relu supports bfloat16 data type #32542
Conversation
|
Thanks for your contribution! |
|
|
||
| /* =========================== relu register ============================ */ | ||
| #ifdef PADDLE_WITH_HIP | ||
| REGISTER_ACTIVATION_GPU_KERNEL(relu, Relu, ReluGPUFunctor, ReluGradGPUFunctor); |
There was a problem hiding this comment.
修改之前CUDA上会执行REGISTER_ACTIVATION_GPU_KERNEL,修改后只在HIP上执行了吗?
There was a problem hiding this comment.
REGISTER_ACTIVATION_GPU_KERNEL宏逻辑为:
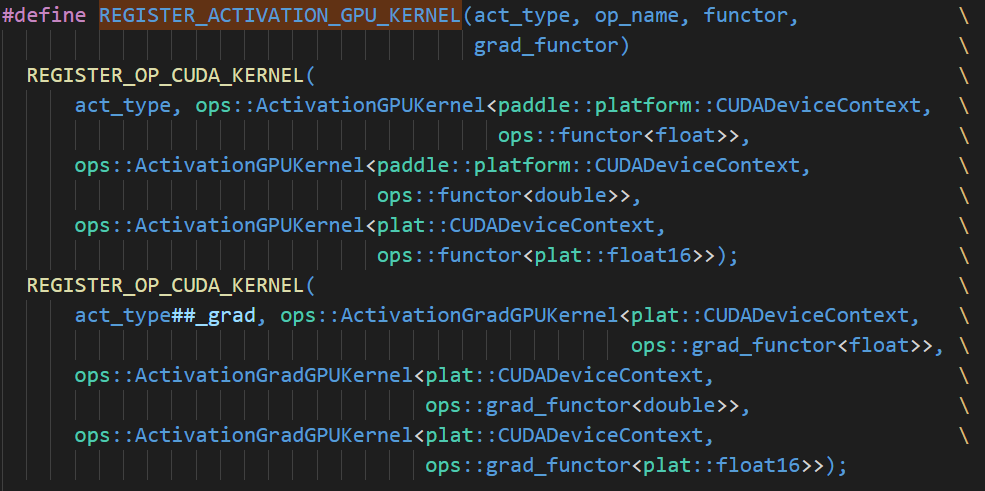
ROCM平台目前对于bfloat16编译存在问题,这里暂时先不在ROCM平台上支持。
| # set delta as np.float16, will automatic convert to float32, float64 | ||
| delta = np.array(delta).astype(np.float16) | ||
| elif tensor_to_check_dtype == core.VarDesc.VarType.BF16: | ||
| tensor_to_check_dtype = np.float32 |
There was a problem hiding this comment.
根据L127~L132,这里应该是将paddle的数据类型转换为对应的numpy的数据类型。所以core.VarDesc.VarType.BF16对应np.uint16吧
There was a problem hiding this comment.
BF16类型也是属于浮点型,这里为了单测代码更易读,选择使用float32而不是uint16作为结果检查的类型。
|
Describe中可以提供下单测结果 |
done |
| create_test_act_fp16_class(TestHardSwish) | ||
|
|
||
|
|
||
| #------------------ Test BF16 ---------------------- |
| "core is not compiled with CUDA") | ||
| class TestActBF16(parent): | ||
| def init_dtype(self): | ||
| self.dtype = np.uint16 |
There was a problem hiding this comment.
设置dtype为np.uint16,怎么能保证不是用的int16类型的kernel呢?能不能用字符串"bfloat16"?现在是设置dtype=uint16实际都是BF16?
There was a problem hiding this comment.
目前测试框架内使用np.uint16来测试bfloat16类型,其转换到paddle内为bfloat16类型,即设置dtype=np.uint16实际都是BF16。
| ops::ReluGradGradFunctor<plat::float16>>); | ||
| ops::ReluGradGradFunctor<plat::float16>>, | ||
| ops::ActivationDoubleGradKernel<plat::CUDADeviceContext, | ||
| ops::ReluGradGradFunctor<plat::bfloat16>>); |
There was a problem hiding this comment.
double grad验证过吗?如果没有的话,先不要注册。
| ops::ActivationGradGPUKernel<plat::CUDADeviceContext, | ||
| ops::ReluGradGPUFunctor<plat::float16>>, | ||
| ops::ActivationGradGPUKernel<plat::CUDADeviceContext, | ||
| ops::ReluGradGPUFunctor<plat::bfloat16>>); |
There was a problem hiding this comment.
