Removing requirements for compute_sub_gradient to use sensitivity image #893
Conversation
|
Sorry, I thought a Draft PR didnt run Travis. It appears that using |
|
ok. we'll fix all the |
that'll have to be |
|
Need to fix the documentation regarding sensitivities: |
95e1fb2 to
a24b062
Compare
|
Interestingly the I think this is due to a normalisation issue with the new implementation that is caused by STIR's relucatnce to apply normalisation during the gradient computation and previous handling using the sensitivity subtraction. Let me try and explain. The gradient computation does not want/or need the normalisation ( STIR/src/recon_buildblock/PoissonLogLikelihoodWithLinearModelForMeanAndProjData.cxx Lines 1207 to 1217 in dc6f356 This is because it utilised the mathmatical shortcut:
If this is the case, this PR modification might need some tweaking. Rather than subtracting ones, it should subtract |
|
Test passes on my end. I get the same result (ish) gradient: difference between Edit: This was fixed by fa9e87e |
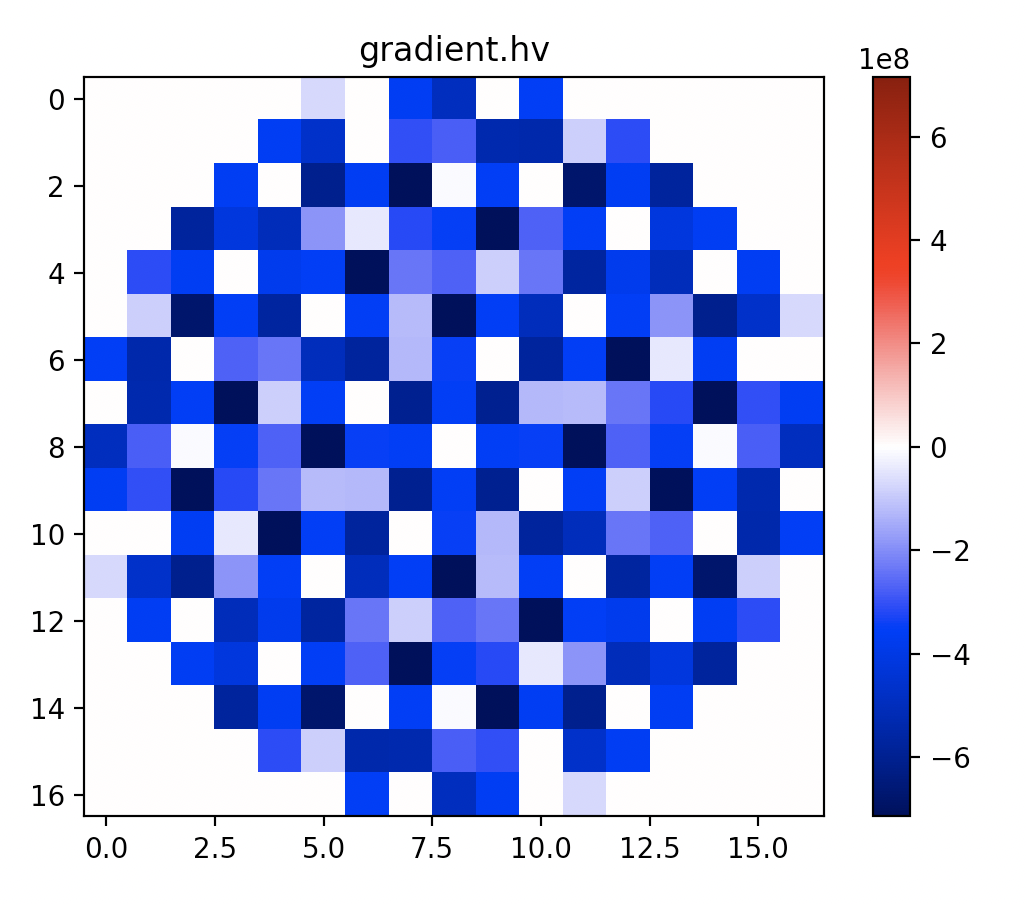
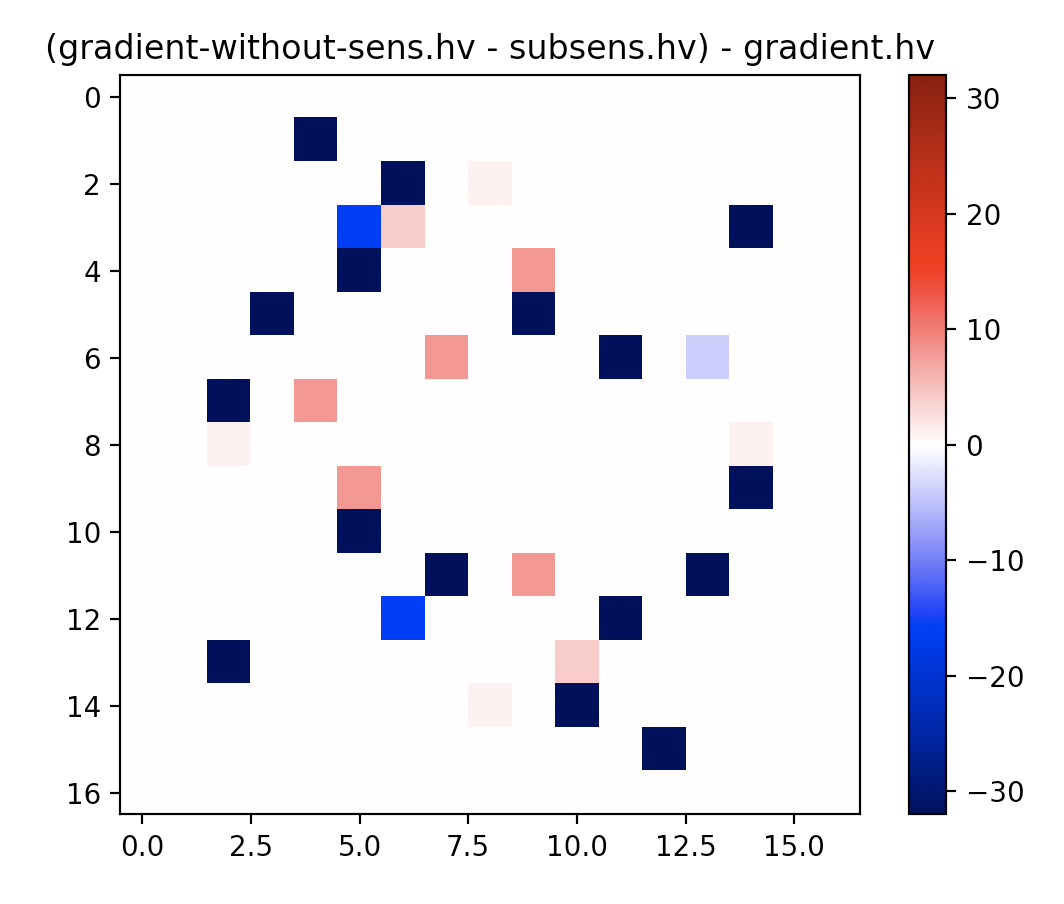
