diff --git a/.new_docs/cn/faq/add_new_model.md b/.new_docs/cn/faq/add_new_model.md
deleted file mode 100644
index ab5afb9b2fb..00000000000
--- a/.new_docs/cn/faq/add_new_model.md
+++ /dev/null
@@ -1,268 +0,0 @@
-# FastDeploy外部模型集成指引
-
-在FastDeploy里面新增一个模型,包括增加C++/Python的部署支持。 本文以torchvision v0.12.0中的ResNet50模型为例,介绍使用FastDeploy做外部[模型集成](#modelsupport),具体包括如下3步。
-
-| 步骤 | 说明 | 创建或修改的文件 |
-|:------:|:-------------------------------------:|:---------------------------------------------:|
-| [1](#step2) | 在fastdeploy/vision相应任务模块增加模型实现 | resnet.h、resnet.cc、vision.h |
-| [2](#step4) | 通过pybind完成Python接口绑定 | resnet_pybind.cc、classification_pybind.cc |
-| [3](#step5) | 实现Python相应调用接口 | resnet.py、\_\_init\_\_.py |
-
-在完成上述3步之后,一个外部模型就集成好了。
-
-如果您想为FastDeploy贡献代码,还需要为新增模型添加测试代码、说明文档和代码注释,可在[测试](#test)中查看。
-## 模型集成
-
-### 模型准备
-
-
-在集成外部模型之前,先要将训练好的模型(.pt,.pdparams 等)转换成FastDeploy支持部署的模型格式(.onnx,.pdmodel)。多数开源仓库会提供模型转换脚本,可以直接利用脚本做模型的转换。由于torchvision没有提供转换脚本,因此手动编写转换脚本,本文中将 `torchvison.models.resnet50` 转换为 `resnet50.onnx`, 参考代码如下:
-
-```python
-import torch
-import torchvision.models as models
-model = models.resnet50(pretrained=True)
-batch_size = 1 #批处理大小
-input_shape = (3, 224, 224) #输入数据,改成自己的输入shape
-model.eval()
-x = torch.randn(batch_size, *input_shape) # 生成张量
-export_onnx_file = "resnet50.onnx" # 目的ONNX文件名
-torch.onnx.export(model,
- x,
- export_onnx_file,
- opset_version=12,
- input_names=["input"], # 输入名
- output_names=["output"], # 输出名
- dynamic_axes={"input":{0:"batch_size"}, # 批处理变量
- "output":{0:"batch_size"}})
-```
-执行上述脚本将会得到 `resnet50.onnx` 文件。
-
-### C++部分
-* 创建`resnet.h`文件
- * 创建位置
- * FastDeploy/fastdeploy/vision/classification/contrib/resnet.h (FastDeploy/C++代码存放位置/视觉模型/任务名称/外部模型/模型名.h)
- * 创建内容
- * 首先在resnet.h中创建 ResNet类并继承FastDeployModel父类,之后声明`Predict`、`Initialize`、`Preprocess`、`Postprocess`和`构造函数`,以及必要的变量,具体的代码细节请参考[resnet.h](https://github.com/PaddlePaddle/FastDeploy/pull/347/files#diff-69128489e918f305c208476ba793d8167e77de2aa7cadf5dcbac30da448bd28e)。
-
-```C++
-class FASTDEPLOY_DECL ResNet : public FastDeployModel {
- public:
- ResNet(...);
- virtual bool Predict(...);
- private:
- bool Initialize();
- bool Preprocess(...);
- bool Postprocess(...);
-};
-```
-
-* 创建`resnet.cc`文件
- * 创建位置
- * FastDeploy/fastdeploy/vision/classification/contrib/resnet.cc (FastDeploy/C++代码存放位置/视觉模型/任务名称/外部模型/模型名.cc)
- * 创建内容
- * 在`resnet.cc`中实现`resnet.h`中声明函数的具体逻辑,其中`PreProcess` 和 `PostProcess`需要参考源官方库的前后处理逻辑复现,ResNet每个函数具体逻辑如下,具体的代码请参考[resnet.cc](https://github.com/PaddlePaddle/FastDeploy/pull/347/files#diff-d229d702de28345253a53f2a5839fd2c638f3d32fffa6a7d04d23db9da13a871)。
-
-```C++
-ResNet::ResNet(...) {
- // 构造函数逻辑
- // 1. 指定 Backend 2. 设置RuntimeOption 3. 调用Initialize()函数
-}
-bool ResNet::Initialize() {
- // 初始化逻辑
- // 1. 全局变量赋值 2. 调用InitRuntime()函数
- return true;
-}
-bool ResNet::Preprocess(Mat* mat, FDTensor* output) {
-// 前处理逻辑
-// 1. Resize 2. BGR2RGB 3. Normalize 4. HWC2CHW 5. 处理结果存入 FDTensor类中
- return true;
-}
-bool ResNet::Postprocess(FDTensor& infer_result, ClassifyResult* result, int topk) {
- //后处理逻辑
- // 1. Softmax 2. Choose topk labels 3. 结果存入 ClassifyResult类
- return true;
-}
-bool ResNet::Predict(cv::Mat* im, ClassifyResult* result, int topk) {
- Preprocess(...)
- Infer(...)
- Postprocess(...)
- return true;
-}
-```
-
-* 在`vision.h`文件中加入新增模型文件
- * 修改位置
- * FastDeploy/fastdeploy/vision.h
- * 修改内容
-
-```C++
-#ifdef ENABLE_VISION
-#include "fastdeploy/vision/classification/contrib/resnet.h"
-#endif
-```
-
-
-### Pybind部分
-
-* 创建Pybind文件
- * 创建位置
- * FastDeploy/fastdeploy/vision/classification/contrib/resnet_pybind.cc (FastDeploy/C++代码存放位置/视觉模型/任务名称/外部模型/模型名_pybind.cc)
- * 创建内容
- * 利用Pybind将C++中的函数变量绑定到Python中,具体代码请参考[resnet_pybind.cc](https://github.com/PaddlePaddle/FastDeploy/pull/347/files#diff-270af0d65720310e2cfbd5373c391b2110d65c0f4efa547f7b7eeffcb958bdec)。
-```C++
-void BindResNet(pybind11::module& m) {
- pybind11::class_(
- m, "ResNet")
- .def(pybind11::init())
- .def("predict", ...)
- .def_readwrite("size", &vision::classification::ResNet::size)
- .def_readwrite("mean_vals", &vision::classification::ResNet::mean_vals)
- .def_readwrite("std_vals", &vision::classification::ResNet::std_vals);
-}
-```
-
-* 调用Pybind函数
- * 修改位置
- * FastDeploy/fastdeploy/vision/classification/classification_pybind.cc (FastDeploy/C++代码存放位置/视觉模型/任务名称/任务名称}_pybind.cc)
- * 修改内容
-```C++
-void BindResNet(pybind11::module& m);
-void BindClassification(pybind11::module& m) {
- auto classification_module =
- m.def_submodule("classification", "Image classification models.");
- BindResNet(classification_module);
-}
-```
-
-
-### Python部分
-
-
-* 创建`resnet.py`文件
- * 创建位置
- * FastDeploy/python/fastdeploy/vision/classification/contrib/resnet.py (FastDeploy/Python代码存放位置/fastdeploy/视觉模型/任务名称/外部模型/模型名.py)
- * 创建内容
- * 创建ResNet类继承自FastDeployModel,实现 `\_\_init\_\_`、Pybind绑定的函数(如`predict()`)、以及`对Pybind绑定的全局变量进行赋值和获取的函数`,具体代码请参考[resnet.py](https://github.com/PaddlePaddle/FastDeploy/pull/347/files#diff-a4dc5ec2d450e91f1c03819bf314c238b37ac678df56d7dea3aab7feac10a157)。
-
-```python
-
-class ResNet(FastDeployModel):
- def __init__(self, ...):
- self._model = C.vision.classification.ResNet(...)
- def predict(self, input_image, topk=1):
- return self._model.predict(input_image, topk)
- @property
- def size(self):
- return self._model.size
- @size.setter
- def size(self, wh):
- ...
-```
-
-* 导入ResNet类
- * 修改位置
- * FastDeploy/python/fastdeploy/vision/classification/\_\_init\_\_.py (FastDeploy/Python代码存放位置/fastdeploy/视觉模型/任务名称/\_\_init\_\_.py)
- * 修改内容
-
-```Python
-from .contrib.resnet import ResNet
-```
-
-## 测试
-### 编译
- * C++
- * 位置:FastDeploy/
-
-```
-mkdir build & cd build
-cmake .. -DENABLE_ORT_BACKEND=ON -DENABLE_VISION=ON -DCMAKE_INSTALL_PREFIX=${PWD/fastdeploy-0.0.3
--DENABLE_PADDLE_BACKEND=ON -DENABLE_TRT_BACKEND=ON -DWITH_GPU=ON -DTRT_DIRECTORY=/PATH/TO/TensorRT/
-make -j8
-make install
-```
-
- 编译会得到 build/fastdeploy-0.0.3/。
-
- * Python
- * 位置:FastDeploy/python/
-
-```
-export TRT_DIRECTORY=/PATH/TO/TensorRT/ # 如果用TensorRT 需要填写TensorRT所在位置,并开启 ENABLE_TRT_BACKEND
-export ENABLE_TRT_BACKEND=ON
-export WITH_GPU=ON
-export ENABLE_PADDLE_BACKEND=ON
-export ENABLE_OPENVINO_BACKEND=ON
-export ENABLE_VISION=ON
-export ENABLE_ORT_BACKEND=ON
-python setup.py build
-python setup.py bdist_wheel
-cd dist
-pip install fastdeploy_gpu_python-版本号-cpxx-cpxxm-系统架构.whl
-```
-
-### 编写测试代码
- * 创建位置: FastDeploy/examples/vision/classification/resnet/ (FastDeploy/示例目录/视觉模型/任务名称/模型名/)
- * 创建目录结构
-
-```
-.
-├── cpp
-│ ├── CMakeLists.txt
-│ ├── infer.cc // C++ 版本测试代码
-│ └── README.md // C++版本使用文档
-├── python
-│ ├── infer.py // Python 版本测试代码
-│ └── README.md // Python版本使用文档
-└── README.md // ResNet 模型集成说明文档
-```
-
-* C++
- * 编写CmakeLists文件、C++ 代码以及 README.md 内容请参考[cpp/](https://github.com/PaddlePaddle/FastDeploy/pull/347/files#diff-afcbe607b796509581f89e38b84190717f1eeda2df0419a2ac9034197ead5f96)。
- * 编译 infer.cc
- * 位置:FastDeploy/examples/vision/classification/resnet/cpp/
-
-```
-mkdir build & cd build
-cmake .. -DFASTDEPLOY_INSTALL_DIR=/PATH/TO/FastDeploy/build/fastdeploy-0.0.3/
-make
-```
-
-* Python
- * Python 代码以及 README.md 内容请参考[python/](https://github.com/PaddlePaddle/FastDeploy/pull/347/files#diff-5a0d6be8c603a8b81454ac14c17fb93555288d9adf92bbe40454449309700135)。
-
-### 为代码添加注释
-为了方便用户理解代码,我们需要为新增代码添加注释,添加注释方法可参考如下示例。
-- C++ 代码
-您需要在resnet.h文件中为函数和变量增加注释,有如下三种注释方式,具体可参考[resnet.h](https://github.com/PaddlePaddle/FastDeploy/pull/347/files#diff-69128489e918f305c208476ba793d8167e77de2aa7cadf5dcbac30da448bd28e)。
-
-```C++
-/** \brief Predict for the input "im", the result will be saved in "result".
-*
-* \param[in] im Input image for inference.
-* \param[in] result Saving the inference result.
-* \param[in] topk The length of return values, e.g., if topk==2, the result will include the 2 most possible class label for input image.