现在relu调的是ActivationkernelVec和ActivationGradKernelVec这2个CUDA Kernel。核心计算在functor:
Paddle/paddle/fluid/operators/activation_op.cu
Lines 63 to 67 in 0372f1d
CudaVecType<bfloat16>没有特化,CudaVecType<bfloat16>::Type依然的是bfloat16类型。bfloat16类型对于>运算符的重载,比较运算是先强制转换成float后再比较的吧?确认一下。
Paddle/paddle/fluid/platform/bfloat16.h
Lines 283 to 285 in 6f6e159
float16类型是有重载这些运算符的。
There was a problem hiding this comment.
merge最新代码后,这块的代码有一些改变,已经不再使用特化的形式了。
paddle/fluid/operators/mean_op.cu
Outdated
| ops::MeanCUDAGradKernel<paddle::platform::CUDADeviceContext, plat::float16>, | ||
| ops::MeanCUDAGradKernel<paddle::platform::CUDADeviceContext, | ||
| plat::float16>); | ||
| plat::bfloat16>); |
There was a problem hiding this comment.
fill_constant和mean为啥要注册bfloat16类型呢?是因为单测框架里面会用到吗?单测框架除了要测试的op外,其他op能不能都改成使用fp32类型?fill_constant倒没有问题,mean可能会引入较大的误差。
There was a problem hiding this comment.
已取消fill_constant和mean的注册,改为增加转换成fp32步骤。
|
Sorry to inform you that 7a26ab6's CIs have passed for more than 7 days. To prevent PR conflicts, you need to re-run all CIs manually. |

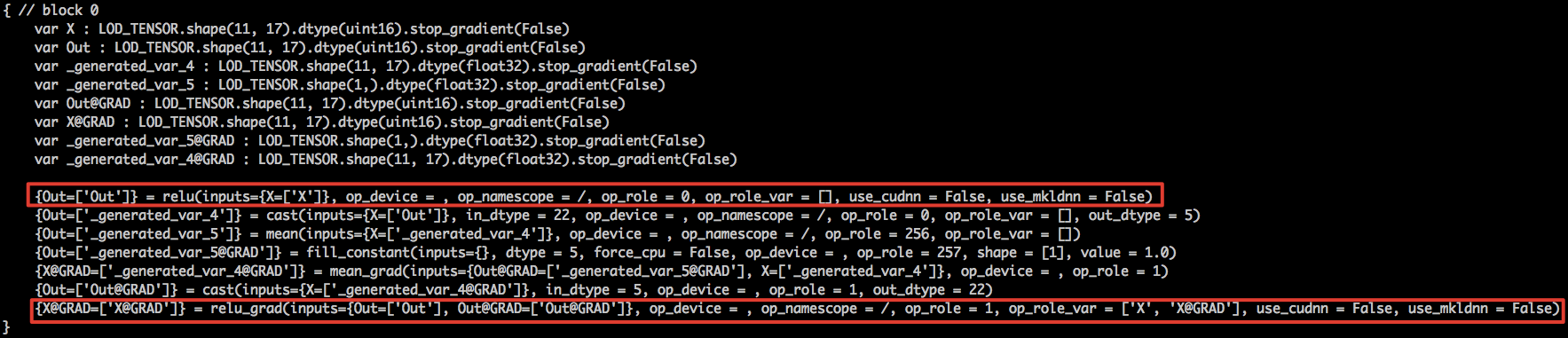
| ops::ReluGradGradFunctor<plat::float16>>); | ||
| ops::ReluGradGradFunctor<plat::float16>>, | ||
| ops::ActivationDoubleGradKernel<plat::CUDADeviceContext, | ||
| ops::ReluGradGradFunctor<plat::bfloat16>>); |
| ops::CastOpKernel<paddle::platform::CUDADeviceContext, | ||
| paddle::platform::complex64>, | ||
| ops::CastOpKernel<paddle::platform::CUDADeviceContext, | ||
| paddle::platform::complex128>); |
| numpy_tensor = np.array(tensor).astype(np.uint16) | ||
| numpy_tensor = numpy_tensor.flatten() | ||
| return struct.unpack('<f', struct.pack('<I', numpy_tensor[i] | ||
| << 16))[0] |
There was a problem hiding this comment.
这个是将uint16转换成bf16?后续可以封装成一个比较通用的函数。
| no_grad_set) | ||
| fp32_grads = [] | ||
| for grad in dygraph_grad: | ||
| if grad.dtype == np.uint16: |
There was a problem hiding this comment.
语义上是bfloat16,最好字面上也是通过bfloat16判断,因为有一些op可能真的支持uint16类型的计算。或者至少要加一些注释。
下同。
| for grad in dygraph_grad: | ||
| if grad.dtype == np.uint16: | ||
| grad = convert_uint16_to_float(grad) | ||
| max_relative_error = 0.03 |
There was a problem hiding this comment.
目前与cpu上bf16的设置逻辑先保持一致。
PR types
Others
PR changes
Others
Describe
relu支持bfloat16数据类型。
使用V100 + CUDA11.0 + cudnn8.0 测试如下:
相对误差在0.01以下。