math.max(POLL_PERIOD_IN_MS - pollTimeMs, 0)
| if (watchedDataSources != null && !watchedDataSources.isEmpty()) { | ||
| final StringBuilder sb = new StringBuilder(); | ||
| for (String ds : watchedDataSources) { | ||
| sb.append("datasources=" + ds + "&"); |
There was a problem hiding this comment.
|
@surekhasaharan thanks for checking the memory usage. Would you please add how many segments were in the cluster? |
At that time, there would be roughly around 67K segments. |
| try { | ||
| poll(); | ||
| } | ||
| finally { |
There was a problem hiding this comment.
Please add a catch block to emit exceptions.
| poll(); | ||
| } | ||
| finally { | ||
| scheduledExec.schedule(new PollTask(), 0, TimeUnit.MILLISECONDS); |
There was a problem hiding this comment.
Please set the proper wait time instead of starting poll() immediately.
There was a problem hiding this comment.
yeah, changed to use pollPeriodinMS
| { | ||
| if (isCacheEnabled) { | ||
| Preconditions.checkState( | ||
| lifecycleLock.awaitStarted(1, TimeUnit.MILLISECONDS), |
There was a problem hiding this comment.
Suggest changing this precondition check message to "lifecycle start not completed", since the lifecycle starting doesn't necessarily indicate that the cache is ready (the initial poll() might have failed).
We could adjust this class so that the publishedSegments map is initially null, and initialize it upon the first successful getMetadataSegments() call in poll(). Then, in this method, add a check for "map != null" with the "hold on, still syncing published segments" message if the check fails.
There was a problem hiding this comment.
made changes, so the message correctly implies that published segments are still syncing.
 clintropolis
left a comment
clintropolis
left a comment
There was a problem hiding this comment.
LGTM, is now 'opt in' behavior 👍
* Add published segment cache in broker * Change the DataSegment interner so it's not based on DataSEgment's equals only and size is preserved if set * Added a trueEquals to DataSegment class * Use separate interner for realtime and historical segments * Remove trueEquals as it's not used anymore, change log message * PR comments * PR comments * Fix tests * PR comments * Few more modification to * change the coordinator api * removeall segments at once from MetadataSegmentView in order to serve a more consistent view of published segments * Change the poll behaviour to avoid multiple poll execution at same time * minor changes * PR comments * PR comments * Make the segment cache in broker off by default * Added a config to PlannerConfig * Moved MetadataSegmentView to sql module * Add doc for new planner config * Update documentation * PR comments * some more changes * PR comments * fix test * remove unintentional change, whether to synchronize on lifecycleLock is still in discussion in PR * minor changes * some changes to initialization * use pollPeriodInMS * Add boolean cachePopulated to check if first poll succeeds * Remove poll from start() * take the log message out of condition in stop()
| if (datasources != null && !datasources.isEmpty()) { | ||
| druidDataSources = druidDataSources.stream() | ||
| .filter(src -> datasources.contains(src.getName())) | ||
| .collect(Collectors.toSet()); |
There was a problem hiding this comment.
@surekhasaharan we don't want to collect ImmutableDruidDataSource objects, which are already known to be unique here, into a set. It induces expensive O(n) hash code computations (which is also totally unnecessary; ImmutableDruidDataSource.hashCode() should be cheaper. But that's another question.)
There was a problem hiding this comment.
thanks @leventov for catching this, will change to list in a follow up PR.
| { | ||
| if (isCacheEnabled) { | ||
| Preconditions.checkState( | ||
| lifecycleLock.awaitStarted(1, TimeUnit.MILLISECONDS) && cachePopulated.get(), |
There was a problem hiding this comment.
How is the client of this method expected to wait until cachePopulated contains true without running into IllegalStateException?
There was a problem hiding this comment.
yeah, client would get IllegalStateException with the error message hold on, still syncing published segments, and they'll have to retry.
| Set<String> watchedDataSources | ||
| ) | ||
| { | ||
| String query = "/druid/coordinator/v1/metadata/segments"; |
There was a problem hiding this comment.
ok, will check that, thanks.
| } | ||
| } | ||
|
|
||
| // Note that coordinator must be up to get segments |
| } | ||
| finally { | ||
| if (!Thread.currentThread().isInterrupted()) { | ||
| scheduledExec.schedule(new PollTask(), delayMS, TimeUnit.MILLISECONDS); |
There was a problem hiding this comment.