-*/
-virtual bool Predict(cv::Mat* im, ClassifyResult* result, int topk = 1);
-
-/// Tuple of (width, height)
-std::vector size;
-/*! @brief Initialize for ResNet model, assign values to the global variables and call InitRuntime()
-*/
-bool Initialize();
-```
-- Python 代码
-你需要为resnet.py文件中的函数和变量增加适当的注释,示例如下,具体可参考[resnet.py](https://github.com/PaddlePaddle/FastDeploy/pull/347/files#diff-a4dc5ec2d450e91f1c03819bf314c238b37ac678df56d7dea3aab7feac10a157)。
-
-```python
- def predict(self, input_image, topk=1):
- """Classify an input image
-
- :param input_image: (numpy.ndarray)The input image data, 3-D array with layout HWC, BGR format
- :param topk: (int)The topk result by the classify confidence score, default 1
- :return: ClassifyResult
- """
- return self._model.predict(input_image, topk)
-```
-
-对于集成模型过程中的其他文件,您也可以对实现的细节添加适当的注释说明。
diff --git a/docs/api_docs/python/index.rst b/docs/api_docs/python/index.rst
index 5761cd3a511..873f83489a9 100644
--- a/docs/api_docs/python/index.rst
+++ b/docs/api_docs/python/index.rst
@@ -18,3 +18,4 @@ FastDeploy
image_classification.md
keypoint_detection.md
matting.md
+ vision_results_en.md
diff --git a/docs/api_docs/python/vision_results_en.md b/docs/api_docs/python/vision_results_en.md
index a7ae54a5709..513a011d7a3 100644
--- a/docs/api_docs/python/vision_results_en.md
+++ b/docs/api_docs/python/vision_results_en.md
@@ -1,5 +1,7 @@
# Description of Vision Results
+本文档的中文版本参考[视觉模型预测结果说明](./vision_results_cn.md)
+
## ClassifyResult
The code of ClassifyResult is defined in `fastdeploy/vision/common/result.h` and is used to indicate the classification label result and confidence the image.
diff --git a/docs/cn/build_and_install/android.md b/docs/cn/build_and_install/android.md
index c091b75d550..899ec2985a5 100644
--- a/docs/cn/build_and_install/android.md
+++ b/docs/cn/build_and_install/android.md
@@ -1,3 +1,105 @@
# Android部署库编译
-进行中...
+FastDeploy当前在Android仅支持Paddle-Lite后端推理,支持armeabi-v7a和arm64-v8a两种cpu架构,在armv8.2架构的arm设备支持fp16精度推理。相关编译选项说明如下:
+
+|编译选项|默认值|说明|备注|
+|:---|:---|:---|:---|
+|ENABLE_LITE_BACKEND|OFF|编译Android库时需要设置为ON| - |
+|WITH_OPENCV_STATIC|OFF|是否使用OpenCV静态库| - |
+|WITH_LITE_STATIC|OFF|是否使用Lite静态库| 暂不支持使用Lite静态库 |
+|WITH_LITE_FULL_API|ON|是否使用Lite Full API库| 目前必须为ON |
+|WITH_LITE_FP16|OFF|是否使用带FP16支持的Lite库| 目前仅支持 arm64-v8a 架构|
+
+更多编译选项请参考[FastDeploy编译选项说明](./README.md)
+
+## Android C++ SDK 编译安装
+
+编译需要满足:
+
+- Android SDK API >= 21
+- Android NDK >= 20 (当前仅支持clang编译工具链)
+- cmake >= 3.10.0
+
+编译前请先检查您的Android SDK 和 NDK 是否已经配置,如:
+```bash
+➜ echo $ANDROID_SDK
+/Users/xxx/Library/Android/sdk
+➜ echo $ANDROID_NDK
+/Users/xxx/Library/Android/sdk/ndk/25.1.8937393
+```
+推荐使用 NDK>=20 进行交叉编译,编译命令如下:
+```bash
+# Download the latest source code
+git clone https://github.com/PaddlePaddle/FastDeploy.git
+cd FastDeploy
+
+# Setting up Android toolchanin
+ANDROID_ABI=arm64-v8a # 'arm64-v8a', 'armeabi-v7a'
+ANDROID_PLATFORM="android-21" # API >= 21
+ANDROID_STL=c++_shared # 'c++_shared', 'c++_static'
+ANDROID_TOOLCHAIN=clang # 'clang' only
+TOOLCHAIN_FILE=${ANDROID_NDK}/build/cmake/android.toolchain.cmake
+
+# Create build directory
+BUILD_ROOT=build/Android
+BUILD_DIR=${BUILD_ROOT}/${ANDROID_ABI}-api-21
+FASDEPLOY_INSTALL_DIR="${BUILD_DIR}/install"
+mkdir build && mkdir ${BUILD_ROOT} && mkdir ${BUILD_DIR}
+cd ${BUILD_DIR}
+
+# Check fp16 support (only support arm64-v8a now)
+WITH_LITE_FP16=ON
+if [ "$ANDROID_ABI" = "armeabi-v7a" ]; then
+ WITH_LITE_FP16=OFF
+fi
+
+# CMake configuration with Android toolchain
+cmake -DCMAKE_TOOLCHAIN_FILE=${TOOLCHAIN_FILE} \
+ -DCMAKE_BUILD_TYPE=MinSizeRel \
+ -DANDROID_ABI=${ANDROID_ABI} \
+ -DANDROID_NDK=${ANDROID_NDK} \
+ -DANDROID_PLATFORM=${ANDROID_PLATFORM} \
+ -DANDROID_STL=${ANDROID_STL} \
+ -DANDROID_TOOLCHAIN=${ANDROID_TOOLCHAIN} \
+ -DENABLE_LITE_BACKEND=ON \
+ -DENABLE_VISION=ON \
+ -DWITH_LITE_FP16=${WITH_LITE_FP16} \
+ -DCMAKE_INSTALL_PREFIX=${FASDEPLOY_INSTALL_DIR} \
+ -Wno-dev ../../..
+
+# Build FastDeploy Android C++ SDK
+make -j8
+make install
+```
+编译完成后,Android C++ SDK 保存在 `build/Android/arm64-v8a-api-21/install` 目录下,目录结构如下:
+```bash
+➜ tree . -d -L 3
+.
+├── examples
+├── include
+│ └── fastdeploy # FastDeploy 头文件
+├── lib
+│ └── arm64-v8a # FastDeploy Android 动态库
+└── third_libs # 第三方依赖库
+ └── install
+ ├── opencv
+ └── paddlelite
+```
+在examples/vision目录下可查看Android C++ SDK 使用案例:
+```bash
+.
+├── classification
+│ ├── paddleclas
+│ │ ├── android # 图像分类Android使用案例
+│ │ ├── cpp
+...
+├── detection
+│ ├── paddledetection
+│ │ ├── android # 目标检测Android使用案例
+│ │ ├── cpp
+...
+```
+如何使用FastDeploy Android C++ SDK 请参考使用案例文档:
+- [图像分类Android使用文档](../../../examples/vision/classification/paddleclas/android/README.md)
+- [目标检测Android使用文档](../../../examples/vision/detection/paddledetection/android/README.md)
+- [在 Android 通过 JNI 中使用 FastDeploy C++ SDK](../../../../../docs/cn/faq/use_cpp_sdk_on_android.md)
diff --git a/docs/cn/build_and_install/download_prebuilt_libraries.md b/docs/cn/build_and_install/download_prebuilt_libraries.md
index a320b692440..9182aa69fc7 100644
--- a/docs/cn/build_and_install/download_prebuilt_libraries.md
+++ b/docs/cn/build_and_install/download_prebuilt_libraries.md
@@ -17,7 +17,7 @@ FastDeploy提供各平台预编译库,供开发者直接下载安装使用。
Release版本(当前最新0.3.0)安装
```bash
-pip install fastdeploy-gpu-python -f https://www.paddlepaddle.org.cn/whl/fastdeploy.html
+pip install fastdeploy-gpu-python -f https://www.paddlepaddle.org.cn/whl/fastdeploy.html
```
其中推荐使用Conda配置开发环境
@@ -51,7 +51,7 @@ pip install fastdeploy-python -f https://www.paddlepaddle.org.cn/whl/fastdeploy.
## C++ SDK安装
-Release版本(当前最新0.3.0)
+Release版本(当前最新0.3.0,Android为0.4.0 pre-release)
| 平台 | 文件 | 说明 |
| :--- | :--- | :---- |
@@ -59,5 +59,5 @@ Release版本(当前最新0.3.0)
| Windows x64 | [fastdeploy-win-x64-0.3.0.zip](https://bj.bcebos.com/fastdeploy/release/cpp/fastdeploy-win-x64-0.3.0.zip) | Visual Studio 16 2019编译产出 |
| Mac OSX x64 | [fastdeploy-osx-x86_64-0.3.0.tgz](https://bj.bcebos.com/fastdeploy/release/cpp/fastdeploy-osx-x86_64-0.3.0.tgz) | clang++ 10.0.0编译产出|
| Mac OSX arm64 | [fastdeploy-osx-arm64-0.3.0.tgz](https://bj.bcebos.com/fastdeploy/release/cpp/fastdeploy-osx-arm64-0.3.0.tgz) | clang++ 13.0.0编译产出 |
-| Linux aarch64 | [fastdeploy-linux-aarch64-0.3.0.tgz](https://bj.bcebos.com/fastdeploy/release/cpp/fastdeploy-linux-aarch64-0.3.0.tgz) | g++ 6.3.0编译产出 |
-
+| Linux aarch64 | [fastdeploy-linux-aarch64-0.3.0.tgz](https://bj.bcebos.com/fastdeploy/release/cpp/fastdeploy-linux-aarch64-0.3.0.tgz) | g++ 6.3.0编译产出 |
+| Android armv7&v8 | [fastdeploy-android-0.4.0-shared.tgz](https://bj.bcebos.com/fastdeploy/release/android/fastdeploy-android-0.4.0-shared.tgz) | NDK 25及clang++编译产出, 支持arm64-v8a及armeabi-v7a |
diff --git a/docs/cn/faq/use_cpp_sdk_on_android.md b/docs/cn/faq/use_cpp_sdk_on_android.md
new file mode 100644
index 00000000000..bdea635b4b2
--- /dev/null
+++ b/docs/cn/faq/use_cpp_sdk_on_android.md
@@ -0,0 +1,231 @@
+# 在 Android 中通过 JNI 使用 FastDeploy C++ SDK
+本文档将以PicoDet为例,讲解如何通过JNI,将FastDeploy中的模型封装到Android中进行调用。阅读本文档,您至少需要了解C++、Java、JNI以及Android的基础知识。如果您主要关注如何在Java层如何调用FastDeploy的API,则可以不阅读本文档。
+
+## 目录
+- [新建Java类并定义native API](#Java)
+- [Android Studio 生成JNI函数定义](#JNI)
+- [在C++层实现JNI函数](#CPP)
+- [编写CMakeLists.txt及配置build.gradle](#CMakeAndGradle)
+- [更多FastDeploy Android 使用案例](#Examples)
+
+## 新建Java类并定义native API
+
+
+```java
+public class PicoDet {
+ protected long mNativeModelContext = 0; // Context from native.
+ protected boolean mInitialized = false;
+ // ...
+ // Bind predictor from native context.
+ private static native long bindNative(String modelFile,
+ String paramsFile,
+ String configFile,
+ int cpuNumThread,
+ boolean enableLiteFp16,
+ int litePowerMode,
+ String liteOptimizedModelDir,
+ boolean enableRecordTimeOfRuntime,
+ String labelFile);
+
+ // Call prediction from native context.
+ private static native long predictNative(long nativeModelContext,
+ Bitmap ARGB8888Bitmap,
+ boolean saved,
+ String savedImagePath,
+ float scoreThreshold,
+ boolean rendering);
+
+ // Release buffers allocated in native context.
+ private static native boolean releaseNative(long nativeModelContext);
+
+ // Initializes at the beginning.
+ static {
+ FastDeployInitializer.init();
+ }
+}
+```
+这些被标记为native的接口是需要通过JNI的方式实现,并在Java层供PicoDet类调用。完整的PicoDet Java代码请参考 [PicoDet.java](../../../examples/vision/detection/paddledetection/android/app/src/main/java/com/baidu/paddle/fastdeploy/vision/detection/PicoDet.java) 。各个函数说明如下:
+- `bindNative`: C++层初始化模型资源,如果成功初始化,则返回指向该模型的指针(long类型),否则返回0指针
+- `predictNative`: 通过已经初始化好的模型指针,在C++层执行预测代码,如果预测成功则返回指向预测结果的指针,否则返回0指针。注意,该结果指针在当次预测使用完之后需要释放,具体操作请参考 [PicoDet.java](../../../examples/vision/detection/paddledetection/android/app/src/main/java/com/baidu/paddle/fastdeploy/vision/detection/PicoDet.java) 中的predict函数。
+- `releaseNative`: 根据传入的模型指针,在C++层释放模型资源。
+
+## Android Studio 生成JNI函数定义
+
+
+Android Studio 生成 JNI 函数定义: 鼠标停留在Java中定义的native函数上,Android Studio 便会提示是否要创建JNI函数定义;这里,我们把JNI函数定义创建在一个事先创建好的c++文件`picodet_jni.cc`上;
+
+- 使用Android Studio创建JNI函数定义:
+
+
+- 将JNI函数定义创建在picodet_jni.cc上:
+
+
+- 创建的JNI函数定义如下:
+
+
+其他native函数对应的JNI函数定义的创建和此流程一样。
+
+## 在C++层实现JNI函数
+
+
+以下为PicoDet JNI层实现的示例,相关的辅助函数不在此处赘述,完整的C++代码请参考 [android/app/src/main/cpp](../../../examples/vision/detection/paddledetection/android/app/src/main/cpp/).