|
Test failing on OSSPS in recon_test_pack STIR/recon_test_pack/run_tests.sh Lines 231 to 246 in 42240de This PRThe error output The OSSPS reconstruction is fine, just the reconstructed image and reference are ~1% different. STIR MasterThe difference between the reference in STIR master are of magnetude e-04 % / e-05 %. DiscussionI think this is because the OSSPS reconstuction parameter file using Difference between master image and reference is virtually 0 Proposed SolutionReplace the OSSPS reference image. |
…ient_without_penalty
…o_subtraction is true
d43dc18 to
6b1af73
Compare
|
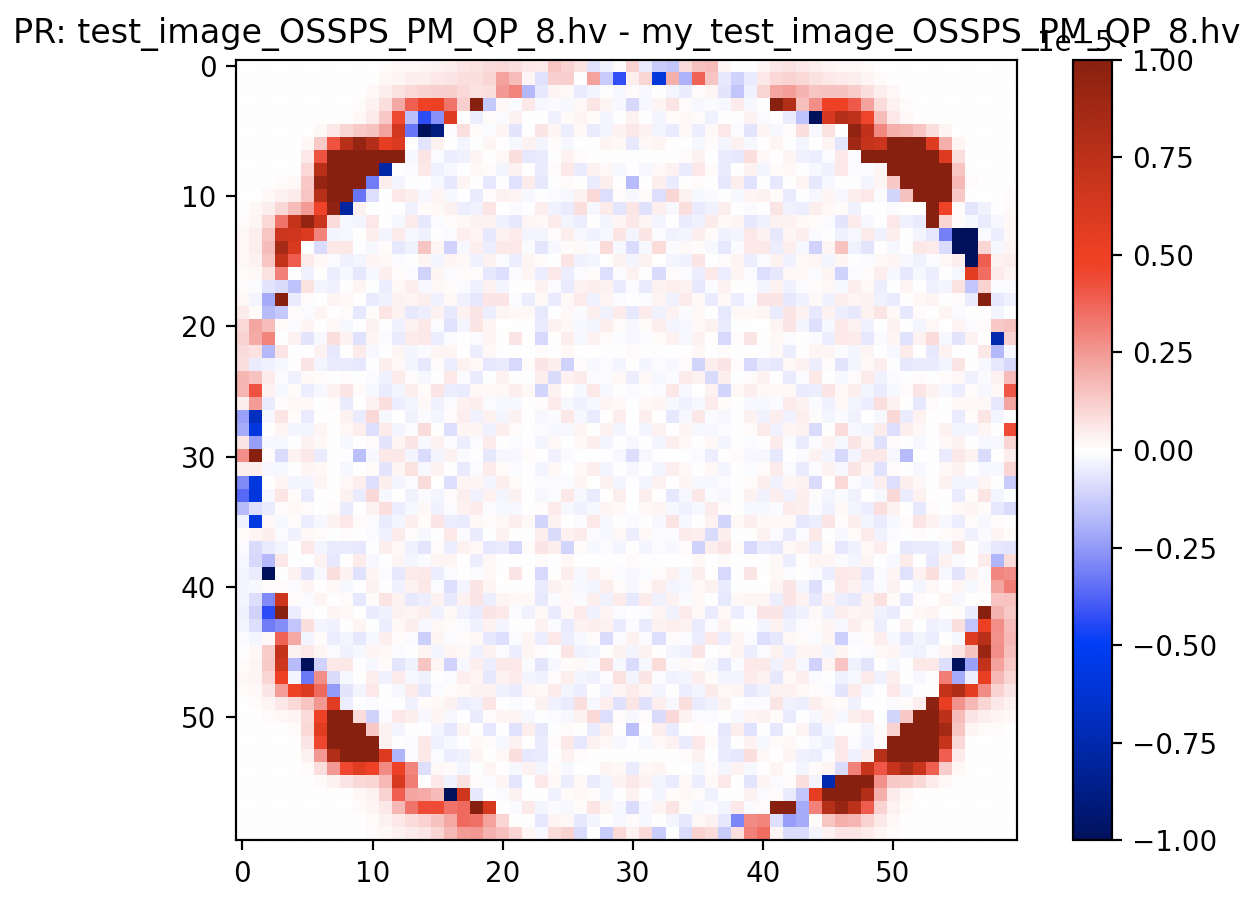
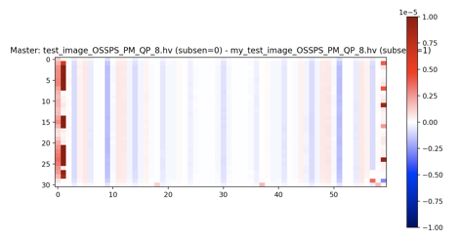
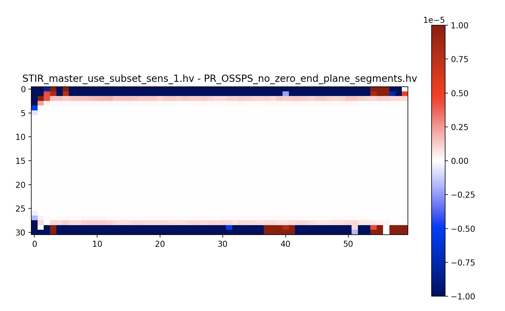
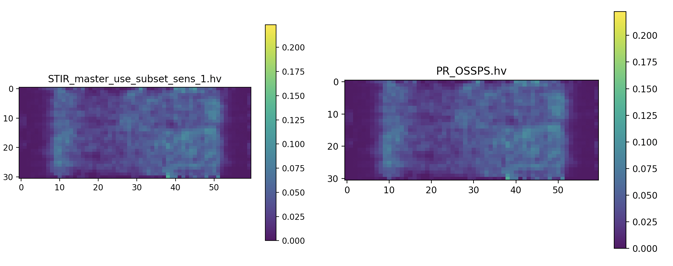
Now that I have confirmed that there is a difference between OSSPS when This image is coronal view (top/bottom are the end rings). Clearly there is an end plane issue but the majority of the interior is good. I tested to see if this was a subset sensitivity issue in STIR master but comparing the resulting images output