Why doesn't this class use ScheduledExecutorService.sheduleAtFixedRate() or sheduleWithFixedDelay()?
There was a problem hiding this comment.
i changed to use schedule because if poll is executed with fixed delay, there might be a possibility of two or more polls to be executed at the same time, if there's huge GC or getMetadataSegments takes longer than poll period.
There was a problem hiding this comment.
Both scheduleAtFixedRate and sheduleWithFixedDelay explicitly prohibit concurrent execution in their Javadocs. Also, this is not imaginably possible, because your sheduledExec has only a single thread.
| throw new ISE("can't start."); | ||
| } | ||
| try { | ||
| if (isCacheEnabled) { |
There was a problem hiding this comment.
Looks like this class violates the Single Responsibility Principle, see #7392.
There was a problem hiding this comment.
hmm I need to read up more on Single Responsibility Principle, another way to look at it, is the responsibility of this class is to get metadata segments, the public method is getPublishedSegments, then it kind of does one thing i.e. get metadata segments.
There was a problem hiding this comment.
Probably SRP is a wrong link in this case, cohesion may be a more correct reference. Anyway, it seems to me that isCacheEnabled replaces a perfectly healthy polymorphism "CachingMetadataSegmentView"/"DirectMetadataSegmentView" here. Somebody may want to add "CachingWithDirectMetadataStoreAccess" (vs. using Coordinator as a proxy), etc.