+```C++
+#include // NOLINT
+#include "fastdeploy_jni.h" // NOLINT
+
+#ifdef __cplusplus
+extern "C" {
+#endif
+
+// 绑定C++层的模型
+JNIEXPORT jlong JNICALL
+Java_com_baidu_paddle_fastdeploy_vision_detection_PicoDet_bindNative(
+ JNIEnv *env, jclass clazz, jstring model_file, jstring params_file,
+ jstring config_file, jint cpu_num_thread, jboolean enable_lite_fp16,
+ jint lite_power_mode, jstring lite_optimized_model_dir,
+ jboolean enable_record_time_of_runtime, jstring label_file) {
+ std::string c_model_file = fastdeploy::jni::ConvertTo(env, model_file);
+ std::string c_params_file = fastdeploy::jni::ConvertTo(env, params_file);
+ std::string c_config_file = astdeploy::jni::ConvertTo(env, config_file);
+ std::string c_label_file = fastdeploy::jni::ConvertTo(env, label_file);
+ std::string c_lite_optimized_model_dir = fastdeploy::jni::ConvertTo(env, lite_optimized_model_dir);
+ auto c_cpu_num_thread = static_cast(cpu_num_thread);
+ auto c_enable_lite_fp16 = static_cast(enable_lite_fp16);
+ auto c_lite_power_mode = static_cast(lite_power_mode);
+ fastdeploy::RuntimeOption c_option;
+ c_option.UseCpu();
+ c_option.UseLiteBackend();
+ c_option.SetCpuThreadNum(c_cpu_num_thread);
+ c_option.SetLitePowerMode(c_lite_power_mode);
+ c_option.SetLiteOptimizedModelDir(c_lite_optimized_model_dir);
+ if (c_enable_lite_fp16) {
+ c_option.EnableLiteFP16();
+ }
+ // 如果您实现的是其他模型,比如PPYOLOE,请注意修改此处绑定的C++类型
+ auto c_model_ptr = new fastdeploy::vision::detection::PicoDet(
+ c_model_file, c_params_file, c_config_file, c_option);
+ // Enable record Runtime time costs.
+ if (enable_record_time_of_runtime) {
+ c_model_ptr->EnableRecordTimeOfRuntime();
+ }
+ // Load detection labels if label path is not empty.
+ if ((!fastdeploy::jni::AssetsLoaderUtils::IsDetectionLabelsLoaded()) &&
+ (!c_label_file.empty())) {
+ fastdeploy::jni::AssetsLoaderUtils::LoadDetectionLabels(c_label_file);
+ }
+ // WARN: need to release manually in Java !
+ return reinterpret_cast(c_model_ptr); // native model context
+}
+
+// 通过传入的模型指针在C++层进行预测
+JNIEXPORT jlong JNICALL
+Java_com_baidu_paddle_fastdeploy_vision_detection_PicoDet_predictNative(
+ JNIEnv *env, jclass clazz, jlong native_model_context,
+ jobject argb8888_bitmap, jboolean saved, jstring saved_image_path,
+ jfloat score_threshold, jboolean rendering) {
+ if (native_model_context == 0) {
+ return 0;
+ }
+ cv::Mat c_bgr;
+ if (!fastdeploy::jni::ARGB888Bitmap2BGR(env, argb8888_bitmap, &c_bgr)) {
+ return 0;
+ }
+ auto c_model_ptr = reinterpret_cast(
+ native_model_context);
+ auto c_result_ptr = new fastdeploy::vision::DetectionResult();
+ t = fastdeploy::jni::GetCurrentTime();
+ if (!c_model_ptr->Predict(&c_bgr, c_result_ptr)) {
+ delete c_result_ptr;
+ return 0;
+ }
+ // ...
+ return reinterpret_cast(c_result_ptr); // native result context
+}
+
+// 在C++层释放模型资源
+JNIEXPORT jboolean JNICALL
+Java_com_baidu_paddle_fastdeploy_vision_detection_PicoDet_releaseNative(
+ JNIEnv *env, jclass clazz, jlong native_model_context) {
+ if (native_model_context == 0) {
+ return JNI_FALSE;
+ }
+ auto c_model_ptr = reinterpret_cast(
+ native_model_context);
+ // ...
+ delete c_model_ptr;
+ return JNI_TRUE;
+}
+
+#ifdef __cplusplus
+}
+#endif
+```
+## 编写CMakeLists.txt及配置build.gradle
+
+
+实现好的JNI代码,需要被编译成so库,才能被Java调用,为实现该目的,需要在build.gradle中添加JNI项目支持,并编写对应的CMakeLists.txt。
+- build.gradle中配置NDK、CMake以及Android ABI
+```java
+android {
+ defaultConfig {
+ // 省略其他配置 ...
+ externalNativeBuild {
+ cmake {
+ arguments '-DANDROID_PLATFORM=android-21', '-DANDROID_STL=c++_shared', "-DANDROID_TOOLCHAIN=clang"
+ abiFilters 'armeabi-v7a', 'arm64-v8a'
+ cppFlags "-std=c++11"
+ }
+ }
+ }
+ // 省略其他配置 ...
+ externalNativeBuild {
+ cmake {
+ path file('src/main/cpp/CMakeLists.txt')
+ version '3.10.2'
+ }
+ }
+ ndkVersion '20.1.5948944'
+}
+```
+- 编写CMakeLists.txt示例
+```cmake
+cmake_minimum_required(VERSION 3.10.2)
+project("fastdeploy_jni")
+
+set(FastDeploy_DIR "${CMAKE_CURRENT_SOURCE_DIR}/../../../libs/fastdeploy-android-0.4.0-shared")
+
+find_package(FastDeploy REQUIRED)
+
+include_directories(${CMAKE_CURRENT_SOURCE_DIR})
+include_directories(${FastDeploy_INCLUDE_DIRS})
+
+add_library(
+ fastdeploy_jni
+ SHARED
+ utils_jni.cc
+ bitmap_jni.cc
+ vision/results_jni.cc
+ vision/visualize_jni.cc
+ vision/detection/picodet_jni.cc
+ vision/classification/paddleclas_model_jni.cc)
+
+find_library(log-lib log)
+
+target_link_libraries(
+ # Specifies the target library.
+ fastdeploy_jni
+ jnigraphics
+ ${FASTDEPLOY_LIBS}
+ GLESv2
+ EGL
+ ${log-lib}
+)
+```
+完整的工程示例,请参考 [android/app/src/main/cpp/CMakelists.txt](../../../examples/vision/detection/paddledetection/android/app/src/main/cpp/) 以及 [android/app/build.gradle](../../../examples/vision/detection/paddledetection/android/app/build.gradle).
+
+## 更多FastDeploy Android 使用案例
+
+
+更多FastDeploy Android 使用案例请参考以下文档:
+- [图像分类Android使用文档](../../../examples/vision/classification/paddleclas/android/README.md)
+- [目标检测Android使用文档](../../../examples/vision/detection/paddledetection/android/README.md)
diff --git a/docs/cn/faq/use_java_sdk_on_android.md b/docs/cn/faq/use_java_sdk_on_android.md
new file mode 100644
index 00000000000..832ca1909c8
--- /dev/null
+++ b/docs/cn/faq/use_java_sdk_on_android.md
@@ -0,0 +1,2 @@
+## 在 Android 中使用 FastDeploy Java SDK
+- TODO
diff --git a/docs/cn/quantize.md b/docs/cn/quantize.md
index 5411cac2995..6277c8385c0 100644
--- a/docs/cn/quantize.md
+++ b/docs/cn/quantize.md
@@ -2,7 +2,7 @@
# 量化加速
量化是一种流行的模型压缩方法,量化后的模型拥有更小的体积和更快的推理速度.
-FastDeploy基于PaddleSlim, 集成了一键模型量化的工具, 同时, FastDeploy支持部署量化后的模型, 帮助用户实现推理加速.
+FastDeploy基于PaddleSlim, 集成了一键模型量化的工具, 同时, FastDeploy支持推理部署量化后的模型, 帮助用户实现推理加速.
## FastDeploy 多个引擎和硬件支持量化模型部署
@@ -17,7 +17,7 @@ FastDeploy基于PaddleSlim, 集成了一键模型量化的工具, 同时, FastDe
## 模型量化
### 量化方法
-基于PaddleSlim, 目前FastDeploy提供的的量化方法有量化蒸馏训练和离线量化, 量化蒸馏训练通过模型训练来获得量化模型, 离线量化不需要模型训练即可完成模型的量化. FastDeploy 对两种方式产出的量化模型均能部署.
+基于PaddleSlim,目前FastDeploy提供的的量化方法有量化蒸馏训练和离线量化,量化蒸馏训练通过模型训练来获得量化模型,离线量化不需要模型训练即可完成模型的量化。 FastDeploy 对两种方式产出的量化模型均能部署。
两种方法的主要对比如下表所示:
| 量化方法 | 量化过程耗时 | 量化模型精度 | 模型体积 | 推理速度 |
@@ -25,13 +25,14 @@ FastDeploy基于PaddleSlim, 集成了一键模型量化的工具, 同时, FastDe
| 离线量化 | 无需训练,耗时短 | 比量化蒸馏训练稍低 | 两者一致 | 两者一致 |
| 量化蒸馏训练 | 需要训练,耗时稍高 | 较未量化模型有少量损失 | 两者一致 |两者一致 |
-### 用户使用FastDeploy一键模型量化工具来量化模型
-Fastdeploy基于PaddleSlim, 为用户提供了一键模型量化的工具,请参考如下文档进行模型量化.
+### 使用FastDeploy一键模型量化工具来量化模型
+Fastdeploy基于PaddleSlim, 为用户提供了一键模型量化的工具,请参考如下文档进行模型量化。
- [FastDeploy 一键模型量化](../../tools/quantization/)
-当用户获得产出的量化模型之后,即可以使用FastDeploy来部署量化模型.
+当用户获得产出的量化模型之后,即可以使用FastDeploy来部署量化模型。
-## 量化示例
+## 量化benchmark
+
目前, FastDeploy已支持的模型量化如下表所示:
### YOLO 系列
diff --git a/examples/application/js/README.md b/examples/application/js/README.md
index 4544c061a27..ced46e74129 100644
--- a/examples/application/js/README.md
+++ b/examples/application/js/README.md
@@ -33,3 +33,9 @@
|目标检测| coming soon |
|图像分割| coming soon |
|物品分类| coming soon |
+
+
+## Contributor
+
+感谢飞桨开发者专家(PPDE)陈千鹤(github: [chenqianhe](https://github.com/chenqianhe))贡献的小程序、Web demo,项目[链接](https://github.com/chenqianhe/Paddle.js)。
+
diff --git a/examples/vision/classification/paddleclas/android/README.md b/examples/vision/classification/paddleclas/android/README.md
index 5a595241daf..05164d8435a 100644
--- a/examples/vision/classification/paddleclas/android/README.md
+++ b/examples/vision/classification/paddleclas/android/README.md
@@ -1,3 +1,155 @@
-## 图像分类 Android Demo 使用文档
+## 图像分类 PaddleClas Android Demo 使用文档
-- TODO
+在 Android 上实现实时的图像分类功能,此 Demo 有很好的的易用性和开放性,如在 Demo 中跑自己训练好的模型等。
+
+## 环境准备
+
+1. 在本地环境安装好 Android Studio 工具,详细安装方法请见[Android Stuido 官网](https://developer.android.com/studio)。
+2. 准备一部 Android 手机,并开启 USB 调试模式。开启方法: `手机设置 -> 查找开发者选项 -> 打开开发者选项和 USB 调试模式`
+
+**注意**:如果您的 Android Studio 尚未配置 NDK ,请根据 Android Studio 用户指南中的[安装及配置 NDK 和 CMake ](https://developer.android.com/studio/projects/install-ndk)内容,预先配置好 NDK 。您可以选择最新的 NDK 版本,或者使用 FastDeploy Android 预测库版本一样的 NDK
+
+## 部署步骤
+
+1. 目标检测 PaddleClas Demo 位于 `fastdeploy/examples/vision/classification/paddleclas/android` 目录
+2. 用 Android Studio 打开 paddleclas/android 工程
+3. 手机连接电脑,打开 USB 调试和文件传输模式,并在 Android Studio 上连接自己的手机设备(手机需要开启允许从 USB 安装软件权限)
+
+
+ +
+
+
+> **注意:**
+>> 如果您在导入项目、编译或者运行过程中遇到 NDK 配置错误的提示,请打开 ` File > Project Structure > SDK Location`,修改 `Andriod NDK location` 为您本机配置的 NDK 所在路径。本工程默认使用的NDK版本为20.