by the test when This is affected by changing from Maybe this is a normalisation subtraction issue in the PR? The difference is subtle and does occur over 8 OSSPS sub-iterations with 4 subsets |
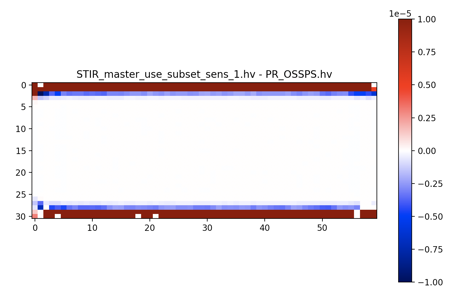
...stir/recon_buildblock/PoissonLogLikelihoodWithLinearKineticModelAndDynamicProjectionData.txx
Outdated
Show resolved
Hide resolved
src/include/stir/recon_buildblock/PoissonLogLikelihoodWithLinearModelForMean.h
Outdated
Show resolved
Hide resolved
src/include/stir/recon_buildblock/PoissonLogLikelihoodWithLinearModelForMean.h
Outdated
Show resolved
Hide resolved
src/include/stir/recon_buildblock/PoissonLogLikelihoodWithLinearModelForMean.h
Show resolved
Hide resolved
src/include/stir/recon_buildblock/PoissonLogLikelihoodWithLinearModelForMean.h
Outdated
Show resolved
Hide resolved
src/include/stir/recon_buildblock/PoissonLogLikelihoodWithLinearModelForMean.h
Outdated
Show resolved
Hide resolved
..._buildblock/PoissonLogLikelihoodWithLinearModelForMeanAndListModeDataWithProjMatrixByBin.cxx
Outdated
Show resolved
Hide resolved
src/recon_buildblock/PoissonLogLikelihoodWithLinearModelForMeanAndProjData.cxx
Outdated
Show resolved
Hide resolved
src/recon_buildblock/PoissonLogLikelihoodWithLinearModelForMeanAndProjData.cxx
Outdated
Show resolved
Hide resolved
…o the endplanes can be zeroed
…ld Poisson classes
..._buildblock/PoissonLogLikelihoodWithLinearModelForMeanAndListModeDataWithProjMatrixByBin.cxx
Outdated
Show resolved
Hide resolved
src/recon_buildblock/PoissonLogLikelihoodWithLinearModelForMeanAndProjData.cxx
Show resolved
Hide resolved
|
Major changes since last comments:
Marking as ready for review (pending travis). There are still a few issues:
Edit: Travis passed on previous major commit |
|
Ready for review |
rephrased release notes on the gradient computation changes [ci skip]
This is a fix for #873
Introduces the method
where the bool
do_subtraction(name needs to change) indicates to distributable and the gradient computation whether to do the gradient computation as:do_subtraction = true(e.g.compute_sub_gradient_without_penalty)or
do_subtraction = false(e.g.compute_sub_gradient_without_penalty_plus_sensitivity)