From the discussion [here](#6901 (comment)) Remove the collection and filter datasources from the stream. Also remove StreamingOutput and JsonFactory constructs.
This PR introduces a published segments cache on broker, as proposed in #6834 . This implements the "phase 1" of the proposal. Added a new class
MetadataSegmentViewwhich polls coordinator periodically to get published segments and maintains a synced copy of same in cache. Another change is to useDataSegmentInterner#INTERNERwhile storingDataSegmentobject inServerSelectorandMetadataSegmentViewin order reuse the reference for overlapping segments.Testing on our test cluster shows sub-second execution time for
sys.segmentsqueries which were taking multiple seconds without this patch.This feature is optional, it is turned off by default. It can be turned on by adding this config to broker
druid.sql.planner.metadataSegmentCacheEnable=true. To get better sys tables query performance, it should be turned on.Adding some memory comparison charts with and without the patch to compare broker heap, gc activity etc. These are one day's compares with more than 67K segments in our test cluster. Grey is without patch and blue line is with this patch. We can see that this patch causes slightly more used memory and higher GC activity, which is expected as it's collecting published segments from coordinator and as

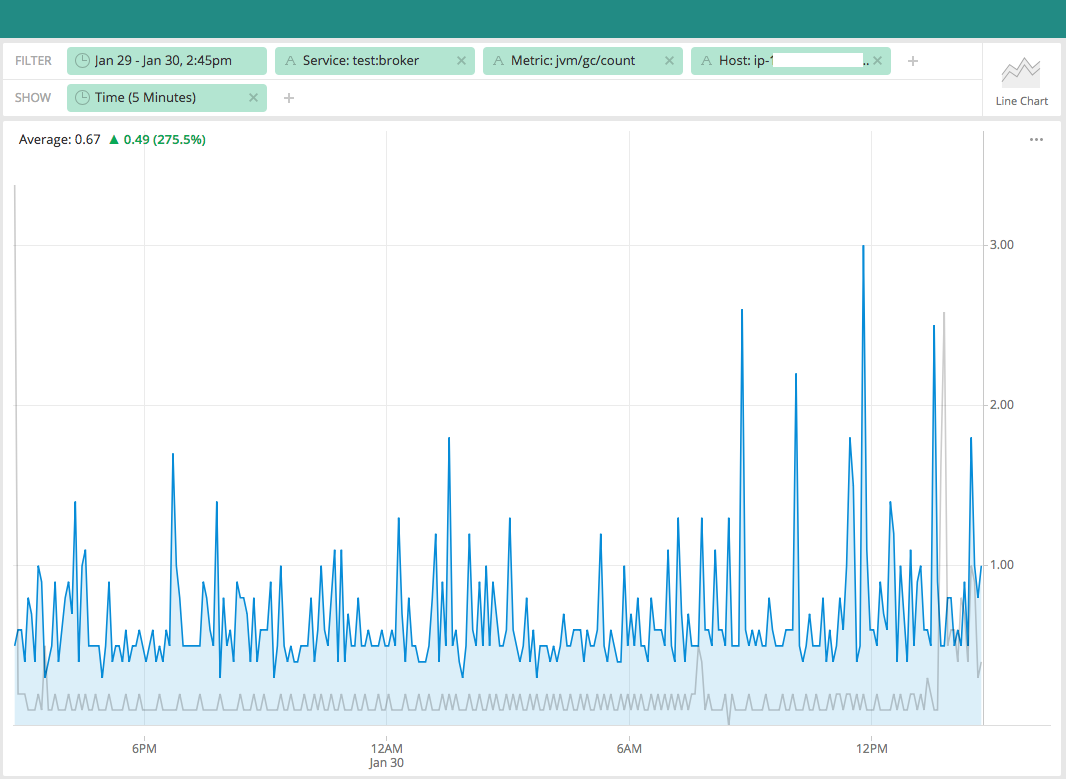
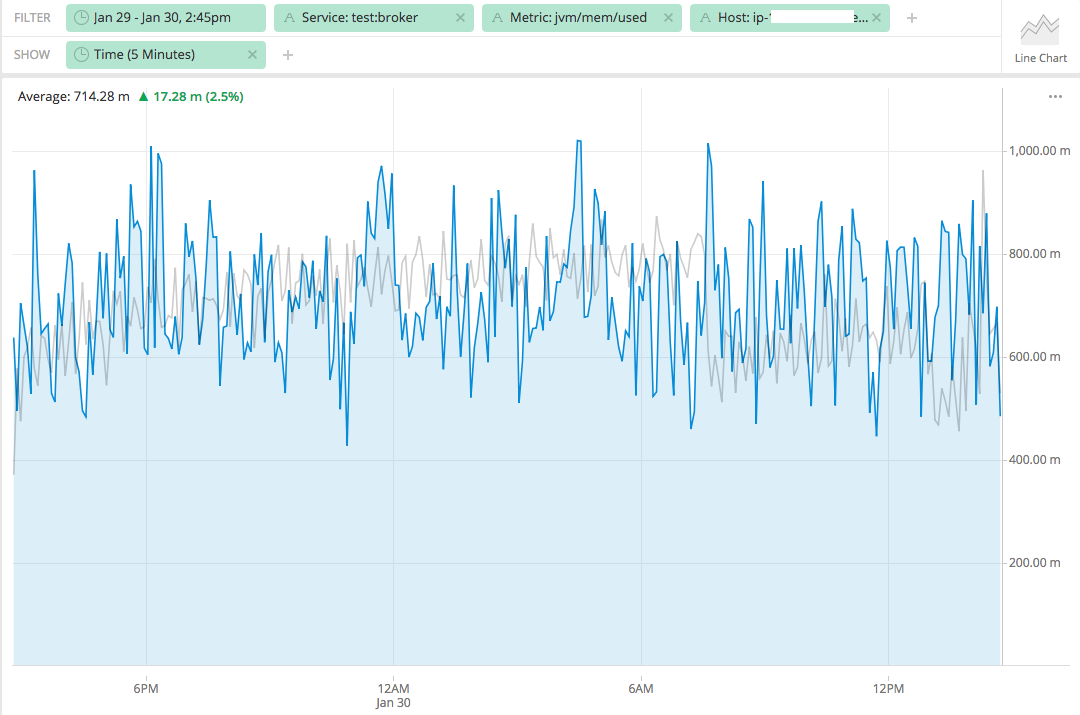
DataSegmentobjects are deserialized in broker and destroyed, so more GC activity is caused, but the overall used memory in broker heap is not much bigger than before.