+>> 如果您是通过 Andriod Studio 的 SDK Tools 下载的 NDK (见本章节"环境准备"),可以直接点击下拉框选择默认路径。
+>> 还有一种 NDK 配置方法,你可以在 `paddleclas/android/local.properties` 文件中手动完成 NDK 路径配置,如下图所示
+>> 如果以上步骤仍旧无法解决 NDK 配置错误,请尝试根据 Andriod Studio 官方文档中的[更新 Android Gradle 插件](https://developer.android.com/studio/releases/gradle-plugin?hl=zh-cn#updating-plugin)章节,尝试更新Android Gradle plugin版本。
+
+4. 点击 Run 按钮,自动编译 APP 并安装到手机。(该过程会自动下载预编译的 FastDeploy Android 库,需要联网)
+成功后效果如下,图一:APP 安装到手机;图二: APP 打开后的效果,会自动识别图片中的物体并标记;图三:APP设置选项,点击右上角的设置图片,可以设置不同选项进行体验。
+
+ | APP 图标 | APP 效果 | APP设置项
+ | --- | --- | --- |
+ |  |  | 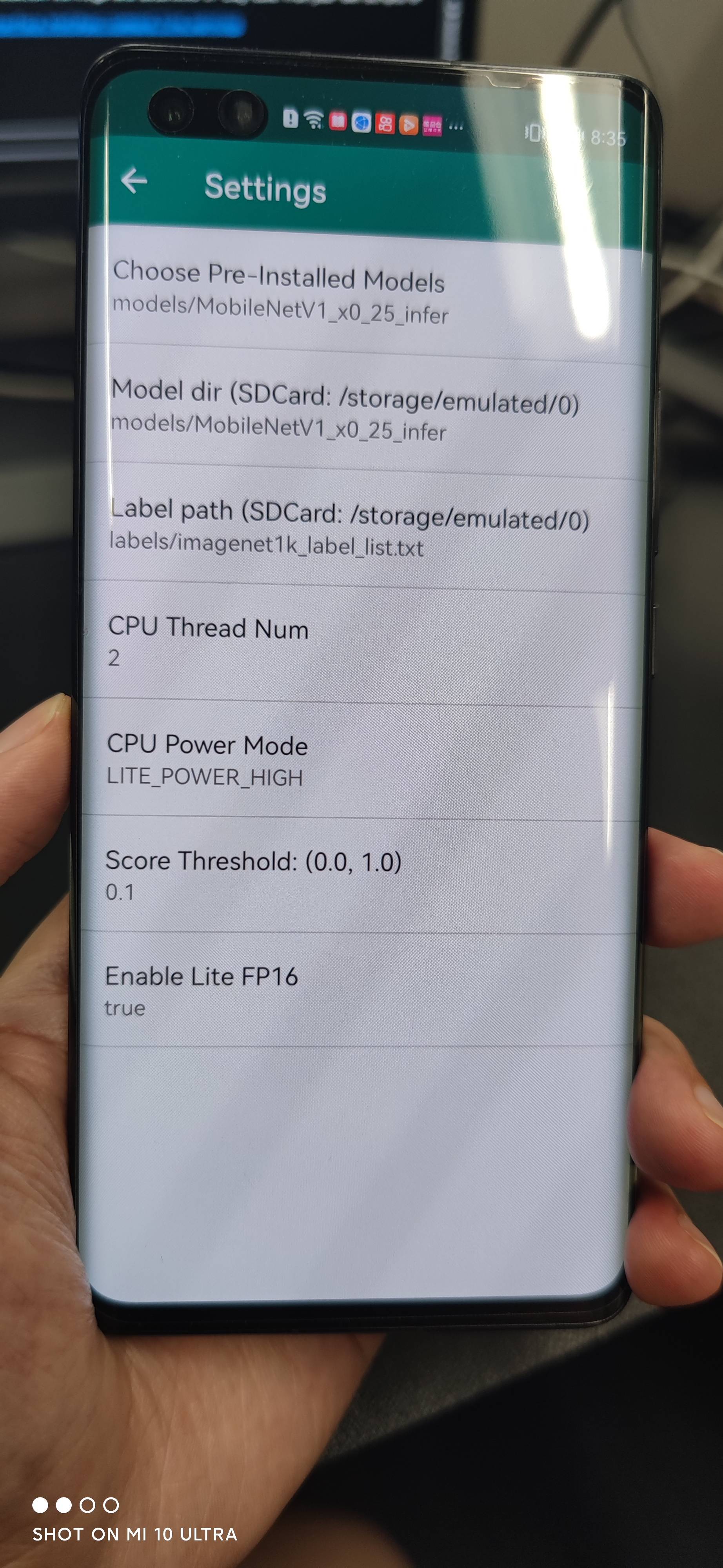 |
+
+## PaddleClasModel Java API 说明
+- 模型初始化 API: 模型初始化API包含两种方式,方式一是通过构造函数直接初始化;方式二是,通过调用init函数,在合适的程序节点进行初始化。PaddleClasModel初始化参数说明如下:
+ - modelFile: String, paddle格式的模型文件路径,如 model.pdmodel
+ - paramFile: String, paddle格式的参数文件路径,如 model.pdiparams
+ - configFile: String, 模型推理的预处理配置文件,如 infer_cfg.yml
+ - labelFile: String, 可选参数,表示label标签文件所在路径,用于可视化,如 imagenet1k_label_list.txt,每一行包含一个label
+ - option: RuntimeOption,可选参数,模型初始化option。如果不传入该参数则会使用默认的运行时选项。
+
+```java
+// 构造函数: constructor w/o label file
+public PaddleClasModel(); // 空构造函数,之后可以调用init初始化
+public PaddleClasModel(String modelFile, String paramsFile, String configFile);
+public PaddleClasModel(String modelFile, String paramsFile, String configFile, String labelFile);
+public PaddleClasModel(String modelFile, String paramsFile, String configFile, RuntimeOption option);
+public PaddleClasModel(String modelFile, String paramsFile, String configFile, String labelFile, RuntimeOption option);
+// 手动调用init初始化: call init manually w/o label file
+public boolean init(String modelFile, String paramsFile, String configFile, RuntimeOption option);
+public boolean init(String modelFile, String paramsFile, String configFile, String labelFile, RuntimeOption option);
+```
+- 模型预测 API:模型预测API包含直接预测的API以及带可视化功能的API。直接预测是指,不保存图片以及不渲染结果到Bitmap上,仅预测推理结果。预测并且可视化是指,预测结果以及可视化,并将可视化后的图片保存到指定的途径,以及将可视化结果渲染在Bitmap(目前支持ARGB8888格式的Bitmap), 后续可将该Bitmap在camera中进行显示。
+```java
+// 直接预测:不保存图片以及不渲染结果到Bitmap上
+public ClassifyResult predict(Bitmap ARGB8888Bitmap);
+// 预测并且可视化:预测结果以及可视化,并将可视化后的图片保存到指定的途径,以及将可视化结果渲染在Bitmap上
+public ClassifyResult predict(Bitmap ARGB8888Bitmap, String savedImagePath, float scoreThreshold)
+```
+- 模型资源释放 API:调用 release() API 可以释放模型资源,返回true表示释放成功,false表示失败;调用 initialized() 可以判断模型是否初始化成功,true表示初始化成功,false表示失败。
+```java
+public boolean release(); // 释放native资源
+public boolean initialized(); // 检查是否初始化成功
+```
+- RuntimeOption设置说明
+```java
+public void enableLiteFp16(); // 开启fp16精度推理
+public void disableLiteFP16(); // 关闭fp16精度推理
+public void setCpuThreadNum(int threadNum); // 设置线程数
+public void setLitePowerMode(LitePowerMode mode); // 设置能耗模式
+public void setLitePowerMode(String modeStr); // 通过字符串形式设置能耗模式
+public void enableRecordTimeOfRuntime(); // 是否打印模型运行耗时
+```
+
+- 模型结果ClassifyResult说明
+```java
+public float[] mScores; // [n] 得分
+public int[] mLabelIds; // [n] 分类ID
+public boolean initialized(); // 检测结果是否有效
+```
+
+- 模型调用示例1:使用构造函数以及默认的RuntimeOption
+```java
+import java.nio.ByteBuffer;
+import android.graphics.Bitmap;
+import android.opengl.GLES20;
+
+import com.baidu.paddle.fastdeploy.vision.ClassifyResult;
+import com.baidu.paddle.fastdeploy.vision.classification.PaddleClasModel;
+
+// 初始化模型
+PaddleClasModel model = new PaddleClasModel("MobileNetV1_x0_25_infer/inference.pdmodel",
+ "MobileNetV1_x0_25_infer/inference.pdiparams",
+ "MobileNetV1_x0_25_infer/inference_cls.yml");
+
+// 读取图片: 以下仅为读取Bitmap的伪代码
+ByteBuffer pixelBuffer = ByteBuffer.allocate(width * height * 4);
+GLES20.glReadPixels(0, 0, width, height, GLES20.GL_RGBA, GLES20.GL_UNSIGNED_BYTE, pixelBuffer);
+Bitmap ARGB8888ImageBitmap = Bitmap.createBitmap(width, height, Bitmap.Config.ARGB_8888);
+ARGB8888ImageBitmap.copyPixelsFromBuffer(pixelBuffer);
+
+// 模型推理
+ClassifyResult result = model.predict(ARGB8888ImageBitmap);
+
+// 释放模型资源
+model.release();
+```
+
+- 模型调用示例2: 在合适的程序节点,手动调用init,并自定义RuntimeOption
+```java
+// import 同上 ...
+import com.baidu.paddle.fastdeploy.RuntimeOption;
+import com.baidu.paddle.fastdeploy.LitePowerMode;
+import com.baidu.paddle.fastdeploy.vision.ClassifyResult;
+import com.baidu.paddle.fastdeploy.vision.classification.PaddleClasModel;
+// 新建空模型
+PaddleClasModel model = new PaddleClasModel();
+// 模型路径
+String modelFile = "MobileNetV1_x0_25_infer/inference.pdmodel";
+String paramFile = "MobileNetV1_x0_25_infer/inference.pdiparams";
+String configFile = "MobileNetV1_x0_25_infer/inference_cls.yml";
+// 指定RuntimeOption
+RuntimeOption option = new RuntimeOption();
+option.setCpuThreadNum(2);
+option.setLitePowerMode(LitePowerMode.LITE_POWER_HIGH);
+option.enableRecordTimeOfRuntime();
+option.enableLiteFp16();
+// 使用init函数初始化
+model.init(modelFile, paramFile, configFile, option);
+// Bitmap读取、模型预测、资源释放 同上 ...
+```
+更详细的用法请参考 [MainActivity](./app/src/main/java/com/baidu/paddle/fastdeploy/examples/MainActivity.java#L207) 中的用法
+
+## 替换 FastDeploy 预测库和模型
+替换FastDeploy预测库和模型的步骤非常简单。预测库所在的位置为 `app/libs/fastdeploy-android-xxx-shared`,其中 `xxx` 表示当前您使用的预测库版本号。模型所在的位置为,`app/src/main/assets/models/MobileNetV1_x0_25_infer`。
+- 替换FastDeploy预测库的步骤:
+ - 下载或编译最新的FastDeploy Android预测库,解压缩后放在 `app/libs` 目录下;
+ - 修改 `app/src/main/cpp/CMakeLists.txt` 中的预测库路径,指向您下载或编译的预测库路径。如:
+```cmake
+set(FastDeploy_DIR "${CMAKE_CURRENT_SOURCE_DIR}/../../../libs/fastdeploy-android-xxx-shared")
+```
+- 替换PaddleClas模型的步骤:
+ - 将您的PaddleClas分类模型放在 `app/src/main/assets/models` 目录下;
+ - 修改 `app/src/main/res/values/strings.xml` 中模型路径的默认值,如:
+```xml
+
+models/MobileNetV1_x0_25_infer
+labels/imagenet1k_label_list.txt
+```
+
+## 如何通过 JNI 在 Native 层接入 FastDeploy C++ API ?
+如果您对如何通过JNI来接入FastDeploy C++ API感兴趣,可以参考以下内容:
+- [app/src/main/cpp 代码实现](./app/src/main/cpp/)
+- [在 Android 中通过 JNI 使用 FastDeploy C++ SDK](../../../../../docs/cn/faq/use_cpp_sdk_on_android.md)
diff --git a/examples/vision/classification/paddleclas/android/app/src/main/java/com/baidu/paddle/fastdeploy/vision/classification/PaddleClasModel.java b/examples/vision/classification/paddleclas/android/app/src/main/java/com/baidu/paddle/fastdeploy/vision/classification/PaddleClasModel.java
index f0524604e05..b4a56e30955 100644
--- a/examples/vision/classification/paddleclas/android/app/src/main/java/com/baidu/paddle/fastdeploy/vision/classification/PaddleClasModel.java
+++ b/examples/vision/classification/paddleclas/android/app/src/main/java/com/baidu/paddle/fastdeploy/vision/classification/PaddleClasModel.java
@@ -14,6 +14,20 @@ public PaddleClasModel() {
mInitialized = false;
}
+ // Constructor with default runtime option
+ public PaddleClasModel(String modelFile,
+ String paramsFile,
+ String configFile) {
+ init_(modelFile, paramsFile, configFile, "", new RuntimeOption());
+ }
+
+ public PaddleClasModel(String modelFile,
+ String paramsFile,
+ String configFile,
+ String labelFile) {
+ init_(modelFile, paramsFile, configFile, labelFile, new RuntimeOption());
+ }
+
// Constructor without label file
public PaddleClasModel(String modelFile,
String paramsFile,
diff --git a/examples/vision/classification/paddleclas/android/app/src/main/java/com/baidu/paddle/fastdeploy/vision/detection/PicoDet.java b/examples/vision/classification/paddleclas/android/app/src/main/java/com/baidu/paddle/fastdeploy/vision/detection/PicoDet.java
index bbd52eecee7..9729eeb8a43 100644
--- a/examples/vision/classification/paddleclas/android/app/src/main/java/com/baidu/paddle/fastdeploy/vision/detection/PicoDet.java
+++ b/examples/vision/classification/paddleclas/android/app/src/main/java/com/baidu/paddle/fastdeploy/vision/detection/PicoDet.java
@@ -14,6 +14,20 @@ public PicoDet() {
mInitialized = false;
}
+ // Constructor with default runtime option
+ public PicoDet(String modelFile,
+ String paramsFile,
+ String configFile) {
+ init_(modelFile, paramsFile, configFile, "", new RuntimeOption());
+ }
+
+ public PicoDet(String modelFile,
+ String paramsFile,
+ String configFile,
+ String labelFile) {
+ init_(modelFile, paramsFile, configFile, labelFile, new RuntimeOption());
+ }
+
// Constructor without label file
public PicoDet(String modelFile,
String paramsFile,
diff --git a/examples/vision/detection/paddledetection/android/README.md b/examples/vision/detection/paddledetection/android/README.md
index 6a82dd18c1f..4a57f98f953 100644
--- a/examples/vision/detection/paddledetection/android/README.md
+++ b/examples/vision/detection/paddledetection/android/README.md
@@ -1,3 +1,156 @@
-## 目标检测 Android Demo 使用文档
+# 目标检测 PicoDet Android Demo 使用文档
-- TODO
+在 Android 上实现实时的目标检测功能,此 Demo 有很好的的易用性和开放性,如在 Demo 中跑自己训练好的模型等。
+
+## 环境准备
+
+1. 在本地环境安装好 Android Studio 工具,详细安装方法请见[Android Stuido 官网](https://developer.android.com/studio)。
+2. 准备一部 Android 手机,并开启 USB 调试模式。开启方法: `手机设置 -> 查找开发者选项 -> 打开开发者选项和 USB 调试模式`
+
+**注意**:如果您的 Android Studio 尚未配置 NDK ,请根据 Android Studio 用户指南中的[安装及配置 NDK 和 CMake ](https://developer.android.com/studio/projects/install-ndk)内容,预先配置好 NDK 。您可以选择最新的 NDK 版本,或者使用 FastDeploy Android 预测库版本一样的 NDK
+
+## 部署步骤
+
+1. 目标检测 PicoDet Demo 位于 `fastdeploy/examples/vision/detection/paddledetection/android` 目录
+2. 用 Android Studio 打开 paddledetection/android 工程
+3. 手机连接电脑,打开 USB 调试和文件传输模式,并在 Android Studio 上连接自己的手机设备(手机需要开启允许从 USB 安装软件权限)
+
+
+ +
+
+
+> **注意:**
+>> 如果您在导入项目、编译或者运行过程中遇到 NDK 配置错误的提示,请打开 ` File > Project Structure > SDK Location`,修改 `Andriod NDK location` 为您本机配置的 NDK 所在路径。本工程默认使用的NDK版本为20.
+>> 如果您是通过 Andriod Studio 的 SDK Tools 下载的 NDK (见本章节"环境准备"),可以直接点击下拉框选择默认路径。
+>> 还有一种 NDK 配置方法,你可以在 `paddledetection/android/local.properties` 文件中手动完成 NDK 路径配置,如下图所示
+>> 如果以上步骤仍旧无法解决 NDK 配置错误,请尝试根据 Andriod Studio 官方文档中的[更新 Android Gradle 插件](https://developer.android.com/studio/releases/gradle-plugin?hl=zh-cn#updating-plugin)章节,尝试更新Android Gradle plugin版本。
+
+4. 点击 Run 按钮,自动编译 APP 并安装到手机。(该过程会自动下载预编译的 FastDeploy Android 库,需要联网)
+成功后效果如下,图一:APP 安装到手机;图二: APP 打开后的效果,会自动识别图片中的物体并标记;图三:APP设置选项,点击右上角的设置图片,可以设置不同选项进行体验。
+
+ | APP 图标 | APP 效果 | APP设置项
+ | --- | --- | --- |
+ |  |  |  |
+
+## PicoDet Java API 说明
+- 模型初始化 API: 模型初始化API包含两种方式,方式一是通过构造函数直接初始化;方式二是,通过调用init函数,在合适的程序节点进行初始化。PicoDet初始化参数说明如下:
+ - modelFile: String, paddle格式的模型文件路径,如 model.pdmodel
+ - paramFile: String, paddle格式的参数文件路径,如 model.pdiparams
+ - configFile: String, 模型推理的预处理配置文件,如 infer_cfg.yml
+ - labelFile: String, 可选参数,表示label标签文件所在路径,用于可视化,如 coco_label_list.txt,每一行包含一个label
+ - option: RuntimeOption,可选参数,模型初始化option。如果不传入该参数则会使用默认的运行时选项。
+
+```java
+// 构造函数: constructor w/o label file
+public PicoDet(); // 空构造函数,之后可以调用init初始化
+public PicoDet(String modelFile, String paramsFile, String configFile);
+public PicoDet(String modelFile, String paramsFile, String configFile, String labelFile);
+public PicoDet(String modelFile, String paramsFile, String configFile, RuntimeOption option);
+public PicoDet(String modelFile, String paramsFile, String configFile, String labelFile, RuntimeOption option);
+// 手动调用init初始化: call init manually w/o label file
+public boolean init(String modelFile, String paramsFile, String configFile, RuntimeOption option);
+public boolean init(String modelFile, String paramsFile, String configFile, String labelFile, RuntimeOption option);
+```
+- 模型预测 API:模型预测API包含直接预测的API以及带可视化功能的API。直接预测是指,不保存图片以及不渲染结果到Bitmap上,仅预测推理结果。预测并且可视化是指,预测结果以及可视化,并将可视化后的图片保存到指定的途径,以及将可视化结果渲染在Bitmap(目前支持ARGB8888格式的Bitmap), 后续可将该Bitmap在camera中进行显示。
+```java
+// 直接预测:不保存图片以及不渲染结果到Bitmap上
+public DetectionResult predict(Bitmap ARGB8888Bitmap);
+// 预测并且可视化:预测结果以及可视化,并将可视化后的图片保存到指定的途径,以及将可视化结果渲染在Bitmap上
+public DetectionResult predict(Bitmap ARGB8888Bitmap, String savedImagePath, float scoreThreshold)
+```
+- 模型资源释放 API:调用 release() API 可以释放模型资源,返回true表示释放成功,false表示失败;调用 initialized() 可以判断模型是否初始化成功,true表示初始化成功,false表示失败。
+```java
+public boolean release(); // 释放native资源
+public boolean initialized(); // 检查是否初始化成功
+```
+- RuntimeOption设置说明
+```java
+public void enableLiteFp16(); // 开启fp16精度推理
+public void disableLiteFP16(); // 关闭fp16精度推理
+public void setCpuThreadNum(int threadNum); // 设置线程数
+public void setLitePowerMode(LitePowerMode mode); // 设置能耗模式
+public void setLitePowerMode(String modeStr); // 通过字符串形式设置能耗模式
+public void enableRecordTimeOfRuntime(); // 是否打印模型运行耗时
+```
+
+- 模型结果DetectionResult说明
+```java
+public float[][] mBoxes; // [n,4] 检测框 (x1,y1,x2,y2)
+public float[] mScores; // [n] 得分
+public int[] mLabelIds; // [n] 分类ID
+public boolean initialized(); // 检测结果是否有效
+```
+
+- 模型调用示例1:使用构造函数以及默认的RuntimeOption
+```java
+import java.nio.ByteBuffer;
+import android.graphics.Bitmap;
+import android.opengl.GLES20;
+
+import com.baidu.paddle.fastdeploy.vision.DetectionResult;
+import com.baidu.paddle.fastdeploy.vision.detection.PicoDet;
+
+// 初始化模型
+PicoDet model = new PicoDet("picodet_s_320_coco_lcnet/model.pdmodel",
+ "picodet_s_320_coco_lcnet/model.pdiparams",
+ "picodet_s_320_coco_lcnet/infer_cfg.yml");
+
+// 读取图片: 以下仅为读取Bitmap的伪代码
+ByteBuffer pixelBuffer = ByteBuffer.allocate(width * height * 4);
+GLES20.glReadPixels(0, 0, width, height, GLES20.GL_RGBA, GLES20.GL_UNSIGNED_BYTE, pixelBuffer);
+Bitmap ARGB8888ImageBitmap = Bitmap.createBitmap(width, height, Bitmap.Config.ARGB_8888);
+ARGB8888ImageBitmap.copyPixelsFromBuffer(pixelBuffer);
+
+// 模型推理
+DetectionResult result = model.predict(ARGB8888ImageBitmap);
+
+// 释放模型资源
+model.release();
+```
+
+- 模型调用示例2: 在合适的程序节点,手动调用init,并自定义RuntimeOption
+```java
+// import 同上 ...
+import com.baidu.paddle.fastdeploy.RuntimeOption;
+import com.baidu.paddle.fastdeploy.LitePowerMode;
+import com.baidu.paddle.fastdeploy.vision.DetectionResult;
+import com.baidu.paddle.fastdeploy.vision.detection.PicoDet;
+// 新建空模型
+PicoDet model = new PicoDet();
+// 模型路径
+String modelFile = "picodet_s_320_coco_lcnet/model.pdmodel";
+String paramFile = "picodet_s_320_coco_lcnet/model.pdiparams";
+String configFile = "picodet_s_320_coco_lcnet/infer_cfg.yml";
+// 指定RuntimeOption
+RuntimeOption option = new RuntimeOption();
+option.setCpuThreadNum(2);
+option.setLitePowerMode(LitePowerMode.LITE_POWER_HIGH);
+option.enableRecordTimeOfRuntime();
+option.enableLiteFp16();
+// 使用init函数初始化
+model.init(modelFile, paramFile, configFile, option);
+// Bitmap读取、模型预测、资源释放 同上 ...
+```
+更详细的用法请参考 [MainActivity](./app/src/main/java/com/baidu/paddle/fastdeploy/examples/MainActivity.java#L207) 中的用法
+
+## 替换 FastDeploy 预测库和模型
+替换FastDeploy预测库和模型的步骤非常简单。预测库所在的位置为 `app/libs/fastdeploy-android-xxx-shared`,其中 `xxx` 表示当前您使用的预测库版本号。模型所在的位置为,`app/src/main/assets/models/picodet_s_320_coco_lcnet`。
+- 替换FastDeploy预测库的步骤:
+ - 下载或编译最新的FastDeploy Android预测库,解压缩后放在 `app/libs` 目录下;
+ - 修改 `app/src/main/cpp/CMakeLists.txt` 中的预测库路径,指向您下载或编译的预测库路径。如:
+```cmake
+set(FastDeploy_DIR "${CMAKE_CURRENT_SOURCE_DIR}/../../../libs/fastdeploy-android-xxx-shared")
+```
+- 替换PicoDet模型的步骤:
+ - 将您的PicoDet模型放在 `app/src/main/assets/models` 目录下;
+ - 修改 `app/src/main/res/values/strings.xml` 中模型路径的默认值,如:
+```xml
+
+models/picodet_s_320_coco_lcnet
+labels/coco_label_list.txt
+```
+
+## 如何通过 JNI 在 Native 层接入 FastDeploy C++ API ?
+如果您对如何通过JNI来接入FastDeploy C++ API感兴趣,可以参考以下内容:
+- [app/src/main/cpp 代码实现](./app/src/main/cpp/)
+- [在 Android 中使用 FastDeploy C++ SDK](../../../../../docs/cn/faq/use_cpp_sdk_on_android.md)
diff --git a/examples/vision/detection/paddledetection/android/app/src/main/java/com/baidu/paddle/fastdeploy/vision/classification/PaddleClasModel.java b/examples/vision/detection/paddledetection/android/app/src/main/java/com/baidu/paddle/fastdeploy/vision/classification/PaddleClasModel.java
index f0524604e05..b4a56e30955 100644
--- a/examples/vision/detection/paddledetection/android/app/src/main/java/com/baidu/paddle/fastdeploy/vision/classification/PaddleClasModel.java
+++ b/examples/vision/detection/paddledetection/android/app/src/main/java/com/baidu/paddle/fastdeploy/vision/classification/PaddleClasModel.java
@@ -14,6 +14,20 @@ public PaddleClasModel() {
mInitialized = false;
}
+ // Constructor with default runtime option
+ public PaddleClasModel(String modelFile,
+ String paramsFile,
+ String configFile) {
+ init_(modelFile, paramsFile, configFile, "", new RuntimeOption());
+ }
+
+ public PaddleClasModel(String modelFile,
+ String paramsFile,
+ String configFile,
+ String labelFile) {
+ init_(modelFile, paramsFile, configFile, labelFile, new RuntimeOption());
+ }
+
// Constructor without label file
public PaddleClasModel(String modelFile,
String paramsFile,
diff --git a/examples/vision/detection/paddledetection/android/app/src/main/java/com/baidu/paddle/fastdeploy/vision/detection/PicoDet.java b/examples/vision/detection/paddledetection/android/app/src/main/java/com/baidu/paddle/fastdeploy/vision/detection/PicoDet.java
index bbd52eecee7..9729eeb8a43 100644
--- a/examples/vision/detection/paddledetection/android/app/src/main/java/com/baidu/paddle/fastdeploy/vision/detection/PicoDet.java
+++ b/examples/vision/detection/paddledetection/android/app/src/main/java/com/baidu/paddle/fastdeploy/vision/detection/PicoDet.java
@@ -14,6 +14,20 @@ public PicoDet() {
mInitialized = false;
}
+ // Constructor with default runtime option
+ public PicoDet(String modelFile,
+ String paramsFile,
+ String configFile) {
+ init_(modelFile, paramsFile, configFile, "", new RuntimeOption());
+ }
+
+ public PicoDet(String modelFile,
+ String paramsFile,
+ String configFile,
+ String labelFile) {
+ init_(modelFile, paramsFile, configFile, labelFile, new RuntimeOption());
+ }
+
// Constructor without label file
public PicoDet(String modelFile,
String paramsFile,
diff --git a/fastdeploy/backends/paddle/paddle_backend.cc b/fastdeploy/backends/paddle/paddle_backend.cc
index 674a3795481..25951dae550 100644
--- a/fastdeploy/backends/paddle/paddle_backend.cc
+++ b/fastdeploy/backends/paddle/paddle_backend.cc
@@ -19,6 +19,7 @@
namespace fastdeploy {
void PaddleBackend::BuildOption(const PaddleBackendOption& option) {
+ option_ = option;
if (option.use_gpu) {
config_.EnableUseGpu(option.gpu_mem_init_size, option.gpu_id);
if (option.enable_trt) {
@@ -190,6 +191,7 @@ bool PaddleBackend::Infer(std::vector& inputs,
outputs->resize(outputs_desc_.size());
for (size_t i = 0; i < outputs_desc_.size(); ++i) {
auto handle = predictor_->GetOutputHandle(outputs_desc_[i].name);
+ (*outputs)[i].is_pinned_memory = option_.enable_pinned_memory;
CopyTensorToCpu(handle, &((*outputs)[i]));
}
return true;
diff --git a/fastdeploy/backends/paddle/paddle_backend.h b/fastdeploy/backends/paddle/paddle_backend.h
index 78b939feaea..1d4f53db3d8 100755
--- a/fastdeploy/backends/paddle/paddle_backend.h
+++ b/fastdeploy/backends/paddle/paddle_backend.h
@@ -53,6 +53,7 @@ struct PaddleBackendOption {
int gpu_mem_init_size = 100;
// gpu device id
int gpu_id = 0;
+ bool enable_pinned_memory = false;
std::vector delete_pass_names = {};
};
@@ -105,6 +106,7 @@ class PaddleBackend : public BaseBackend {
std::map>* opt_shape) const;
void SetTRTDynamicShapeToConfig(const PaddleBackendOption& option);
#endif
+ PaddleBackendOption option_;
paddle_infer::Config config_;
std::shared_ptr predictor_;
std::vector inputs_desc_;
diff --git a/fastdeploy/backends/paddle/util.cc b/fastdeploy/backends/paddle/util.cc
index 005f9966b1a..d8cc1dbb936 100644
--- a/fastdeploy/backends/paddle/util.cc
+++ b/fastdeploy/backends/paddle/util.cc
@@ -67,7 +67,7 @@ void CopyTensorToCpu(std::unique_ptr& tensor,
std::vector shape;
auto tmp_shape = tensor->shape();
shape.assign(tmp_shape.begin(), tmp_shape.end());
- fd_tensor->Allocate(shape, fd_dtype, tensor->name());
+ fd_tensor->Resize(shape, fd_dtype, tensor->name());
if (fd_tensor->dtype == FDDataType::FP32) {
tensor->CopyToCpu(static_cast(fd_tensor->MutableData()));
return;
diff --git a/fastdeploy/backends/tensorrt/trt_backend.cc b/fastdeploy/backends/tensorrt/trt_backend.cc
index 395215db030..363a9d1ce42 100644
--- a/fastdeploy/backends/tensorrt/trt_backend.cc
+++ b/fastdeploy/backends/tensorrt/trt_backend.cc
@@ -306,17 +306,21 @@ bool TrtBackend::Infer(std::vector& inputs,
SetInputs(inputs);
AllocateOutputsBuffer(outputs);
+
if (!context_->enqueueV2(bindings_.data(), stream_, nullptr)) {
FDERROR << "Failed to Infer with TensorRT." << std::endl;
return false;
}
for (size_t i = 0; i < outputs->size(); ++i) {
FDASSERT(cudaMemcpyAsync((*outputs)[i].Data(),
- outputs_buffer_[(*outputs)[i].name].data(),
+ outputs_device_buffer_[(*outputs)[i].name].data(),
(*outputs)[i].Nbytes(), cudaMemcpyDeviceToHost,
stream_) == 0,
"[ERROR] Error occurs while copy memory from GPU to CPU.");
}
+ FDASSERT(cudaStreamSynchronize(stream_) == cudaSuccess,
+ "[ERROR] Error occurs while sync cuda stream.");
+
return true;
}
@@ -332,10 +336,10 @@ void TrtBackend::GetInputOutputInfo() {
auto dtype = engine_->getBindingDataType(i);
if (engine_->bindingIsInput(i)) {
inputs_desc_.emplace_back(TrtValueInfo{name, shape, dtype});
- inputs_buffer_[name] = FDDeviceBuffer(dtype);
+ inputs_device_buffer_[name] = FDDeviceBuffer(dtype);
} else {
outputs_desc_.emplace_back(TrtValueInfo{name, shape, dtype});
- outputs_buffer_[name] = FDDeviceBuffer(dtype);
+ outputs_device_buffer_[name] = FDDeviceBuffer(dtype);
}
}
bindings_.resize(num_binds);
@@ -357,30 +361,31 @@ void TrtBackend::SetInputs(const std::vector& inputs) {
"please use INT32 input");
} else {
// no copy
- inputs_buffer_[item.name].SetExternalData(dims, item.Data());
+ inputs_device_buffer_[item.name].SetExternalData(dims, item.Data());
}
} else {
// Allocate input buffer memory
- inputs_buffer_[item.name].resize(dims);
+ inputs_device_buffer_[item.name].resize(dims);
// copy from cpu to gpu
if (item.dtype == FDDataType::INT64) {
int64_t* data = static_cast(const_cast(item.Data()));
std::vector casted_data(data, data + item.Numel());
- FDASSERT(cudaMemcpyAsync(inputs_buffer_[item.name].data(),
+ FDASSERT(cudaMemcpyAsync(inputs_device_buffer_[item.name].data(),
static_cast(casted_data.data()),
item.Nbytes() / 2, cudaMemcpyHostToDevice,
stream_) == 0,
"Error occurs while copy memory from CPU to GPU.");
} else {
- FDASSERT(cudaMemcpyAsync(inputs_buffer_[item.name].data(), item.Data(),
+ FDASSERT(cudaMemcpyAsync(inputs_device_buffer_[item.name].data(),
+ item.Data(),
item.Nbytes(), cudaMemcpyHostToDevice,
stream_) == 0,
"Error occurs while copy memory from CPU to GPU.");
}
}
// binding input buffer
- bindings_[idx] = inputs_buffer_[item.name].data();
+ bindings_[idx] = inputs_device_buffer_[item.name].data();
}
}
@@ -399,15 +404,19 @@ void TrtBackend::AllocateOutputsBuffer(std::vector* outputs) {
"Cannot find output: %s of tensorrt network from the original model.",
outputs_desc_[i].name.c_str());
auto ori_idx = iter->second;
+
// set user's outputs info
std::vector shape(output_dims.d,
output_dims.d + output_dims.nbDims);
+ (*outputs)[ori_idx].is_pinned_memory = option_.enable_pinned_memory;
(*outputs)[ori_idx].Resize(shape, GetFDDataType(outputs_desc_[i].dtype),
outputs_desc_[i].name);
+
// Allocate output buffer memory
- outputs_buffer_[outputs_desc_[i].name].resize(output_dims);
+ outputs_device_buffer_[outputs_desc_[i].name].resize(output_dims);
+
// binding output buffer
- bindings_[idx] = outputs_buffer_[outputs_desc_[i].name].data();
+ bindings_[idx] = outputs_device_buffer_[outputs_desc_[i].name].data();
}
}
diff --git a/fastdeploy/backends/tensorrt/trt_backend.h b/fastdeploy/backends/tensorrt/trt_backend.h
index ad3ace6a438..09f18b2dff7 100755
--- a/fastdeploy/backends/tensorrt/trt_backend.h
+++ b/fastdeploy/backends/tensorrt/trt_backend.h
@@ -70,6 +70,7 @@ struct TrtBackendOption {
std::map> min_shape;
std::map> opt_shape;
std::string serialize_file = "";
+ bool enable_pinned_memory = false;
// inside parameter, maybe remove next version
bool remove_multiclass_nms_ = false;
@@ -118,8 +119,8 @@ class TrtBackend : public BaseBackend {
std::vector bindings_;
std::vector inputs_desc_;
std::vector outputs_desc_;
- std::map inputs_buffer_;
- std::map outputs_buffer_;
+ std::map inputs_device_buffer_;
+ std::map outputs_device_buffer_;
std::string calibration_str_;
diff --git a/fastdeploy/backends/tensorrt/utils.h b/fastdeploy/backends/tensorrt/utils.h
index f7623052607..7f2e7344bad 100644
--- a/fastdeploy/backends/tensorrt/utils.h
+++ b/fastdeploy/backends/tensorrt/utils.h
@@ -206,6 +206,8 @@ class FDGenericBuffer {
};
using FDDeviceBuffer = FDGenericBuffer;
+using FDDeviceHostBuffer = FDGenericBuffer;
class FDTrtLogger : public nvinfer1::ILogger {
public:
diff --git a/fastdeploy/core/allocate.cc b/fastdeploy/core/allocate.cc
index 285642d5ce3..e71cd34434a 100644
--- a/fastdeploy/core/allocate.cc
+++ b/fastdeploy/core/allocate.cc
@@ -34,6 +34,12 @@ bool FDDeviceAllocator::operator()(void** ptr, size_t size) const {
void FDDeviceFree::operator()(void* ptr) const { cudaFree(ptr); }
+bool FDDeviceHostAllocator::operator()(void** ptr, size_t size) const {
+ return cudaMallocHost(ptr, size) == cudaSuccess;
+}
+
+void FDDeviceHostFree::operator()(void* ptr) const { cudaFreeHost(ptr); }
+
#endif
} // namespace fastdeploy
diff --git a/fastdeploy/core/allocate.h b/fastdeploy/core/allocate.h
index c48bb7cee3c..1e88787f4d6 100644
--- a/fastdeploy/core/allocate.h
+++ b/fastdeploy/core/allocate.h
@@ -45,6 +45,16 @@ class FASTDEPLOY_DECL FDDeviceFree {
void operator()(void* ptr) const;
};
+class FASTDEPLOY_DECL FDDeviceHostAllocator {
+ public:
+ bool operator()(void** ptr, size_t size) const;
+};
+
+class FASTDEPLOY_DECL FDDeviceHostFree {
+ public:
+ void operator()(void* ptr) const;
+};
+
#endif
} // namespace fastdeploy
diff --git a/fastdeploy/core/fd_tensor.cc b/fastdeploy/core/fd_tensor.cc
index 1161d2b0e2d..e98a81e1b78 100644
--- a/fastdeploy/core/fd_tensor.cc
+++ b/fastdeploy/core/fd_tensor.cc
@@ -207,9 +207,27 @@ bool FDTensor::ReallocFn(size_t nbytes) {
"-DWITH_GPU=ON,"
"so this is an unexpected problem happend.");
#endif
+ } else {
+ if (is_pinned_memory) {
+#ifdef WITH_GPU
+ size_t original_nbytes = Nbytes();
+ if (nbytes > original_nbytes) {
+ if (buffer_ != nullptr) {
+ FDDeviceHostFree()(buffer_);
+ }
+ FDDeviceHostAllocator()(&buffer_, nbytes);
+ }
+ return buffer_ != nullptr;
+#else
+ FDASSERT(false,
+ "The FastDeploy FDTensor allocator didn't compile under "
+ "-DWITH_GPU=ON,"
+ "so this is an unexpected problem happend.");
+#endif
+ }
+ buffer_ = realloc(buffer_, nbytes);
+ return buffer_ != nullptr;
}
- buffer_ = realloc(buffer_, nbytes);
- return buffer_ != nullptr;
}
void FDTensor::FreeFn() {
@@ -220,7 +238,13 @@ void FDTensor::FreeFn() {
FDDeviceFree()(buffer_);
#endif
} else {
- FDHostFree()(buffer_);
+ if (is_pinned_memory) {
+#ifdef WITH_GPU
+ FDDeviceHostFree()(buffer_);
+#endif
+ } else {
+ FDHostFree()(buffer_);
+ }
}
buffer_ = nullptr;
}
@@ -231,7 +255,6 @@ void FDTensor::CopyBuffer(void* dst, const void* src, size_t nbytes) {
#ifdef WITH_GPU
FDASSERT(cudaMemcpy(dst, src, nbytes, cudaMemcpyDeviceToDevice) == 0,
"[ERROR] Error occurs while copy memory from GPU to GPU");
-
#else
FDASSERT(false,
"The FastDeploy didn't compile under -DWITH_GPU=ON, so copying "
@@ -239,7 +262,19 @@ void FDTensor::CopyBuffer(void* dst, const void* src, size_t nbytes) {
"an unexpected problem happend.");
#endif
} else {
- std::memcpy(dst, src, nbytes);
+ if (is_pinned_memory) {
+#ifdef WITH_GPU
+ FDASSERT(cudaMemcpy(dst, src, nbytes, cudaMemcpyHostToHost) == 0,
+ "[ERROR] Error occurs while copy memory from host to host");
+#else
+ FDASSERT(false,
+ "The FastDeploy didn't compile under -DWITH_GPU=ON, so copying "
+ "gpu buffer is "
+ "an unexpected problem happend.");
+#endif
+ } else {
+ std::memcpy(dst, src, nbytes);
+ }
}
}
diff --git a/fastdeploy/core/fd_tensor.h b/fastdeploy/core/fd_tensor.h
index 7e8bb785199..1619fe27118 100644
--- a/fastdeploy/core/fd_tensor.h
+++ b/fastdeploy/core/fd_tensor.h
@@ -40,6 +40,10 @@ struct FASTDEPLOY_DECL FDTensor {
// so we can skip data transfer, which may improve the efficience
Device device = Device::CPU;
+ // Whether the data buffer is in pinned memory, which is allocated
+ // with cudaMallocHost()
+ bool is_pinned_memory = false;
+
// if the external data is not on CPU, we use this temporary buffer
// to transfer data to CPU at some cases we need to visit the
// other devices' data
diff --git a/fastdeploy/pybind/runtime.cc b/fastdeploy/pybind/runtime.cc
index 6d8eb78048a..70f9a5917b1 100755
--- a/fastdeploy/pybind/runtime.cc
+++ b/fastdeploy/pybind/runtime.cc
@@ -44,6 +44,8 @@ void BindRuntime(pybind11::module& m) {
.def("enable_trt_fp16", &RuntimeOption::EnableTrtFP16)
.def("disable_trt_fp16", &RuntimeOption::DisableTrtFP16)
.def("set_trt_cache_file", &RuntimeOption::SetTrtCacheFile)
+ .def("enable_pinned_memory", &RuntimeOption::EnablePinnedMemory)
+ .def("disable_pinned_memory", &RuntimeOption::DisablePinnedMemory)
.def("enable_paddle_trt_collect_shape", &RuntimeOption::EnablePaddleTrtCollectShape)
.def("disable_paddle_trt_collect_shape", &RuntimeOption::DisablePaddleTrtCollectShape)
.def_readwrite("model_file", &RuntimeOption::model_file)
@@ -200,6 +202,7 @@ void BindRuntime(pybind11::module& m) {
.def("numel", &FDTensor::Numel)
.def("nbytes", &FDTensor::Nbytes)
.def_readwrite("name", &FDTensor::name)
+ .def_readwrite("is_pinned_memory", &FDTensor::is_pinned_memory)
.def_readonly("shape", &FDTensor::shape)
.def_readonly("dtype", &FDTensor::dtype)
.def_readonly("device", &FDTensor::device);
diff --git a/fastdeploy/runtime.cc b/fastdeploy/runtime.cc
index 0877402d727..5037dc1206d 100755
--- a/fastdeploy/runtime.cc
+++ b/fastdeploy/runtime.cc
@@ -356,6 +356,10 @@ void RuntimeOption::EnableTrtFP16() { trt_enable_fp16 = true; }
void RuntimeOption::DisableTrtFP16() { trt_enable_fp16 = false; }
+void RuntimeOption::EnablePinnedMemory() { enable_pinned_memory = true; }
+
+void RuntimeOption::DisablePinnedMemory() { enable_pinned_memory = false; }
+
void RuntimeOption::SetTrtCacheFile(const std::string& cache_file_path) {
trt_serialize_file = cache_file_path;
}
@@ -503,6 +507,7 @@ void Runtime::CreatePaddleBackend() {
pd_option.gpu_id = option.device_id;
pd_option.delete_pass_names = option.pd_delete_pass_names;
pd_option.cpu_thread_num = option.cpu_thread_num;
+ pd_option.enable_pinned_memory = option.enable_pinned_memory;
#ifdef ENABLE_TRT_BACKEND
if (pd_option.use_gpu && option.pd_enable_trt) {
pd_option.enable_trt = true;
@@ -516,6 +521,7 @@ void Runtime::CreatePaddleBackend() {
trt_option.min_shape = option.trt_min_shape;
trt_option.opt_shape = option.trt_opt_shape;
trt_option.serialize_file = option.trt_serialize_file;
+ trt_option.enable_pinned_memory = option.enable_pinned_memory;
pd_option.trt_option = trt_option;
}
#endif
@@ -606,6 +612,7 @@ void Runtime::CreateTrtBackend() {
trt_option.min_shape = option.trt_min_shape;
trt_option.opt_shape = option.trt_opt_shape;
trt_option.serialize_file = option.trt_serialize_file;
+ trt_option.enable_pinned_memory = option.enable_pinned_memory;
// TODO(jiangjiajun): inside usage, maybe remove this later
trt_option.remove_multiclass_nms_ = option.remove_multiclass_nms_;
diff --git a/fastdeploy/runtime.h b/fastdeploy/runtime.h
index 32ad1615c76..021103cb21f 100755
--- a/fastdeploy/runtime.h
+++ b/fastdeploy/runtime.h
@@ -204,6 +204,15 @@ struct FASTDEPLOY_DECL RuntimeOption {
*/
void SetTrtCacheFile(const std::string& cache_file_path);
+ /**
+ * @brief Enable pinned memory. Pinned memory can be utilized to speedup the data transfer between CPU and GPU. Currently it's only suppurted in TRT backend and Paddle Inference backend.
+ */
+ void EnablePinnedMemory();
+
+ /**
+ * @brief Disable pinned memory
+ */
+ void DisablePinnedMemory();
/**
* @brief Enable to collect shape in paddle trt backend
@@ -223,6 +232,8 @@ struct FASTDEPLOY_DECL RuntimeOption {
Device device = Device::CPU;
+ bool enable_pinned_memory = false;
+
// ======Only for ORT Backend========
// -1 means use default value by ort
// 0: ORT_DISABLE_ALL 1: ORT_ENABLE_BASIC 2: ORT_ENABLE_EXTENDED 3:
diff --git a/python/fastdeploy/runtime.py b/python/fastdeploy/runtime.py
index 90e64d4005c..61d1039318b 100755
--- a/python/fastdeploy/runtime.py
+++ b/python/fastdeploy/runtime.py
@@ -319,6 +319,16 @@ def disable_trt_fp16(self):
"""
return self._option.disable_trt_fp16()
+ def enable_pinned_memory(self):
+ """Enable pinned memory. Pinned memory can be utilized to speedup the data transfer between CPU and GPU. Currently it's only suppurted in TRT backend and Paddle Inference backend.
+ """
+ return self._option.enable_pinned_memory()
+
+ def disable_pinned_memory(self):
+ """Disable pinned memory.
+ """
+ return self._option.disable_pinned_memory()
+
def enable_paddle_to_trt(self):
"""While using TensorRT backend, enable_paddle_to_trt() will change to use Paddle Inference backend, and use its integrated TensorRT instead.
"""
diff --git a/tests/release_task/compare_with_gt.py b/tests/release_task/compare_with_gt.py
index 2770fe18212..d248b1b1810 100644
--- a/tests/release_task/compare_with_gt.py
+++ b/tests/release_task/compare_with_gt.py
@@ -1,6 +1,39 @@
import numpy as np
import re
+diff_score_threshold = {
+ "linux-x64": {
+ "label_diff": 0,
+ "score_diff": 1e-4,
+ "boxes_diff_ratio": 1e-4,
+ "boxes_diff": 1e-3
+ },
+ "linux-aarch64": {
+ "label_diff": 0,
+ "score_diff": 1e-4,
+ "boxes_diff_ratio": 1e-4,
+ "boxes_diff": 1e-3
+ },
+ "osx-x86_64": {
+ "label_diff": 0,
+ "score_diff": 1e-4,
+ "boxes_diff_ratio": 2e-4,
+ "boxes_diff": 1e-3
+ },
+ "osx-arm64": {
+ "label_diff": 0,
+ "score_diff": 1e-4,
+ "boxes_diff_ratio": 2e-4,
+ "boxes_diff": 1e-3
+ },
+ "win-x64": {
+ "label_diff": 0,
+ "score_diff": 5e-4,
+ "boxes_diff_ratio": 1e-3,
+ "boxes_diff": 1e-3
+ }
+}
+
def parse_arguments():
import argparse
@@ -59,6 +92,7 @@ def save_numpy_result(file_path, error_msg):
def check_result(gt_result, infer_result, args):
+ platform = args.platform
if len(gt_result) != len(infer_result):
infer_result = infer_result[-len(gt_result):]
diff = np.abs(gt_result - infer_result)
@@ -68,17 +102,19 @@ def check_result(gt_result, infer_result, args):
boxes_diff_ratio = boxes_diff / (infer_result[:, :-2] + 1e-6)
is_diff = False
backend = args.result_path.split(".")[0]
- if (label_diff > 0).any():
+ if (label_diff > diff_score_threshold[platform]["label_diff"]).any():
print(args.platform, args.device, "label diff ", label_diff)
is_diff = True
label_diff_bool_file = args.platform + "_" + backend + "_" + "label_diff_bool.txt"
save_numpy_result(label_diff_bool_file, label_diff > 0)
- if (score_diff > 2e-4).any():
+ if (score_diff > diff_score_threshold[platform]["score_diff"]).any():
print(args.platform, args.device, "score diff ", score_diff)
is_diff = True
score_diff_bool_file = args.platform + "_" + backend + "_" + "score_diff_bool.txt"
save_numpy_result(score_diff_bool_file, score_diff > 1e-4)
- if (boxes_diff_ratio > 1e-4).any() and (boxes_diff > 1e-3).any():
+ if (boxes_diff_ratio > diff_score_threshold[platform]["boxes_diff_ratio"]
+ ).any() and (
+ boxes_diff > diff_score_threshold[platform]["boxes_diff"]).any():
print(args.platform, args.device, "boxes diff ", boxes_diff_ratio)
is_diff = True
boxes_diff_bool_file = args.platform + "_" + backend + "_" + "boxes_diff_bool.txt"
diff --git a/tests/release_task/cpp_run.bat b/tests/release_task/cpp_run.bat
index f79a0c01e53..2c8a8aed628 100644
--- a/tests/release_task/cpp_run.bat
+++ b/tests/release_task/cpp_run.bat
@@ -17,7 +17,7 @@ if "%DEVICE%" == "gpu" (
set CPP_FASTDEPLOY_PACKAGE=fastdeploy-%PLATFORM%-%DEVICE%-%VERSION%
set RUN_CASES=ort paddle trt
) else (
- set CPP_FASTDEPLOY_PACKAGE=fastdeploy-python
+ set CPP_FASTDEPLOY_PACKAGE=fastdeploy-%PLATFORM%-%VERSION%
set RUN_CASES=ort paddle openvino
)
@@ -36,7 +36,7 @@ set COMPARE_SHELL=%CURRENT_DIR%\compare_with_gt.py
python -c "from download import *; download_and_decompress('https://fastdeploy.bj.bcebos.com/dev/cpp/%CPP_FASTDEPLOY_PACKAGE%.zip', './')"
mkdir build && cd build
-cmake .. -G "Visual Studio 16 2019" -A x64 -DFASTDEPLOY_INSTALL_DIR=%cd%\..\%CPP_FASTDEPLOY_PACKAGE% -DCUDA_DIRECTORY="C:/Program Files/NVIDIA GPU Computing Toolkit/CUDA/v11.2" -DCMAKE_CXX_COMPILER=%CMAKE_CXX_COMPILER%
+cmake .. -G "Visual Studio 16 2019" -A x64 -DFASTDEPLOY_INSTALL_DIR=%cd%\..\%CPP_FASTDEPLOY_PACKAGE% -DCUDA_DIRECTORY="C:/Program Files/NVIDIA GPU Computing Toolkit/CUDA/v11.2"
msbuild infer_demo.sln /m:4 /p:Configuration=Release /p:Platform=x64
@@ -47,7 +47,6 @@ echo "FASTDEPLOY_HOME" %FASTDEPLOY_HOME%
copy /Y %FASTDEPLOY_HOME%\third_libs\install\onnxruntime\lib\onnxruntime* Release\
set PATH=%FASTDEPLOY_HOME%\lib;%PATH%
set PATH=%FASTDEPLOY_HOME%\third_libs\install\onnxruntime\lib;%PATH%
-set PATH=%FASTDEPLOY_HOME%\third_libs\install\opencv-win-x64-3.4.16\build\x64\vc15\bin;%PATH%
set PATH=%FASTDEPLOY_HOME%\third_libs\install\paddle_inference\paddle\lib;%PATH%
set PATH=%FASTDEPLOY_HOME%\third_libs\install\paddle_inference\third_party\install\mkldnn\lib;%PATH%
set PATH=%FASTDEPLOY_HOME%\third_libs\install\paddle_inference\third_party\install\mklml\lib;%PATH%
@@ -56,9 +55,9 @@ set PATH=%FASTDEPLOY_HOME%\third_libs\install\tensorrt\lib;%PATH%
set PATH=%FASTDEPLOY_HOME%\third_libs\install\faster_tokenizer\lib;%PATH%
set PATH=%FASTDEPLOY_HOME%\third_libs\install\faster_tokenizer\third_party\lib;%PATH%
set PATH=%FASTDEPLOY_HOME%\third_libs\install\yaml-cpp\lib;%PATH%
-set PATH=%FASTDEPLOY_HOME%\third_libs\install\openvino\bin;%PATH%
-set PATH=%FASTDEPLOY_HOME%\third_libs\install\openvino\3rdparty\tbb\bin;%PATH%
-
+set PATH=%FASTDEPLOY_HOME%\third_libs\install\opencv\build\x64\vc15\bin;%PATH%
+set PATH=%FASTDEPLOY_HOME%\third_libs\install\openvino\runtime\bin;%PATH%
+set PATH=%FASTDEPLOY_HOME%\third_libs\install\openvino\runtime\3rdparty\tbb\bin;%PATH%
echo "set path done"
cd %cd%\Release
for %%b in (%RUN_CASES%) do (
@@ -71,11 +70,9 @@ for %%b in (%RUN_CASES%) do (
if %%b == trt (
infer_ppyoloe_demo.exe --model_dir=%MODEL_PATH% --image_file=%IMAGE_PATH% --device=gpu --backend=%%b >> cpp_%%b_trt_result.txt
python %COMPARE_SHELL% --gt_path %GROUND_TRUTH_PATH% --result_path cpp_%%b_trt_result.txt --platform %PLATFORM% --device trt --conf_threshold 0.5
- ) else if %%b == ort (
+ ) else (
infer_ppyoloe_demo.exe --model_dir=%MODEL_PATH% --image_file=%IMAGE_PATH% --device=gpu --backend=%%b >> cpp_%%b_gpu_result.txt
python %COMPARE_SHELL% --gt_path %GROUND_TRUTH_PATH% --result_path cpp_%%b_gpu_result.txt --platform %PLATFORM% --device gpu --conf_threshold 0.5
- ) else if %%b == paddle (
- echo "Temporarily skip paddle gpu case in windows for Inaccurate inference precision"
)
)
)
diff --git a/tests/release_task/cpp_run.sh b/tests/release_task/cpp_run.sh
index 0c14904ca71..21f1df8bfb5 100644
--- a/tests/release_task/cpp_run.sh
+++ b/tests/release_task/cpp_run.sh
@@ -12,7 +12,8 @@ fi
echo $CPP_FASTDEPLOY_PACKAGE
LINUX_X64_GPU_CASE=('ort' 'paddle' 'trt')
LINUX_X64_CPU_CASE=('ort' 'paddle' 'openvino')
-LINUX_AARCH_CPU_CASE=('ort' 'openvino')
+#LINUX_AARCH_CPU_CASE=('ort' 'openvino')
+LINUX_AARCH_CPU_CASE=('ort')
MACOS_INTEL_CPU_CASE=('ort' 'paddle' 'openvino')
MACOS_ARM64_CPU_CASE=('default')
wget -q https://bj.bcebos.com/paddlehub/fastdeploy/ppyoloe_crn_l_300e_coco.tgz
@@ -25,6 +26,7 @@ GROUND_TRUTH_PATH=$CURRENT_DIR/release_task_groud_truth_result.txt
COMPARE_SHELL=$CURRENT_DIR/compare_with_gt.py
RUN_CASE=()
+CONF_THRESHOLD=0
if [ "$DEVICE" = "gpu" ] && [ "$PLATFORM" = "linux-x64" ];then
RUN_CASE=(${LINUX_X64_GPU_CASE[*]})
elif [ "$DEVICE" = "cpu" ] && [ "$PLATFORM" = "linux-x64" ];then
@@ -35,6 +37,7 @@ elif [ "$DEVICE" = "cpu" ] && [ "$PLATFORM" = "osx-x86_64" ];then
RUN_CASE=(${MACOS_INTEL_CPU_CASE[*]})
elif [ "$DEVICE" = "cpu" ] && [ "$PLATFORM" = "osx-arm64" ];then
RUN_CASE=(${MACOS_ARM64_CPU_CASE[*]})
+ CONF_THRESHOLD=0.5
fi
case_number=${#RUN_CASE[@]}
@@ -52,16 +55,16 @@ do
echo "Cpp Backend:" $backend
if [ "$backend" != "trt" ];then
./infer_ppyoloe_demo --model_dir=$MODEL_PATH --image_file=$IMAGE_PATH --device=cpu --backend=$backend >> cpp_cpu_result.txt
- python $COMPARE_SHELL --gt_path $GROUND_TRUTH_PATH --result_path cpp_cpu_result.txt --platform $PLATFORM --device cpu
+ python $COMPARE_SHELL --gt_path $GROUND_TRUTH_PATH --result_path cpp_cpu_result.txt --platform $PLATFORM --device cpu --conf_threshold $CONF_THRESHOLD
fi
if [ "$DEVICE" = "gpu" ];then
if [ "$backend" = "trt" ];then
./infer_ppyoloe_demo --model_dir=$MODEL_PATH --image_file=$IMAGE_PATH --device=gpu --backend=$backend >> cpp_trt_result.txt
- python $COMPARE_SHELL --gt_path $GROUND_TRUTH_PATH --result_path cpp_trt_result.txt --platform $PLATFORM --device trt
+ python $COMPARE_SHELL --gt_path $GROUND_TRUTH_PATH --result_path cpp_trt_result.txt --platform $PLATFORM --device trt --conf_threshold $CONF_THRESHOLD
else
./infer_ppyoloe_demo --model_dir=$MODEL_PATH --image_file=$IMAGE_PATH --device=gpu --backend=$backend >> cpp_gpu_result.txt
- python $COMPARE_SHELL --gt_path $GROUND_TRUTH_PATH --result_path cpp_gpu_result.txt --platform $PLATFORM --device gpu
+ python $COMPARE_SHELL --gt_path $GROUND_TRUTH_PATH --result_path cpp_gpu_result.txt --platform $PLATFORM --device gpu --conf_threshold $CONF_THRESHOLD
fi
fi
done
@@ -78,4 +81,3 @@ else
cat $res_file
exit -1
fi
-
diff --git a/tests/release_task/py_run.bat b/tests/release_task/py_run.bat
index b2e179d1b6c..5be6475494a 100644
--- a/tests/release_task/py_run.bat
+++ b/tests/release_task/py_run.bat
@@ -46,12 +46,10 @@ for %%b in (%RUN_CASES%) do (
if %%b == trt (
python infer_ppyoloe.py --model_dir=%MODEL_PATH% --image=%IMAGE_PATH% --device=gpu --backend=%%b >> py_%%b_trt_result.txt
python %COMPARE_SHELL% --gt_path %GROUND_TRUTH_PATH% --result_path py_%%b_trt_result.txt --platform %PLATFORM% --device trt --conf_threshold 0.5
- ) else if %%b == ort (
+ ) else (
python infer_ppyoloe.py --model_dir=%MODEL_PATH% --image=%IMAGE_PATH% --device=gpu --backend=%%b >> py_%%b_gpu_result.txt
python %COMPARE_SHELL% --gt_path %GROUND_TRUTH_PATH% --result_path py_%%b_gpu_result.txt --platform %PLATFORM% --device gpu --conf_threshold 0.5
- ) else if %%b == paddle (
- echo "Temporarily skip paddle gpu case in windows for Inaccurate inference precision"
- )
+ )
)
)
diff --git a/tests/release_task/py_run.sh b/tests/release_task/py_run.sh
index 2856bc4da3c..36624246306 100644
--- a/tests/release_task/py_run.sh
+++ b/tests/release_task/py_run.sh
@@ -12,7 +12,8 @@ fi
echo $PY_FASTDEPLOY_PACKAGE
LINUX_X64_GPU_CASE=('ort' 'paddle' 'trt')
LINUX_X64_CPU_CASE=('ort' 'paddle' 'openvino')
-LINUX_AARCH_CPU_CASE=('ort' 'openvino')
+#LINUX_AARCH_CPU_CASE=('ort' 'openvino')
+LINUX_AARCH_CPU_CASE=('ort')
MACOS_INTEL_CPU_CASE=('ort' 'paddle' 'openvino')
MACOS_ARM64_CPU_CASE=('default')
wget -q https://bj.bcebos.com/paddlehub/fastdeploy/ppyoloe_crn_l_300e_coco.tgz
@@ -60,7 +61,7 @@ do
fi
done
-ret=$?
+ret=$?
res_file="result.txt"
if [ ! -f $res_file ];then
diff --git a/tools/quantization/README.md b/tools/quantization/README.md
index 2bf2da7f220..4459d526d2d 100644
--- a/tools/quantization/README.md
+++ b/tools/quantization/README.md
@@ -47,6 +47,7 @@ tar -xvf COCO_val_320.tar.gz
```shell
fastdeploy_quant --config_path=./configs/detection/yolov5s_quant.yaml --method='PTQ' --save_dir='./yolov5s_ptq_model/'
```
+【说明】离线量化(训练后量化):post-training quantization,缩写是PTQ
##### 3.参数说明